 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Trained Observer Control for Bearings-Only Tracking
May 04, 2026This paper develops a deep reinforcement learning based observer control policy for autonomous bearings-only tracking of a moving target. The observer manoeuvre problem is formulated as a belief Markov decision process, where the belief state is represented by the posterior of a cubature Kalman filter (CKF). The reward function is designed to address two conflicting objectives: minimising the absolute target position estimation error (Euclidean distance) and maintaining CKF estimation consistency (Mahalanobis distance). The reward is formulated as a geometric interpolation between the two objectives on the Pareto front, parametrised by a weighting factor $β\in [0,1]$. The policy is implemented as a deep Q-network (DQN) trained over 50,000 episodes. Performance is evaluated over 5,000 Monte Carlo episodes and compared against two baselines: the perpendicular-to-bearing heuristic and the D-optimal Fisher information maximisation criterion. The results show that the DQN policy at $β= 0.7$ achieves the best trade-off between accuracy and robustness: it matches the information-theoretic baseline on mean tracking accuracy while reducing the worst-case error by nearly a factor of ten, owing to the implicit filter-consistency regularisation provided by the Mahalanobis term in the reward.
Credal Valuation Networks for Machine Reasoning Under Uncertainty
Aug 04, 2022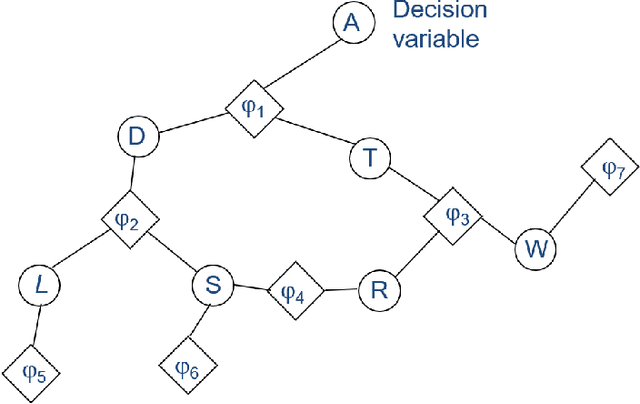
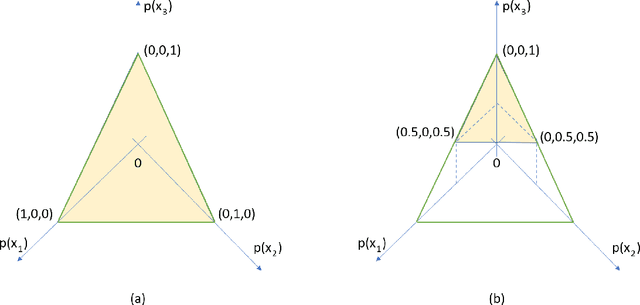
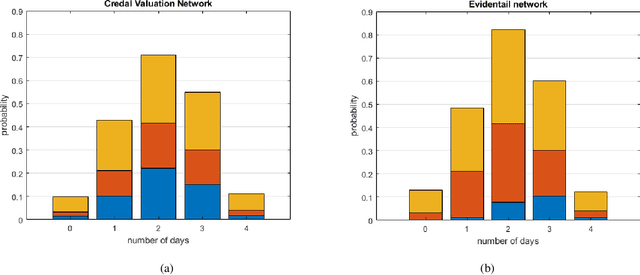
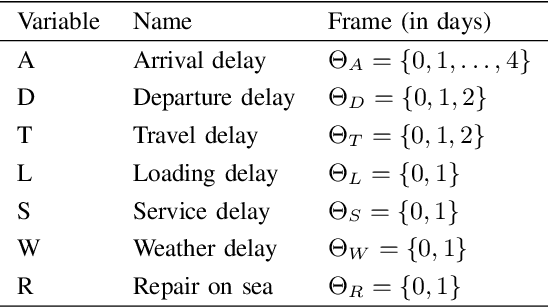
Contemporary undertakings provide limitless opportunities for widespread application of machine reasoning and artificial intelligence in situations characterised by uncertainty, hostility and sheer volume of data. The paper develops a valuation network as a graphical system for higher-level fusion and reasoning under uncertainty in support of the human operators. Valuations, which are mathematical representation of (uncertain) knowledge and collected data, are expressed as credal sets, defined as coherent interval probabilities in the framework of imprecise probability theory. The basic operations with such credal sets, combination and marginalisation, are defined to satisfy the axioms of a valuation algebra. A practical implementation of the credal valuation network is discussed and its utility demonstrated on a small scale example.