 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Influence of Feature Representation of Text on the Performance of Document Classification
Jul 05, 2017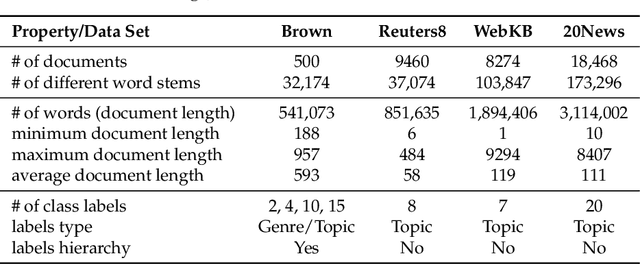
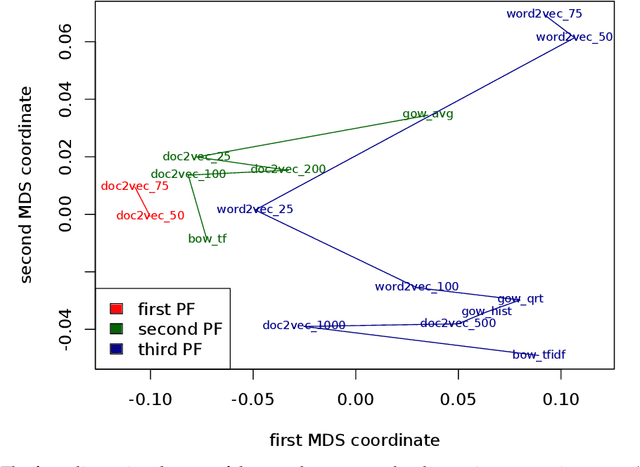
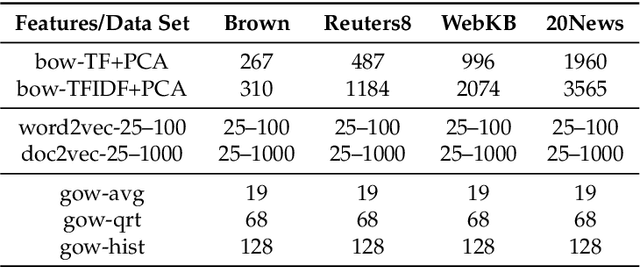

In this paper we perform a comparative analysis of three models for feature representation of text documents in the context of document classification. In particular, we consider the most often used family of models bag-of-words, recently proposed continuous space models word2vec and doc2vec, and the model based on the representation of text documents as language networks. While the bag-of-word models have been extensively used for the document classification task, the performance of the other two models for the same task have not been well understood. This is especially true for the network-based model that have been rarely considered for representation of text documents for classification. In this study, we measure the performance of the document classifiers trained using the method of random forests for features generated the three models and their variants. The results of the empirical comparison show that the commonly used bag-of-words model has performance comparable to the one obtained by the emerging continuous-space model of doc2vec. In particular, the low-dimensional variants of doc2vec generating up to 75 features are among the top-performing document representation models. The results finally point out that doc2vec shows a superior performance in the tasks of classifying large documents.
Multilayer Network of Language: a Unified Framework for Structural Analysis of Linguistic Subsystems
Jul 30, 2015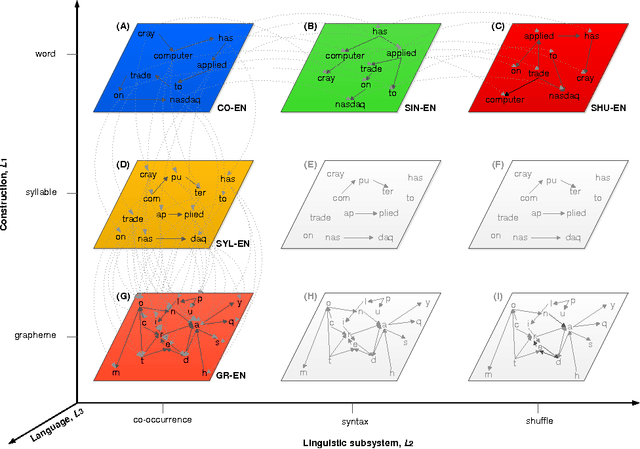
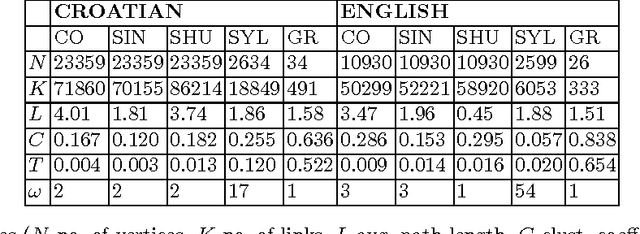
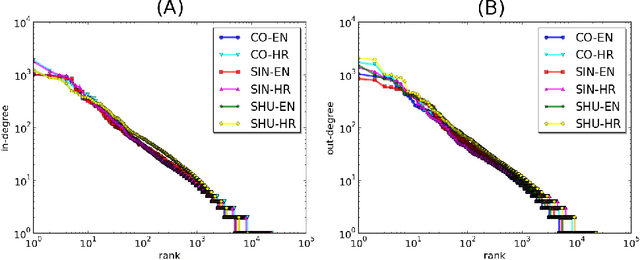
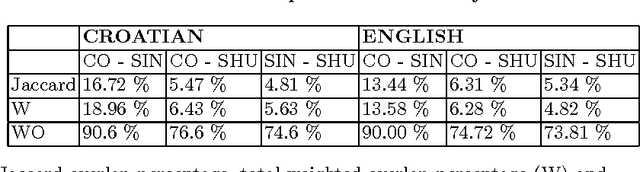
Recently, the focus of complex networks research has shifted from the analysis of isolated properties of a system toward a more realistic modeling of multiple phenomena - multilayer networks. Motivated by the prosperity of multilayer approach in social, transport or trade systems, we propose the introduction of multilayer networks for language. The multilayer network of language is a unified framework for modeling linguistic subsystems and their structural properties enabling the exploration of their mutual interactions. Various aspects of natural language systems can be represented as complex networks, whose vertices depict linguistic units, while links model their relations. The multilayer network of language is defined by three aspects: the network construction principle, the linguistic subsystem and the language of interest. More precisely, we construct a word-level (syntax, co-occurrence and its shuffled counterpart) and a subword level (syllables and graphemes) network layers, from five variations of original text (in the modeled language). The obtained results suggest that there are substantial differences between the networks structures of different language subsystems, which are hidden during the exploration of an isolated layer. The word-level layers share structural properties regardless of the language (e.g. Croatian or English), while the syllabic subword level expresses more language dependent structural properties. The preserved weighted overlap quantifies the similarity of word-level layers in weighted and directed networks. Moreover, the analysis of motifs reveals a close topological structure of the syntactic and syllabic layers for both languages. The findings corroborate that the multilayer network framework is a powerful, consistent and systematic approach to model several linguistic subsystems simultaneously and hence to provide a more unified view on language.
Normalization of Non-Standard Words in Croatian Texts
Mar 30, 2015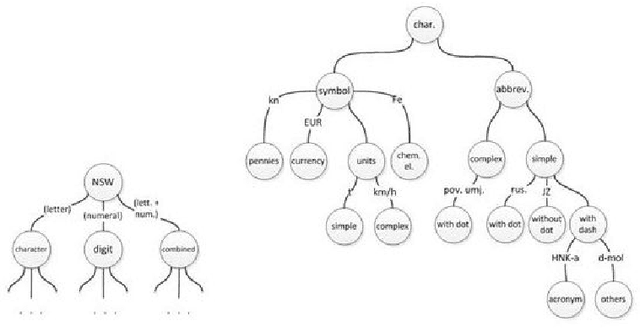
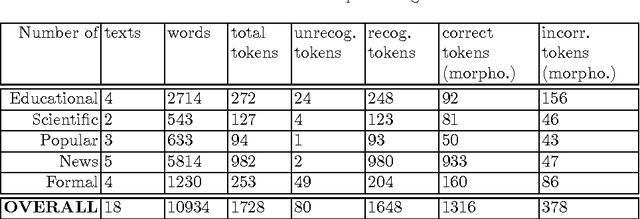
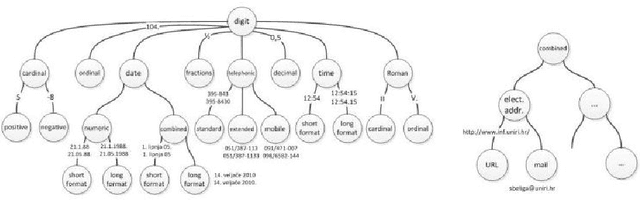
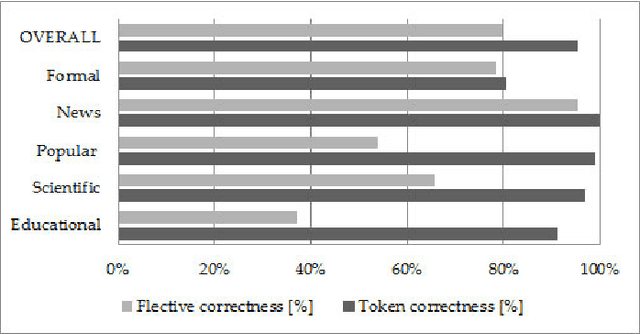
This paper presents text normalization which is an integral part of any text-to-speech synthesis system. Text normalization is a set of methods with a task to write non-standard words, like numbers, dates, times, abbreviations, acronyms and the most common symbols, in their full expanded form are presented. The whole taxonomy for classification of non-standard words in Croatian language together with rule-based normalization methods combined with a lookup dictionary are proposed. Achieved token rate for normalization of Croatian texts is 95%, where 80% of expanded words are in correct morphological form.
Network Motifs Analysis of Croatian Literature
Nov 18, 2014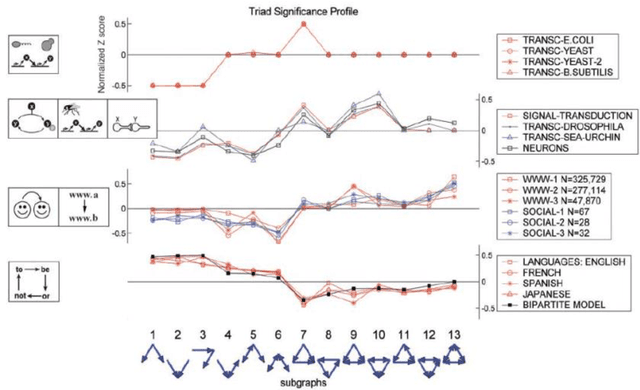
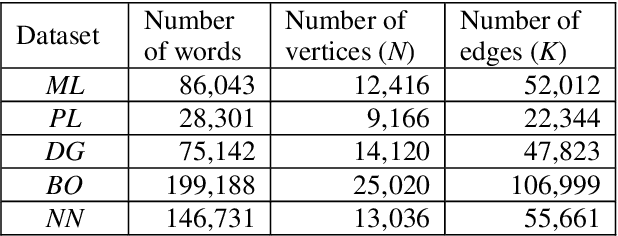
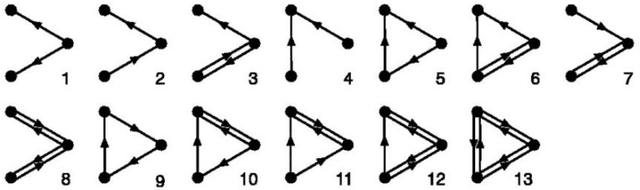

In this paper we analyse network motifs in the co-occurrence directed networks constructed from five different texts (four books and one portal) in the Croatian language. After preparing the data and network construction, we perform the network motif analysis. We analyse the motif frequencies and Z-scores in the five networks. We present the triad significance profile for five datasets. Furthermore, we compare our results with the existing results for the linguistic networks. Firstly, we show that the triad significance profile for the Croatian language is very similar with the other languages and all the networks belong to the same family of networks. However, there are certain differences between the Croatian language and other analysed languages. We conclude that this is due to the free word-order of the Croatian language.
Non-Standard Words as Features for Text Categorization
Nov 16, 2014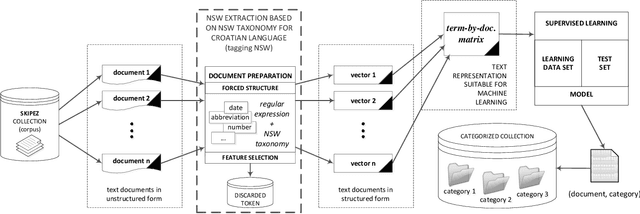
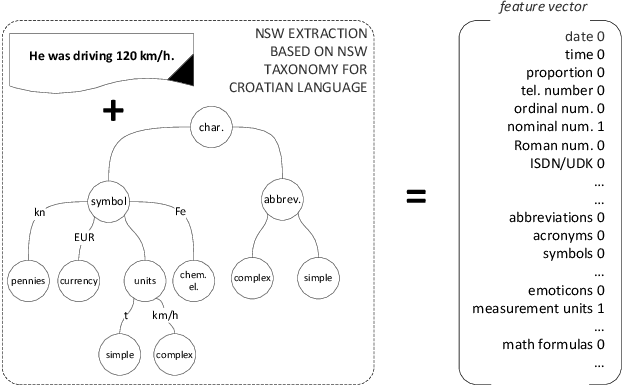
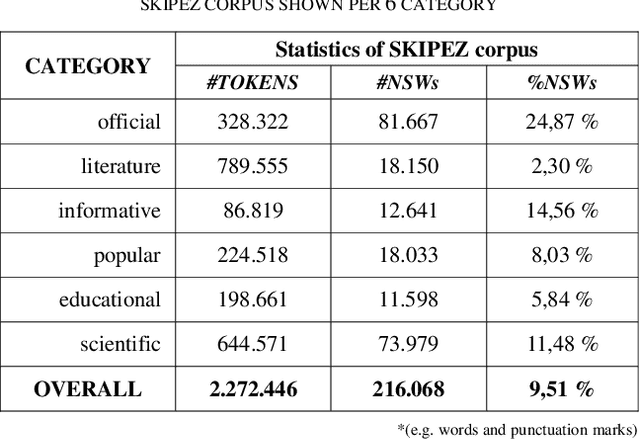
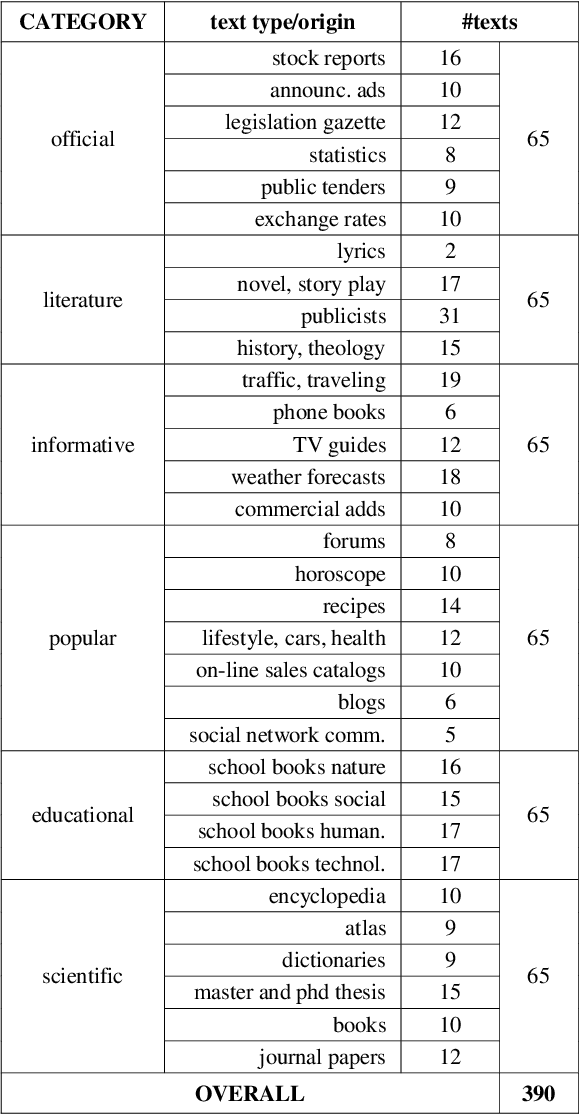
This paper presents categorization of Croatian texts using Non-Standard Words (NSW) as features. Non-Standard Words are: numbers, dates, acronyms, abbreviations, currency, etc. NSWs in Croatian language are determined according to Croatian NSW taxonomy. For the purpose of this research, 390 text documents were collected and formed the SKIPEZ collection with 6 classes: official, literary, informative, popular, educational and scientific. Text categorization experiment was conducted on three different representations of the SKIPEZ collection: in the first representation, the frequencies of NSWs are used as features; in the second representation, the statistic measures of NSWs (variance, coefficient of variation, standard deviation, etc.) are used as features; while the third representation combines the first two feature sets. Naive Bayes, CN2, C4.5, kNN, Classification Trees and Random Forest algorithms were used in text categorization experiments. The best categorization results are achieved using the first feature set (NSW frequencies) with the categorization accuracy of 87%. This suggests that the NSWs should be considered as features in highly inflectional languages, such as Croatian. NSW based features reduce the dimensionality of the feature space without standard lemmatization procedures, and therefore the bag-of-NSWs should be considered for further Croatian texts categorization experiments.
* IEEE 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO 2014), pp. 1415-1419, 2014
Initial Comparison of Linguistic Networks Measures for Parallel Texts
Jul 17, 2014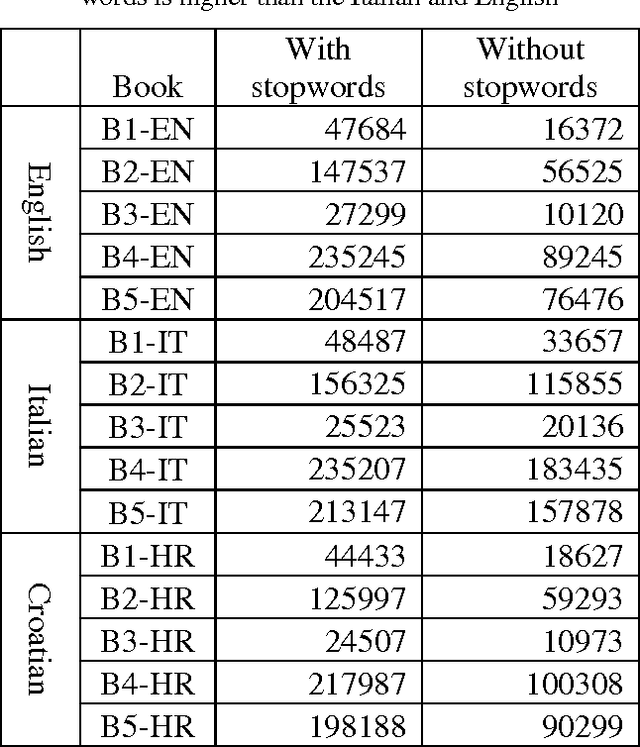
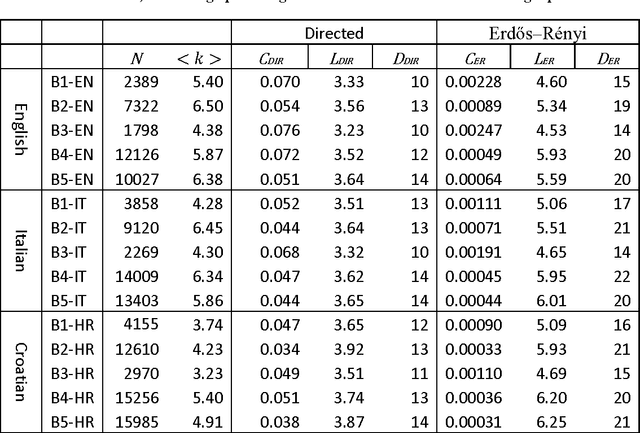
This paper presents preliminary results of Croatian syllable networks analysis. Syllable network is a network in which nodes are syllables and links between them are constructed according to their connections within words. In this paper we analyze networks of syllables generated from texts collected from the Croatian Wikipedia and Blogs. As a main tool we use complex network analysis methods which provide mechanisms that can reveal new patterns in a language structure. We aim to show that syllable networks have much higher clustering coefficient in comparison to Erd\"os-Renyi random networks. The results indicate that Croatian syllable networks exhibit certain properties of a small world networks. Furthermore, we compared Croatian syllable networks with Portuguese and Chinese syllable networks and we showed that they have similar properties.
Comparison of the language networks from literature and blogs
Jul 17, 2014
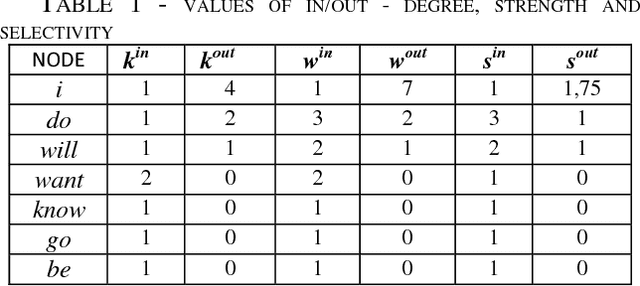
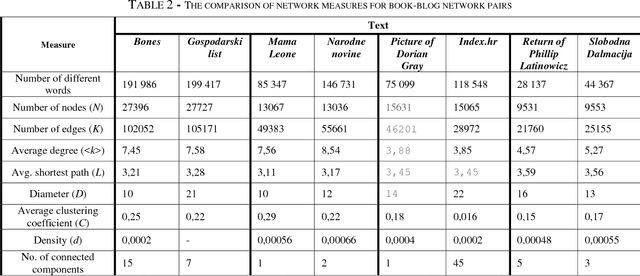
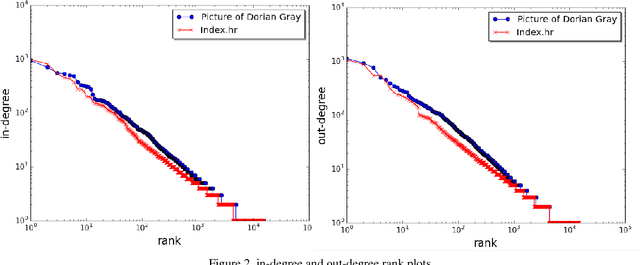
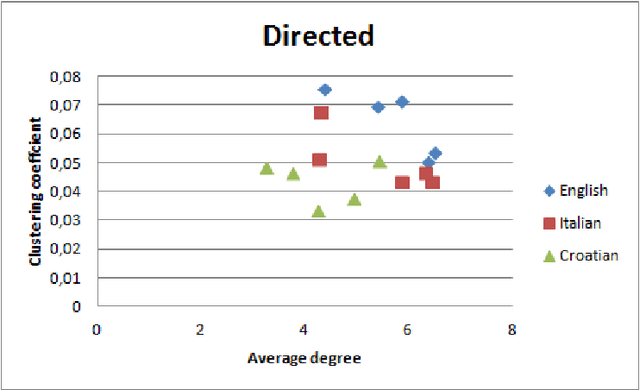
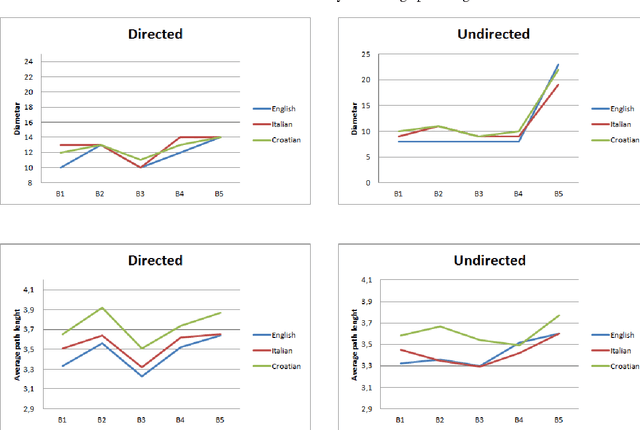
In this paper we present the comparison of the linguistic networks from literature and blog texts. The linguistic networks are constructed from texts as directed and weighted co-occurrence networks of words. Words are nodes and links are established between two nodes if they are directly co-occurring within the sentence. The comparison of the networks structure is performed at global level (network) in terms of: average node degree, average shortest path length, diameter, clustering coefficient, density and number of components. Furthermore, we perform analysis on the local level (node) by comparing the rank plots of in and out degree, strength and selectivity. The selectivity-based results point out that there are differences between the structure of the networks constructed from literature and blogs.
Toward Selectivity Based Keyword Extraction for Croatian News
Jul 17, 2014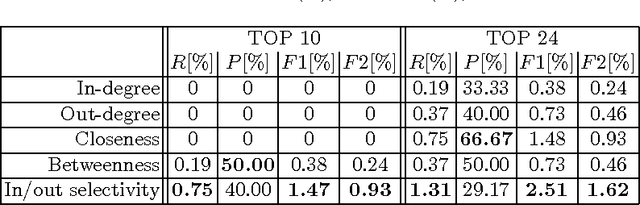
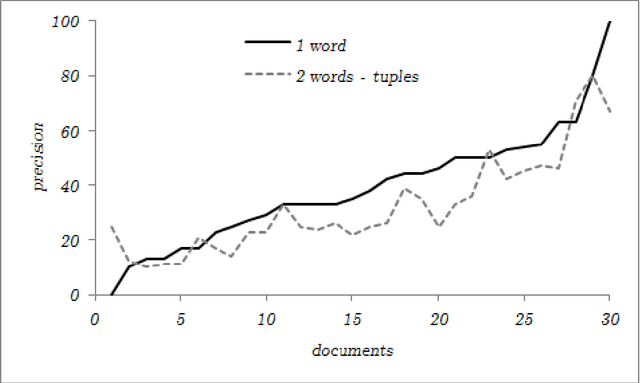
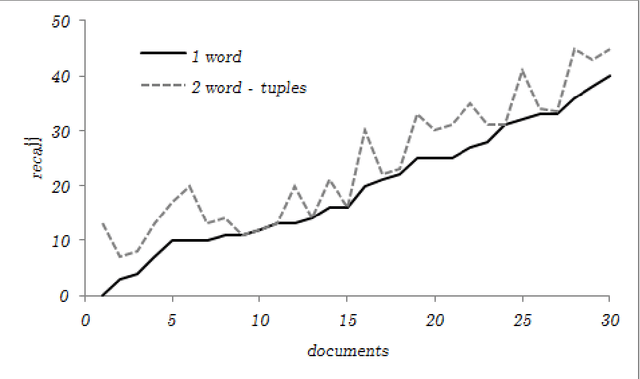
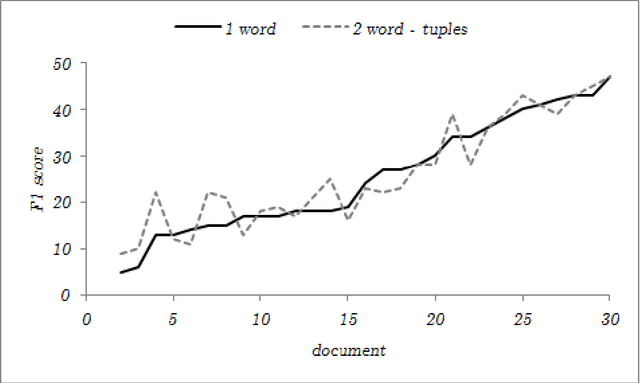
Preliminary report on network based keyword extraction for Croatian is an unsupervised method for keyword extraction from the complex network. We build our approach with a new network measure the node selectivity, motivated by the research of the graph based centrality approaches. The node selectivity is defined as the average weight distribution on the links of the single node. We extract nodes (keyword candidates) based on the selectivity value. Furthermore, we expand extracted nodes to word-tuples ranked with the highest in/out selectivity values. Selectivity based extraction does not require linguistic knowledge while it is purely derived from statistical and structural information en-compassed in the source text which is reflected into the structure of the network. Obtained sets are evaluated on a manually annotated keywords: for the set of extracted keyword candidates average F1 score is 24,63%, and average F2 score is 21,19%; for the exacted words-tuples candidates average F1 score is 25,9% and average F2 score is 24,47%.
Toward Network-based Keyword Extraction from Multitopic Web Documents
Jul 14, 2014
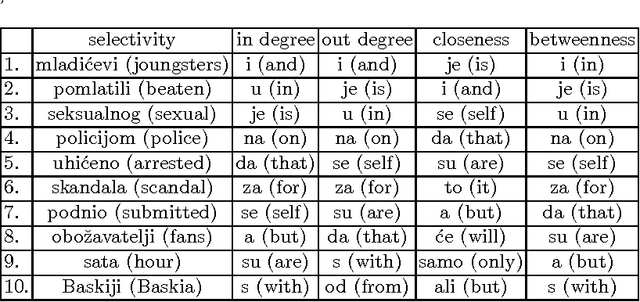
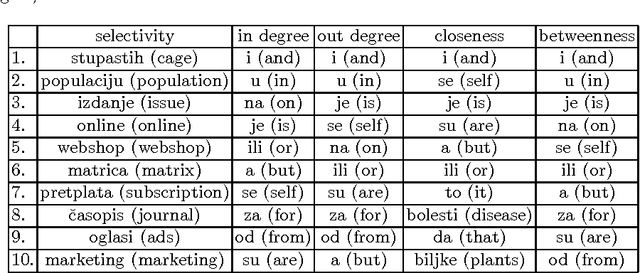
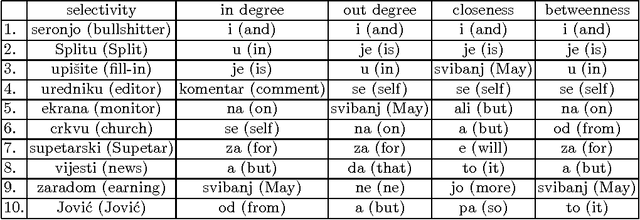
In this paper we analyse the selectivity measure calculated from the complex network in the task of the automatic keyword extraction. Texts, collected from different web sources (portals, forums), are represented as directed and weighted co-occurrence complex networks of words. Words are nodes and links are established between two nodes if they are directly co-occurring within the sentence. We test different centrality measures for ranking nodes - keyword candidates. The promising results are achieved using the selectivity measure. Then we propose an approach which enables extracting word pairs according to the values of the in/out selectivity and weight measures combined with filtering.
Preliminary Report on the Structure of Croatian Linguistic Co-occurrence Networks
May 17, 2014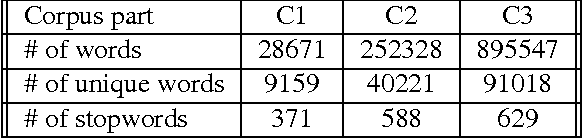
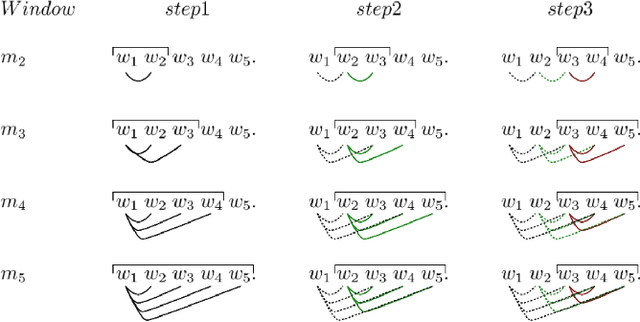
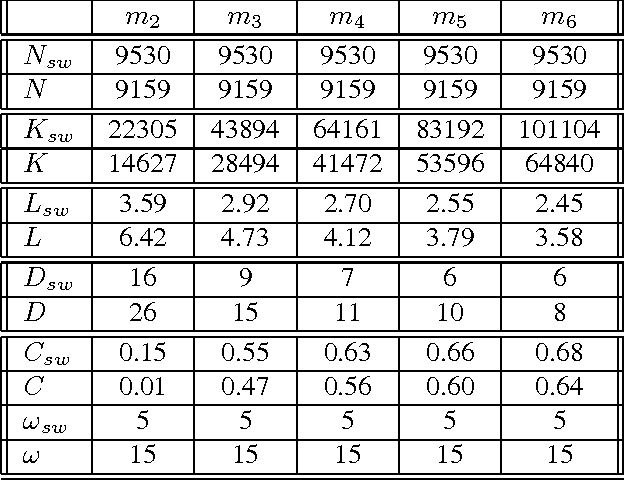
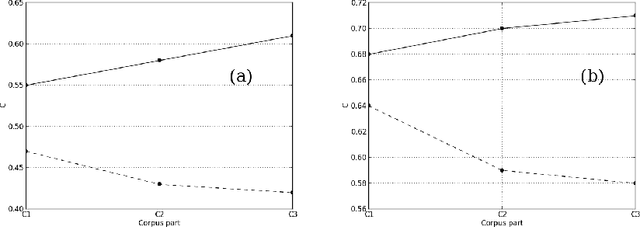
In this article, we investigate the structure of Croatian linguistic co-occurrence networks. We examine the change of network structure properties by systematically varying the co-occurrence window sizes, the corpus sizes and removing stopwords. In a co-occurrence window of size $n$ we establish a link between the current word and $n-1$ subsequent words. The results point out that the increase of the co-occurrence window size is followed by a decrease in diameter, average path shortening and expectedly condensing the average clustering coefficient. The same can be noticed for the removal of the stopwords. Finally, since the size of texts is reflected in the network properties, our results suggest that the corpus influence can be reduced by increasing the co-occurrence window size.