 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning of Minimax Risk Classifiers in High Dimensions
Jun 11, 2023High-dimensional data is common in multiple areas, such as health care and genomics, where the number of features can be tens of thousands. In such scenarios, the large number of features often leads to inefficient learning. Constraint generation methods have recently enabled efficient learning of L1-regularized support vector machines (SVMs). In this paper, we leverage such methods to obtain an efficient learning algorithm for the recently proposed minimax risk classifiers (MRCs). The proposed iterative algorithm also provides a sequence of worst-case error probabilities and performs feature selection. Experiments on multiple high-dimensional datasets show that the proposed algorithm is efficient in high-dimensional scenarios. In addition, the worst-case error probability provides useful information about the classifier performance, and the features selected by the algorithm are competitive with the state-of-the-art.
A Deep Learning Approach for Generating Soft Range Information from RF Data
May 23, 2023



Radio frequency (RF)-based techniques are widely adopted for indoor localization despite the challenges in extracting sufficient information from measurements. Soft range information (SRI) offers a promising alternative for highly accurate localization that gives all probable range values rather than a single estimate of distance. We propose a deep learning approach to generate accurate SRI from RF measurements. In particular, the proposed approach is implemented by a network with two neural modules and conducts the generation directly from raw data. Extensive experiments on a case study with two public datasets are conducted to quantify the efficiency in different indoor localization tasks. The results show that the proposed approach can generate highly accurate SRI, and significantly outperforms conventional techniques in both non-line-of-sight (NLOS) detection and ranging error mitigation.
* Published in: 2021 IEEE Globecom Workshops (GC Wkshps)
Deep GEM-Based Network for Weakly Supervised UWB Ranging Error Mitigation
May 23, 2023Ultra-wideband (UWB)-based techniques, while becoming mainstream approaches for high-accurate positioning, tend to be challenged by ranging bias in harsh environments. The emerging learning-based methods for error mitigation have shown great performance improvement via exploiting high semantic features from raw data. However, these methods rely heavily on fully labeled data, leading to a high cost for data acquisition. We present a learning framework based on weak supervision for UWB ranging error mitigation. Specifically, we propose a deep learning method based on the generalized expectation-maximization (GEM) algorithm for robust UWB ranging error mitigation under weak supervision. Such method integrate probabilistic modeling into the deep learning scheme, and adopt weakly supervised labels as prior information. Extensive experiments in various supervision scenarios illustrate the superiority of the proposed method.
* 6 pages, 4 figures, Published in: MILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM)
Variational Bayesian Framework for Advanced Image Generation with Domain-Related Variables
May 23, 2023


Deep generative models (DGMs) and their conditional counterparts provide a powerful ability for general-purpose generative modeling of data distributions. However, it remains challenging for existing methods to address advanced conditional generative problems without annotations, which can enable multiple applications like image-to-image translation and image editing. We present a unified Bayesian framework for such problems, which introduces an inference stage on latent variables within the learning process. In particular, we propose a variational Bayesian image translation network (VBITN) that enables multiple image translation and editing tasks. Comprehensive experiments show the effectiveness of our method on unsupervised image-to-image translation, and demonstrate the novel advanced capabilities for semantic editing and mixed domain translation.
* 5 pages, 2 figures,
Double-Weighting for Covariate Shift Adaptation
May 15, 2023



Supervised learning is often affected by a covariate shift in which the marginal distributions of instances (covariates $x$) of training and testing samples $\mathrm{p}_\text{tr}(x)$ and $\mathrm{p}_\text{te}(x)$ are different but the label conditionals coincide. Existing approaches address such covariate shift by either using the ratio $\mathrm{p}_\text{te}(x)/\mathrm{p}_\text{tr}(x)$ to weight training samples (reweighting methods) or using the ratio $\mathrm{p}_\text{tr}(x)/\mathrm{p}_\text{te}(x)$ to weight testing samples (robust methods). However, the performance of such approaches can be poor under support mismatch or when the above ratios take large values. We propose a minimax risk classification (MRC) approach for covariate shift adaptation that avoids such limitations by weighting both training and testing samples. In addition, we develop effective techniques that obtain both sets of weights and generalize the conventional kernel mean matching method. We provide novel generalization bounds for our method that show a significant increase in the effective sample size compared with reweighted methods. The proposed method also achieves enhanced classification performance in both synthetic and empirical experiments.
Minimax Classification under Concept Drift with Multidimensional Adaptation and Performance Guarantees
May 31, 2022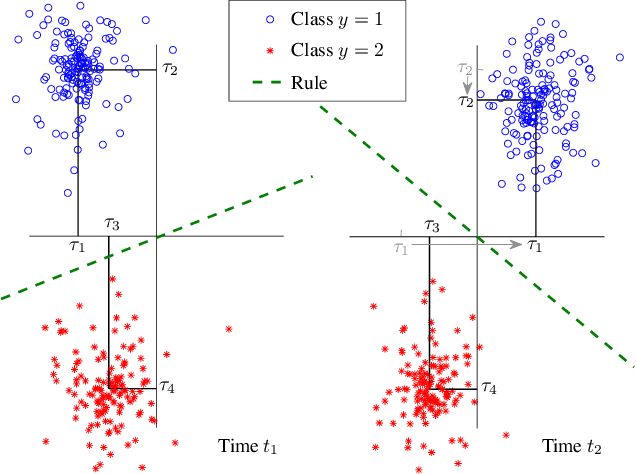
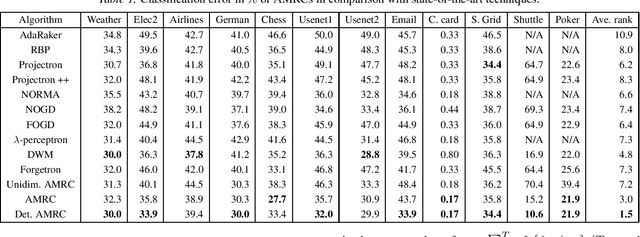
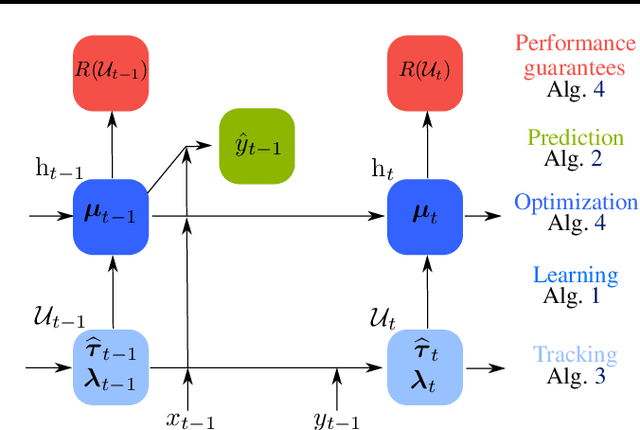
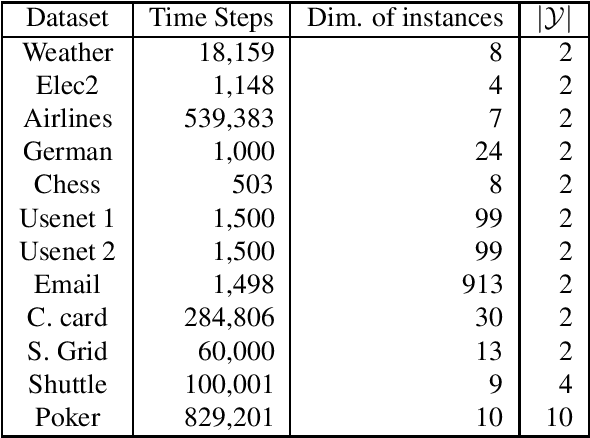
The statistical characteristics of instance-label pairs often change with time in practical scenarios of supervised classification. Conventional learning techniques adapt to such concept drift accounting for a scalar rate of change by means of a carefully chosen learning rate, forgetting factor, or window size. However, the time changes in common scenarios are multidimensional, i.e., different statistical characteristics often change in a different manner. This paper presents adaptive minimax risk classifiers (AMRCs) that account for multidimensional time changes by means of a multivariate and high-order tracking of the time-varying underlying distribution. In addition, differently from conventional techniques, AMRCs can provide computable tight performance guarantees. Experiments on multiple benchmark datasets show the classification improvement of AMRCs compared to the state-of-the-art and the reliability of the presented performance guarantees.
Minimax risk classifiers with 0-1 loss
Jan 17, 2022
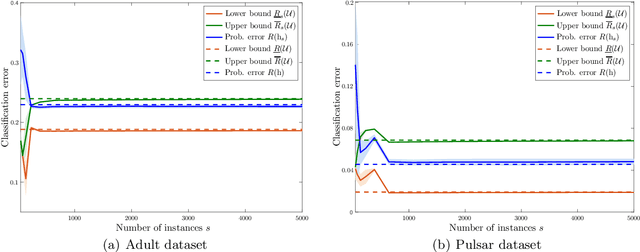
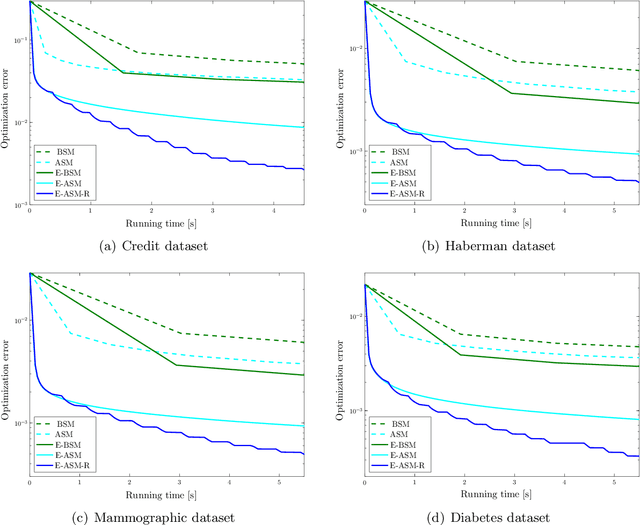
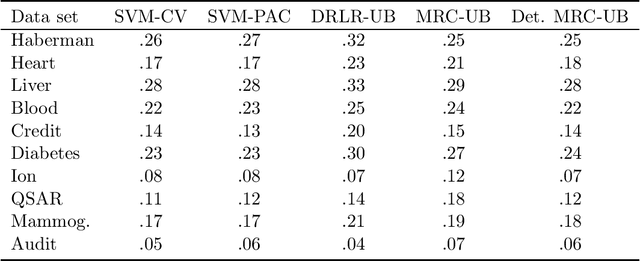
Supervised classification techniques use training samples to learn a classification rule with small expected 0-1-loss (error probability). Conventional methods enable tractable learning and provide out-of-sample generalization by using surrogate losses instead of the 0-1-loss and considering specific families of rules (hypothesis classes). This paper presents minimax risk classifiers (MRCs) that minimize the worst-case 0-1-loss over general classification rules and provide tight performance guarantees at learning. We show that MRCs are strongly universally consistent using feature mappings given by characteristic kernels. The paper also proposes efficient optimization techniques for MRC learning and shows that the methods presented can provide accurate classification together with tight performance guarantees
MRCpy: A Library for Minimax Risk Classifiers
Aug 04, 2021
Existing libraries for supervised classification implement techniques that are based on empirical risk minimization and utilize surrogate losses. We present MRCpy library that implements minimax risk classifiers (MRCs) that are based on robust risk minimization and can utilize 0-1-loss. Such techniques give rise to a manifold of classification methods that can provide tight bounds on the expected loss. MRCpy provides a unified interface for different variants of MRCs and follows the standards of popular Python libraries. The presented library also provides implementation for popular techniques that can be seen as MRCs such as L1-regularized logistic regression, zero-one adversarial, and maximum entropy machines. In addition, MRCpy implements recent feature mappings such as Fourier, ReLU, and threshold features. The library is designed with an object-oriented approach that facilitates collaborators and users.
Probabilistic Load Forecasting Based on Adaptive Online Learning
Nov 30, 2020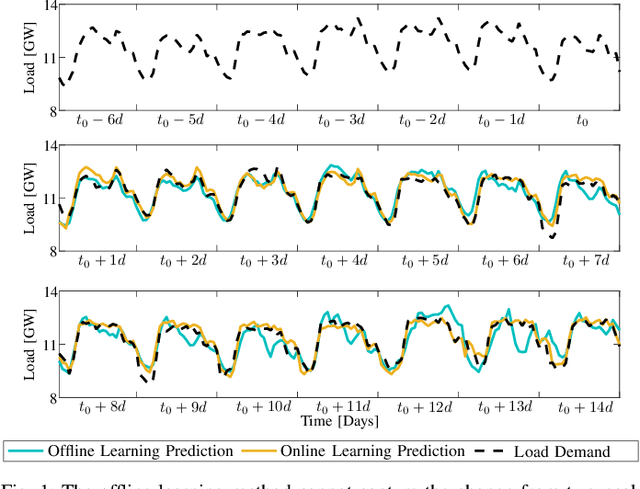
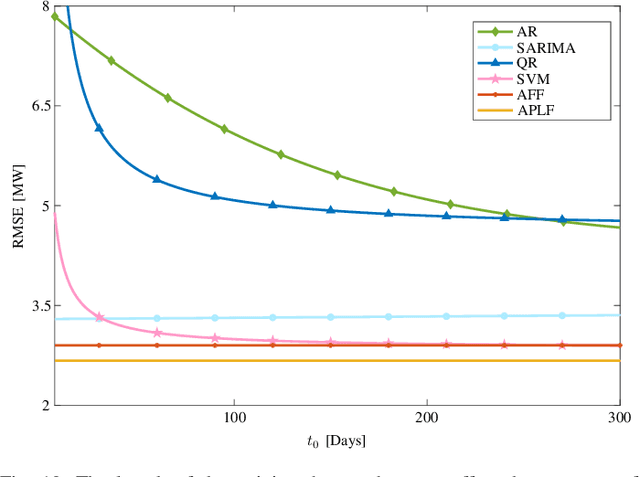
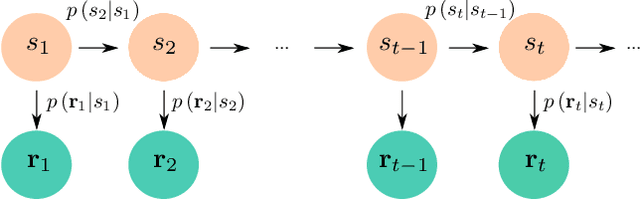
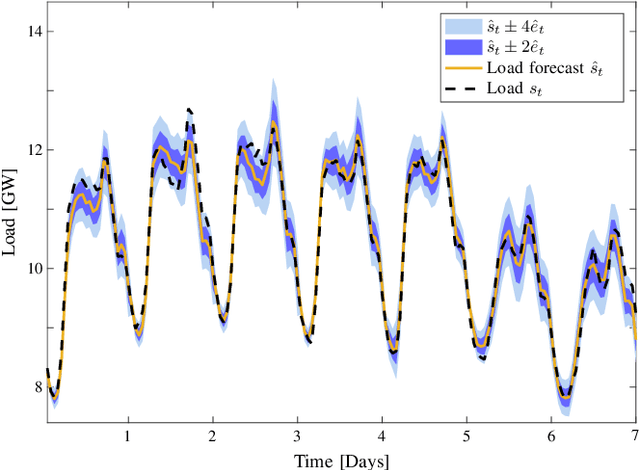
Load forecasting is crucial for multiple energy management tasks such as scheduling generation capacity, planning supply and demand, and minimizing energy trade costs. Such relevance has increased even more in recent years due to the integration of renewable energies, electric cars, and microgrids. Conventional load forecasting techniques obtain single-value load forecasts by exploiting consumption patterns of past load demand. However, such techniques cannot assess intrinsic uncertainties in load demand, and cannot capture dynamic changes in consumption patterns. To address these problems, this paper presents a method for probabilistic load forecasting based on the adaptive online learning of hidden Markov models. We propose learning and forecasting techniques with theoretical guarantees, and experimentally assess their performance in multiple scenarios. In particular, we develop adaptive online learning techniques that update model parameters recursively, and sequential prediction techniques that obtain probabilistic forecasts using the most recent parameters. The performance of the method is evaluated using multiple datasets corresponding with regions that have different sizes and display assorted time-varying consumption patterns. The results show that the proposed method can significantly improve the performance of existing techniques for a wide range of scenarios.
Minimax Classification with 0-1 Loss and Performance Guarantees
Oct 15, 2020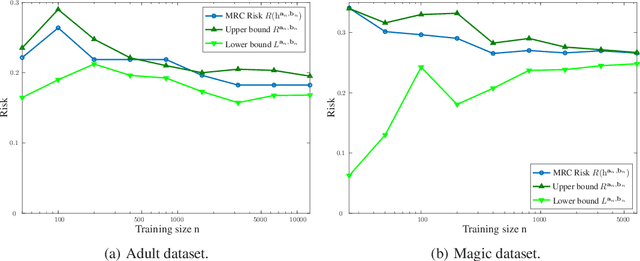
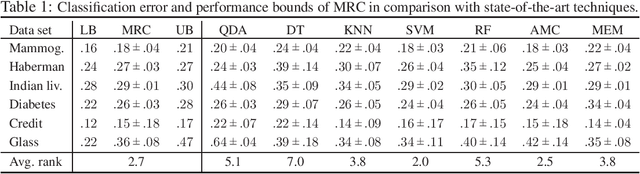
Supervised classification techniques use training samples to find classification rules with small expected 0-1 loss. Conventional methods achieve efficient learning and out-of-sample generalization by minimizing surrogate losses over specific families of rules. This paper presents minimax risk classifiers (MRCs) that do not rely on a choice of surrogate loss and family of rules. MRCs achieve efficient learning and out-of-sample generalization by minimizing worst-case expected 0-1 loss w.r.t. uncertainty sets that are defined by linear constraints and include the true underlying distribution. In addition, MRCs' learning stage provides performance guarantees as lower and upper tight bounds for expected 0-1 loss. We also present MRCs' finite-sample generalization bounds in terms of training size and smallest minimax risk, and show their competitive classification performance w.r.t. state-of-the-art techniques using benchmark datasets.