 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Quantum-Classical Attention in Patch Transformers for Enhanced Time Series Forecasting
Mar 31, 2025



QCAAPatchTF is a quantum attention network integrated with an advanced patch-based transformer, designed for multivariate time series forecasting, classification, and anomaly detection. Leveraging quantum superpositions, entanglement, and variational quantum eigensolver principles, the model introduces a quantum-classical hybrid self-attention mechanism to capture multivariate correlations across time points. For multivariate long-term time series, the quantum self-attention mechanism can reduce computational complexity while maintaining temporal relationships. It then applies the quantum-classical hybrid self-attention mechanism alongside a feed-forward network in the encoder stage of the advanced patch-based transformer. While the feed-forward network learns nonlinear representations for each variable frame, the quantum self-attention mechanism processes individual series to enhance multivariate relationships. The advanced patch-based transformer computes the optimized patch length by dividing the sequence length into a fixed number of patches instead of using an arbitrary set of values. The stride is then set to half of the patch length to ensure efficient overlapping representations while maintaining temporal continuity. QCAAPatchTF achieves state-of-the-art performance in both long-term and short-term forecasting, classification, and anomaly detection tasks, demonstrating state-of-the-art accuracy and efficiency on complex real-world datasets.
Enhancing Time Series Forecasting with Fuzzy Attention-Integrated Transformers
Mar 31, 2025



This paper introduces FANTF (Fuzzy Attention Network-Based Transformers), a novel approach that integrates fuzzy logic with existing transformer architectures to advance time series forecasting, classification, and anomaly detection tasks. FANTF leverages a proposed fuzzy attention mechanism incorporating fuzzy membership functions to handle uncertainty and imprecision in noisy and ambiguous time series data. The FANTF approach enhances its ability to capture complex temporal dependencies and multivariate relationships by embedding fuzzy logic principles into the self-attention module of the existing transformer's architecture. The framework combines fuzzy-enhanced attention with a set of benchmark existing transformer-based architectures to provide efficient predictions, classification and anomaly detection. Specifically, FANTF generates learnable fuzziness attention scores that highlight the relative importance of temporal features and data points, offering insights into its decision-making process. Experimental evaluatios on some real-world datasets reveal that FANTF significantly enhances the performance of forecasting, classification, and anomaly detection tasks over traditional transformer-based models.
EDformer: Embedded Decomposition Transformer for Interpretable Multivariate Time Series Predictions
Dec 16, 2024



Time series forecasting is a crucial challenge with significant applications in areas such as weather prediction, stock market analysis, and scientific simulations. This paper introduces an embedded decomposed transformer, 'EDformer', for multivariate time series forecasting tasks. Without altering the fundamental elements, we reuse the Transformer architecture and consider the capable functions of its constituent parts in this work. Edformer first decomposes the input multivariate signal into seasonal and trend components. Next, the prominent multivariate seasonal component is reconstructed across the reverse dimensions, followed by applying the attention mechanism and feed-forward network in the encoder stage. In particular, the feed-forward network is used for each variable frame to learn nonlinear representations, while the attention mechanism uses the time points of individual seasonal series embedded within variate frames to capture multivariate correlations. Therefore, the trend signal is added with projection and performs the final forecasting. The EDformer model obtains state-of-the-art predicting results in terms of accuracy and efficiency on complex real-world time series datasets. This paper also addresses model explainability techniques to provide insights into how the model makes its predictions and why specific features or time steps are important, enhancing the interpretability and trustworthiness of the forecasting results.
A Study on Quantum Neural Networks in Healthcare 5.0
Dec 03, 2024



The working environment in healthcare analytics is transforming with the emergence of healthcare 5.0 and the advancements in quantum neural networks. In addition to analyzing a comprehensive set of case studies, we also review relevant literature from the fields of quantum computing applications and smart healthcare analytics, focusing on the implications of quantum deep neural networks. This study aims to shed light on the existing research gaps regarding the implications of quantum neural networks in healthcare analytics. We argue that the healthcare industry is currently transitioning from automation towards genuine collaboration with quantum networks, which presents new avenues for research and exploration. Specifically, this study focuses on evaluating the performance of Healthcare 5.0, which involves the integration of diverse quantum machine learning and quantum neural network systems. This study also explores a range of potential challenges and future directions for Healthcare 5.0, particularly focusing on the integration of quantum neural networks.
Gamified AI Approch for Early Detection of Dementia
May 26, 2024



This paper aims to develop a new deep learning-inspired gaming approach for early detection of dementia. This research integrates a robust convolutional neural network (CNN)-based model for early dementia detection using health metrics data as well as facial image data through a cognitive assessment-based gaming application. We have collected 1000 data samples of health metrics dataset from Apollo Diagnostic Center Kolkata that is labeled as either demented or non-demented for the training of MOD-1D-CNN for the game level 1 and another dataset of facial images containing 1800 facial data that are labeled as either demented or non-demented is collected by our research team for the training of MOD-2D-CNN model in-game level 2. In our work, the loss for the proposed MOD-1D-CNN model is 0.2692 and the highest accuracy is 70.50% for identifying the dementia traits using real-life health metrics data. Similarly, the proposed MOD-2D-CNN model loss is 0.1755 and the highest accuracy is obtained here 95.72% for recognizing the dementia status using real-life face-based image data. Therefore, a rule-based weightage method is applied to combine both the proposed methods to achieve the final decision. The MOD-1D-CNN and MOD-2D-CNN models are more lightweight and computationally efficient alternatives because they have a significantly lower number of parameters when compared to the other state-of-the-art models. We have compared their accuracies and parameters with the other state-of-the-art deep learning models.
Detection and Classification of Novel Attacks and Anomaly in IoT Network using Rule based Deep Learning Model
Jul 29, 2023



Attackers are now using sophisticated techniques, like polymorphism, to change the attack pattern for each new attack. Thus, the detection of novel attacks has become the biggest challenge for cyber experts and researchers. Recently, anomaly and hybrid approaches are used for the detection of network attacks. Detecting novel attacks, on the other hand, is a key enabler for a wide range of IoT applications. Novel attacks can easily evade existing signature-based detection methods and are extremely difficult to detect, even going undetected for years. Existing machine learning models have also failed to detect the attack and have a high rate of false positives. In this paper, a rule-based deep neural network technique has been proposed as a framework for addressing the problem of detecting novel attacks. The designed framework significantly improves respective benchmark results, including the CICIDS 2017 dataset. The experimental results show that the proposed model keeps a good balance between attack detection, untruthful positive rates, and untruthful negative rates. For novel attacks, the model has an accuracy of more than 99%. During the automatic interaction between network-devices (IoT), security and privacy are the primary obstacles. Our proposed method can handle these obstacles efficiently and finally identify, and classify the different levels of threats.
A Study and Analysis of a Feature Subset Selection Technique using Penguin Search Optimization Algorithm
Jul 13, 2019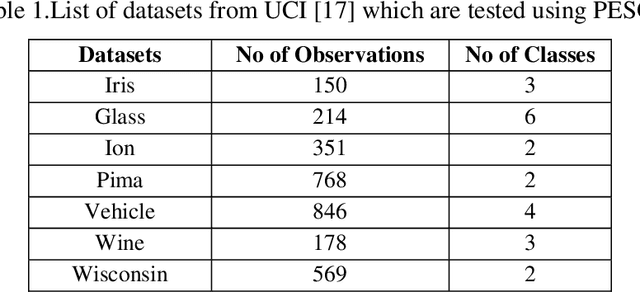
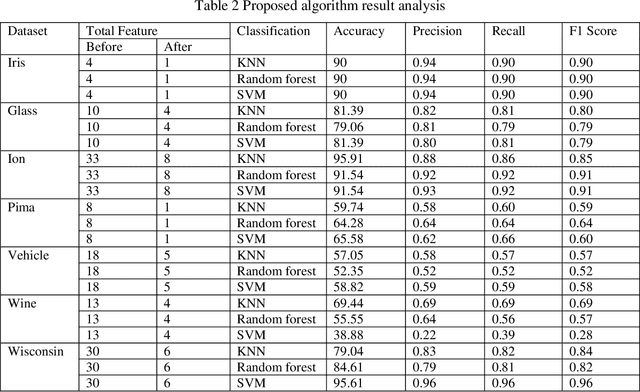
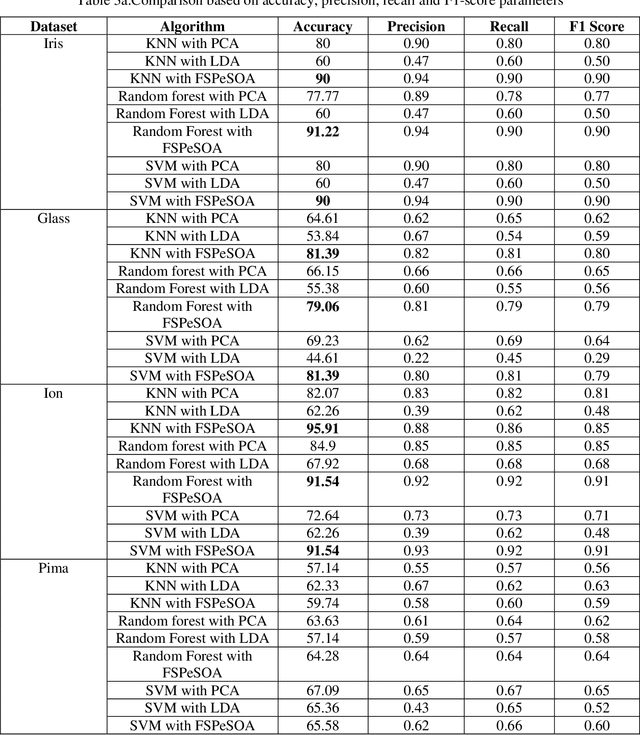
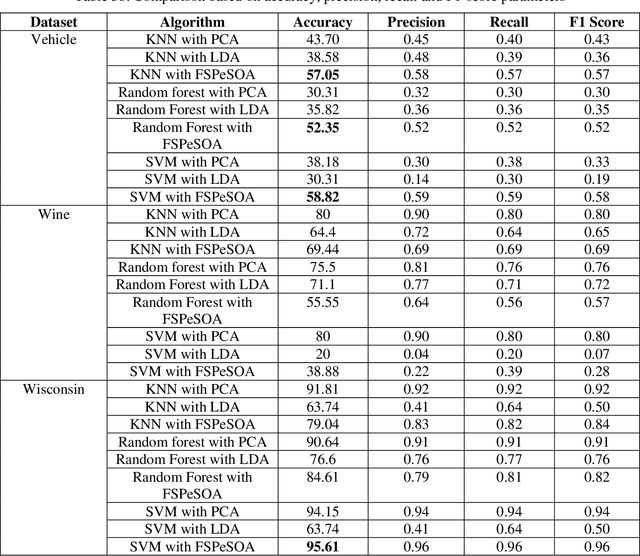
In today world of enormous amounts of data, it is very important to extract useful knowledge from it. This can be accomplished by feature subset selection. Feature subset selection is a method of selecting a minimum number of features with the help of which our machine can learn and predict which class a particular data belongs to. We will introduce a new adaptive algorithm called Feature selection Penguin Search optimization algorithm which is a metaheuristic approach. It is adapted from the natural hunting strategy of penguins in which a group of penguins take jumps at random depths and come back and share the status of food availability with other penguins and in this way, the global optimum solution is found. In order to explore the feature subset candidates, the bioinspired approach Penguin Search optimization algorithm generates during the process a trial feature subset and estimates its fitness value by using three different classifiers for each case: Random Forest, Nearest Neighbour and Support Vector Machines. However, we are planning to implement our proposed approach Feature selection Penguin Search optimization algorithm on some well known benchmark datasets collected from the UCI repository and also try to evaluate and compare its classification accuracy with some state of art algorithms.
Sentiment Analysis of Review Datasets Using Naive Bayes and K-NN Classifier
Oct 31, 2016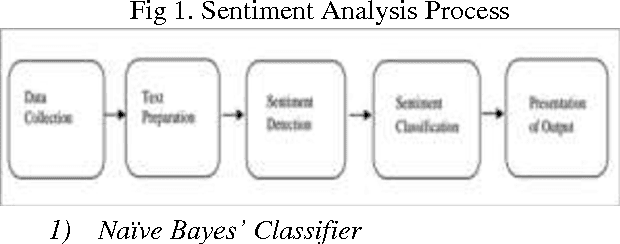
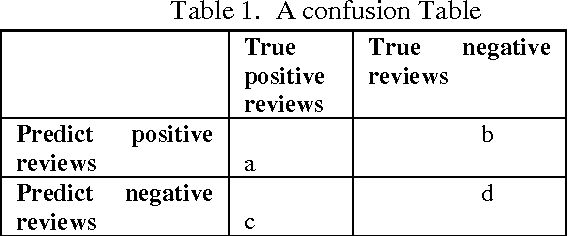
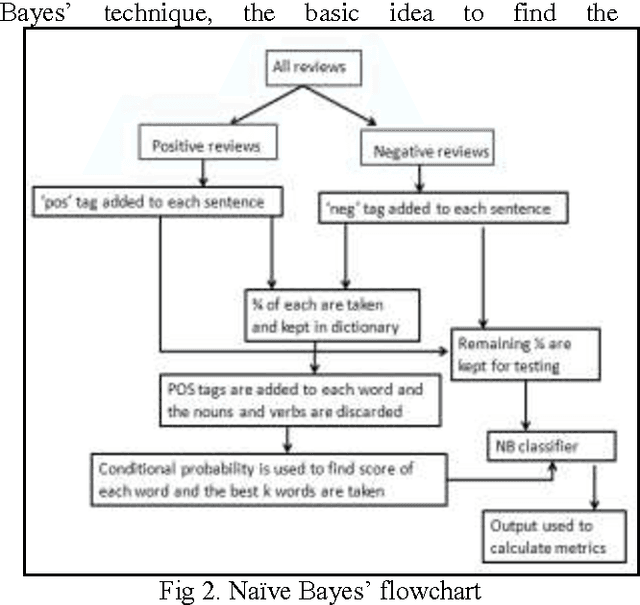
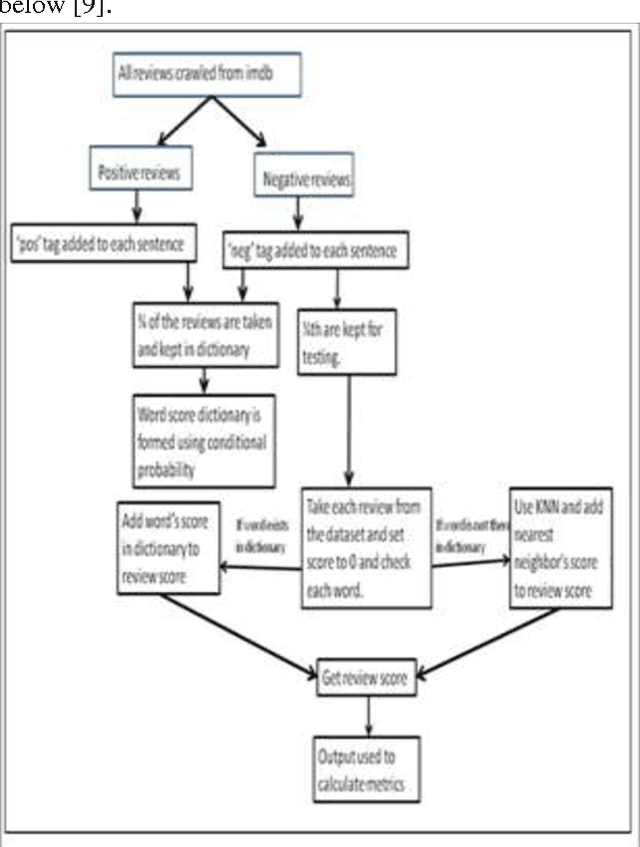
The advent of Web 2.0 has led to an increase in the amount of sentimental content available in the Web. Such content is often found in social media web sites in the form of movie or product reviews, user comments, testimonials, messages in discussion forums etc. Timely discovery of the sentimental or opinionated web content has a number of advantages, the most important of all being monetization. Understanding of the sentiments of human masses towards different entities and products enables better services for contextual advertisements, recommendation systems and analysis of market trends. The focus of our project is sentiment focussed web crawling framework to facilitate the quick discovery of sentimental contents of movie reviews and hotel reviews and analysis of the same. We use statistical methods to capture elements of subjective style and the sentence polarity. The paper elaborately discusses two supervised machine learning algorithms: K-Nearest Neighbour(K-NN) and Naive Bayes and compares their overall accuracy, precisions as well as recall values. It was seen that in case of movie reviews Naive Bayes gave far better results than K-NN but for hotel reviews these algorithms gave lesser, almost same accuracies.