 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Processing Unit (QPU) processing time Prediction with Machine Learning
Oct 23, 2025This paper explores the application of machine learning (ML) techniques in predicting the QPU processing time of quantum jobs. By leveraging ML algorithms, this study introduces predictive models that are designed to enhance operational efficiency in quantum computing systems. Using a dataset of about 150,000 jobs that follow the IBM Quantum schema, we employ ML methods based on Gradient-Boosting (LightGBM) to predict the QPU processing times, incorporating data preprocessing methods to improve model accuracy. The results demonstrate the effectiveness of ML in forecasting quantum jobs. This improvement can have implications on improving resource management and scheduling within quantum computing frameworks. This research not only highlights the potential of ML in refining quantum job predictions but also sets a foundation for integrating AI-driven tools in advanced quantum computing operations.
AI methods for approximate compiling of unitaries
Jul 30, 2024



This paper explores artificial intelligence (AI) methods for the approximate compiling of unitaries, focusing on the use of fixed two-qubit gates and arbitrary single-qubit rotations typical in superconducting hardware. Our approach involves three main stages: identifying an initial template that approximates the target unitary, predicting initial parameters for this template, and refining these parameters to maximize the fidelity of the circuit. We propose AI-driven approaches for the first two stages, with a deep learning model that suggests initial templates and an autoencoder-like model that suggests parameter values, which are refined through gradient descent to achieve the desired fidelity. We demonstrate the method on 2 and 3-qubit unitaries, showcasing promising improvements over exhaustive search and random parameter initialization. The results highlight the potential of AI to enhance the transpiling process, supporting more efficient quantum computations on current and future quantum hardware.
Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models
Jun 20, 2024Quantum programs are typically developed using quantum Software Development Kits (SDKs). The rapid advancement of quantum computing necessitates new tools to streamline this development process, and one such tool could be Generative Artificial intelligence (GenAI). In this study, we introduce and use the Qiskit HumanEval dataset, a hand-curated collection of tasks designed to benchmark the ability of Large Language Models (LLMs) to produce quantum code using Qiskit - a quantum SDK. This dataset consists of more than 100 quantum computing tasks, each accompanied by a prompt, a canonical solution, a comprehensive test case, and a difficulty scale to evaluate the correctness of the generated solutions. We systematically assess the performance of a set of LLMs against the Qiskit HumanEval dataset's tasks and focus on the models ability in producing executable quantum code. Our findings not only demonstrate the feasibility of using LLMs for generating quantum code but also establish a new benchmark for ongoing advancements in the field and encourage further exploration and development of GenAI-driven tools for quantum code generation.
Qiskit Code Assistant: Training LLMs for generating Quantum Computing Code
May 29, 2024


Code Large Language Models (Code LLMs) have emerged as powerful tools, revolutionizing the software development landscape by automating the coding process and reducing time and effort required to build applications. This paper focuses on training Code LLMs to specialize in the field of quantum computing. We begin by discussing the unique needs of quantum computing programming, which differ significantly from classical programming approaches or languages. A Code LLM specializing in quantum computing requires a foundational understanding of quantum computing and quantum information theory. However, the scarcity of available quantum code examples and the rapidly evolving field, which necessitates continuous dataset updates, present significant challenges. Moreover, we discuss our work on training Code LLMs to produce high-quality quantum code using the Qiskit library. This work includes an examination of the various aspects of the LLMs used for training and the specific training conditions, as well as the results obtained with our current models. To evaluate our models, we have developed a custom benchmark, similar to HumanEval, which includes a set of tests specifically designed for the field of quantum computing programming using Qiskit. Our findings indicate that our model outperforms existing state-of-the-art models in quantum computing tasks. We also provide examples of code suggestions, comparing our model to other relevant code LLMs. Finally, we introduce a discussion on the potential benefits of Code LLMs for quantum computing computational scientists, researchers, and practitioners. We also explore various features and future work that could be relevant in this context.
Optimal partition of feature using Bayesian classifier
Apr 27, 2023



The Naive Bayesian classifier is a popular classification method employing the Bayesian paradigm. The concept of having conditional dependence among input variables sounds good in theory but can lead to a majority vote style behaviour. Achieving conditional independence is often difficult, and they introduce decision biases in the estimates. In Naive Bayes, certain features are called independent features as they have no conditional correlation or dependency when predicting a classification. In this paper, we focus on the optimal partition of features by proposing a novel technique called the Comonotone-Independence Classifier (CIBer) which is able to overcome the challenges posed by the Naive Bayes method. For different datasets, we clearly demonstrate the efficacy of our technique, where we achieve lower error rates and higher or equivalent accuracy compared to models such as Random Forests and XGBoost.
PSP-HDRI$+$: A Synthetic Dataset Generator for Pre-Training of Human-Centric Computer Vision Models
Jul 11, 2022
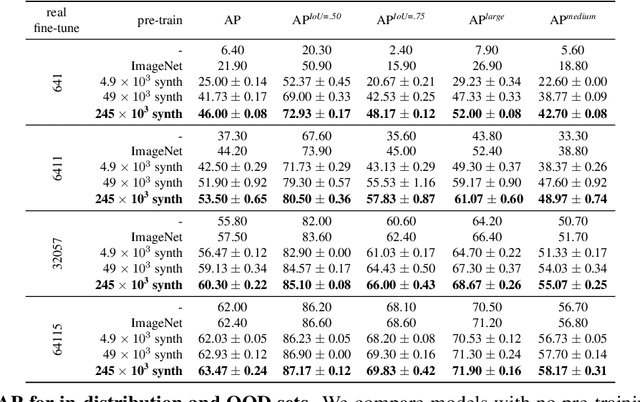
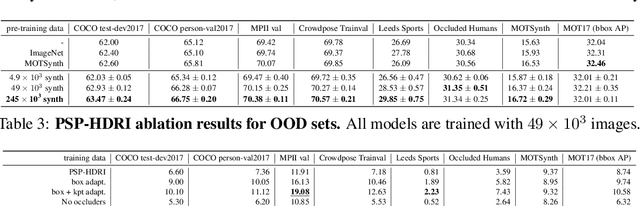

We introduce a new synthetic data generator PSP-HDRI$+$ that proves to be a superior pre-training alternative to ImageNet and other large-scale synthetic data counterparts. We demonstrate that pre-training with our synthetic data will yield a more general model that performs better than alternatives even when tested on out-of-distribution (OOD) sets. Furthermore, using ablation studies guided by person keypoint estimation metrics with an off-the-shelf model architecture, we show how to manipulate our synthetic data generator to further improve model performance.
Automated Source Code Generation and Auto-completion Using Deep Learning: Comparing and Discussing Current Language-Model-Related Approaches
Sep 16, 2020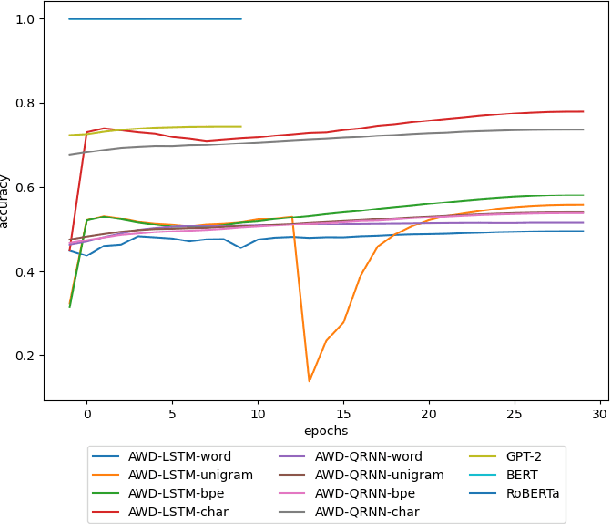
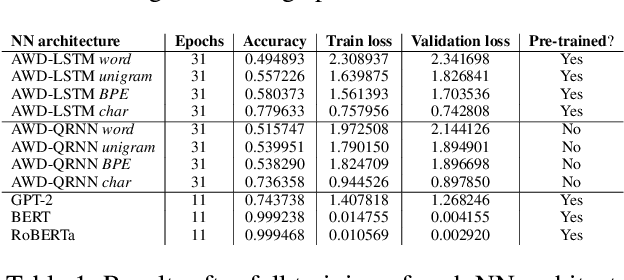
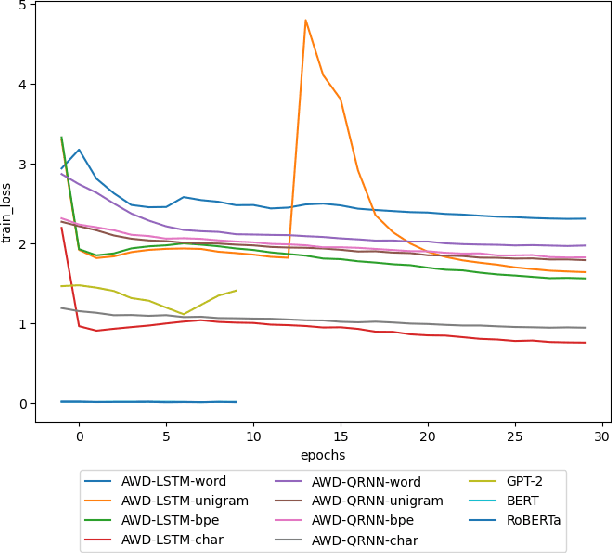
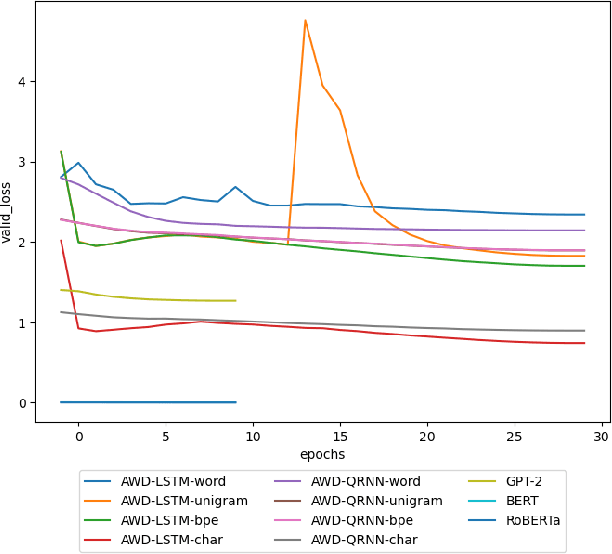
In recent years, the use of deep learning in language models, text auto-completion, and text generation has made tremendous progress and gained much attention from the research community. Some products and research projects claim that they can generate text that can be interpreted as human-writing, enabling new possibilities in many application areas. Among the different areas related to language processing, one of the most notable in applying this type of modeling is the processing of programming languages. For years, the Machine Learning community has been researching in this Big Code area, pursuing goals like applying different approaches to auto-complete generate, fix, or evaluate code programmed by humans. One of the approaches followed in recent years to pursue these goals is the use of Deep-Learning-enabled language models. Considering the increasing popularity of that approach, we detected a lack of empirical papers that compare different methods and deep learning architectures to create and use language models based on programming code. In this paper, we compare different neural network (NN) architectures like AWD-LSTMs, AWD-QRNNs, and Transformer, while using transfer learning, and different tokenizations to see how they behave in building language models using a Python dataset for code generation and filling mask tasks. Considering the results, we discuss the different strengths and weaknesses of each approach and technique and what lacks do we find to evaluate the language models or apply them in a real programming context while including humans-in-the-loop.