 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adversarial Training for Infrared-colour Person Re-Identification
Mar 09, 2020
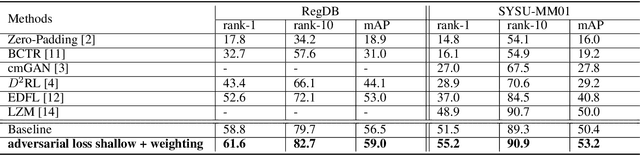

Person re-identification (re-ID) is a very active area of research in computer vision, due to the role it plays in video surveillance. Currently, most methods only address the task of matching between colour images. However, in poorly-lit environments CCTV cameras switch to infrared imaging, hence developing a system which can correctly perform matching between infrared and colour images is a necessity. In this paper, we propose a part-feature extraction network to better focus on subtle, unique signatures on the person which are visible across both infrared and colour modalities. To train the model we propose a novel variant of the domain adversarial feature-learning framework. Through extensive experimentation, we show that our approach outperforms state-of-the-art methods.
Person Re-identification with Bias-controlled Adversarial Training
Mar 30, 2019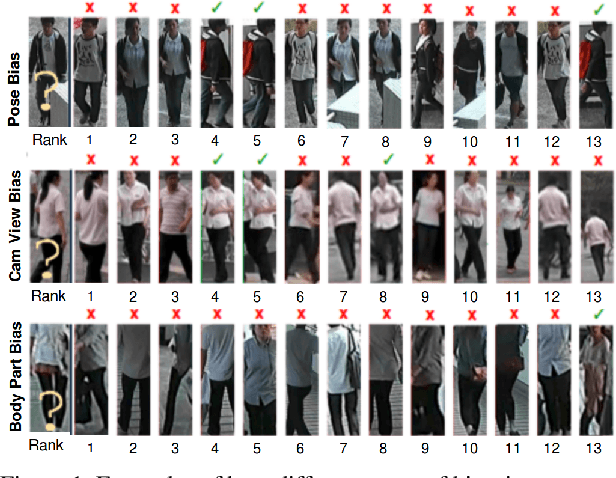
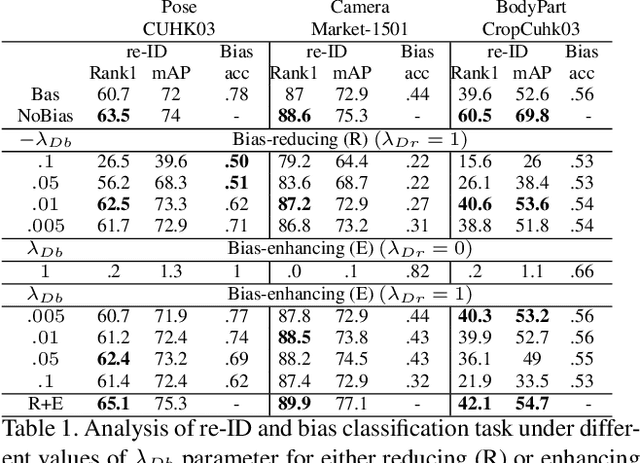
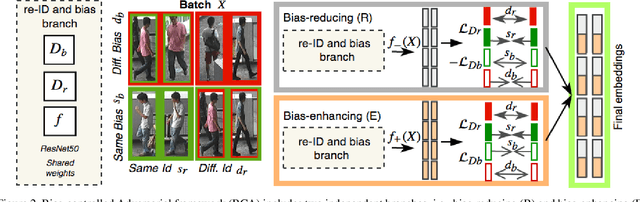
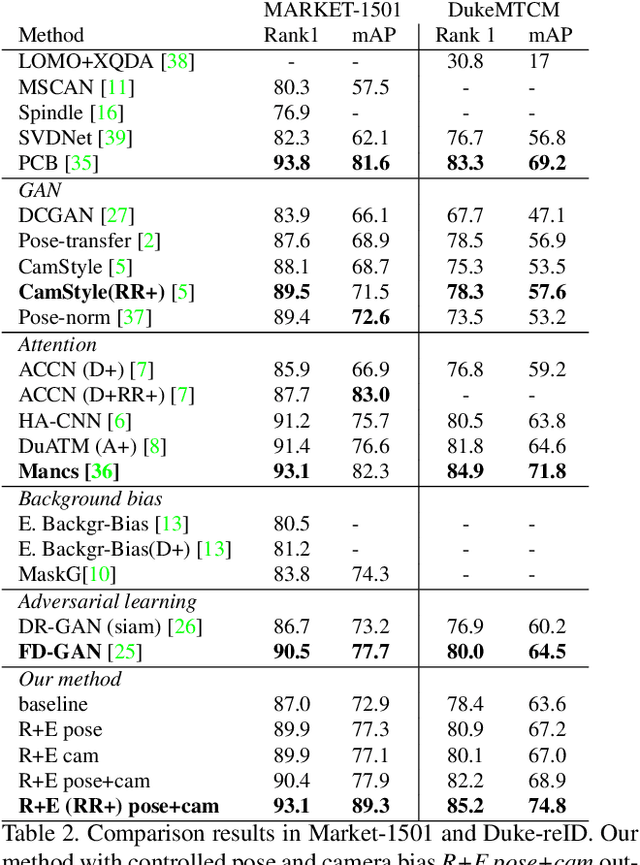
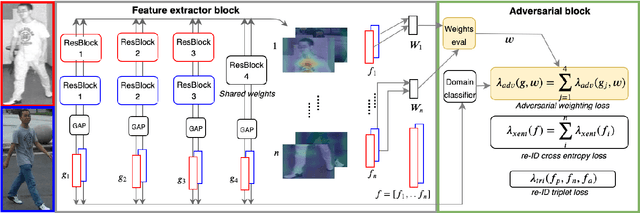
Inspired by the effectiveness of adversarial training in the area of Generative Adversarial Networks we present a new approach for learning feature representations in person re-identification. We investigate different types of bias that typically occur in re-ID scenarios, i.e., pose, body part and camera view, and propose a general approach to address them. We introduce an adversarial strategy for controlling bias, named Bias-controlled Adversarial framework (BCA), with two complementary branches to reduce or to enhance bias-related features. The results and comparison to the state of the art on different benchmarks show that our framework is an effective strategy for person re-identification. The performance improvements are in both full and partial views of persons.
Partial Person Re-identification with Alignment and Hallucination
Jul 24, 2018
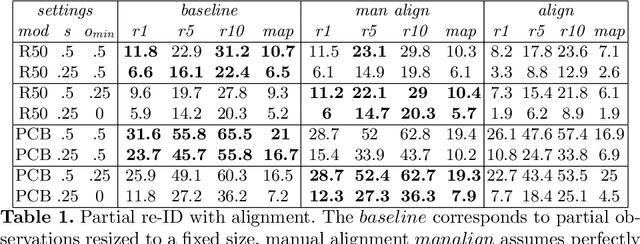
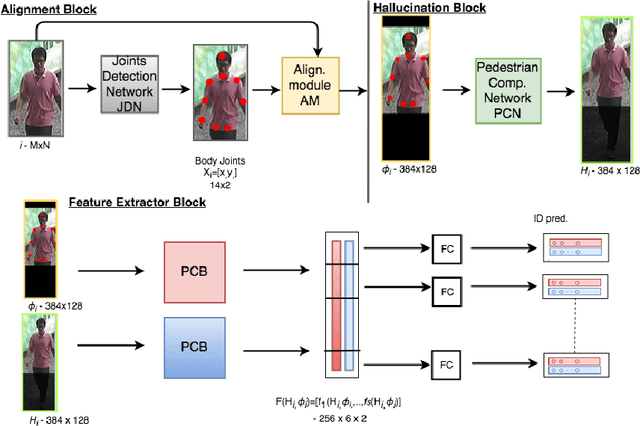
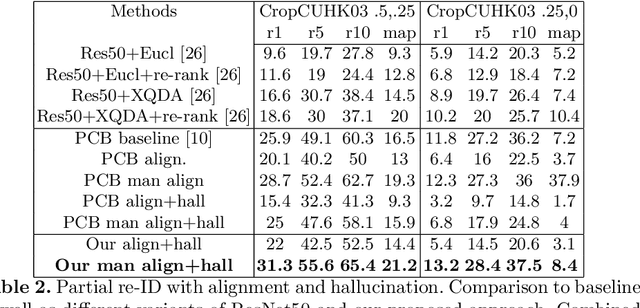
Partial person re-identification involves matching pedestrian frames where only a part of a body is visible in corresponding images. This reflects practical CCTV surveillance scenario, where full person views are often not available. Missing body parts make the comparison very challenging due to significant misalignment and varying scale of the views. We propose Partial Matching Net (PMN) that detects body joints, aligns partial views and hallucinates the missing parts based on the information present in the frame and a learned model of a person. The aligned and reconstructed views are then combined into a joint representation and used for matching images. We evaluate our approach and compare to other methods on three different datasets, demonstrating significant improvements.