 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAryabhata: An exam-focused language model for JEE Math
Aug 13, 2025We present Aryabhata 1.0, a compact 7B parameter math reasoning model optimized for the Indian academic exam, the Joint Entrance Examination (JEE). Despite rapid progress in large language models (LLMs), current models often remain unsuitable for educational use. Aryabhata 1.0 is built by merging strong open-weight reasoning models, followed by supervised fine-tuning (SFT) with curriculum learning on verified chain-of-thought (CoT) traces curated through best-of-$n$ rejection sampling. To further boost performance, we apply reinforcement learning with verifiable rewards (RLVR) using A2C objective with group-relative advantage estimation along with novel exploration strategies such as Adaptive Group Resizing and Temperature Scaling. Evaluated on both in-distribution (JEE Main 2025) and out-of-distribution (MATH, GSM8K) benchmarks, Aryabhata outperforms existing models in accuracy and efficiency, while offering pedagogically useful step-by-step reasoning. We release Aryabhata as a foundation model to advance exam-centric, open-source small language models. This marks our first open release for community feedback (https://huggingface.co/PhysicsWallahAI/Aryabhata-1.0); PW is actively training future models to further improve learning outcomes for students.
Learning semantic Image attributes using Image recognition and knowledge graph embeddings
Sep 12, 2020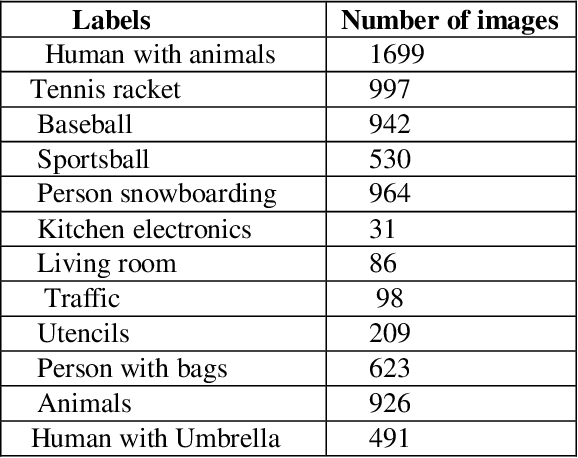
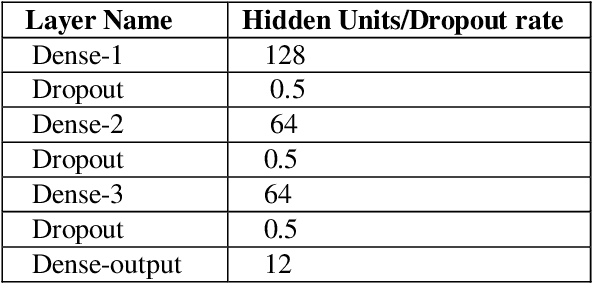
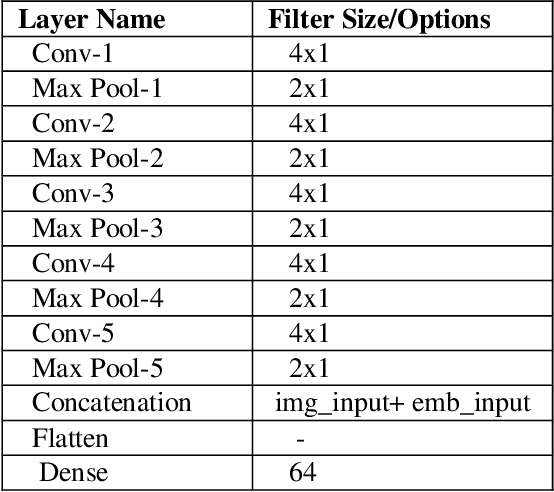
Extracting structured knowledge from texts has traditionally been used for knowledge base generation. However, other sources of information, such as images can be leveraged into this process to build more complete and richer knowledge bases. Structured semantic representation of the content of an image and knowledge graph embeddings can provide a unique representation of semantic relationships between image entities. Linking known entities in knowledge graphs and learning open-world images using language models has attracted lots of interest over the years. In this paper, we propose a shared learning approach to learn semantic attributes of images by combining a knowledge graph embedding model with the recognized attributes of images. The proposed model premises to help us understand the semantic relationship between the entities of an image and implicitly provide a link for the extracted entities through a knowledge graph embedding model. Under the limitation of using a custom user-defined knowledge base with limited data, the proposed model presents significant accuracy and provides a new alternative to the earlier approaches. The proposed approach is a step towards bridging the gap between frameworks which learn from large amounts of data and frameworks which use a limited set of predicates to infer new knowledge.