 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable Foundation Models for Retinal Fundus Images
Mar 19, 2026Foundation models are used to extract transferable representations from large amounts of unlabeled data, typically via self-supervised learning (SSL). However, many of these models rely on architectures that offer limited interpretability, which is a critical issue in high-stakes domains such as medical imaging. We propose Dual-IFM, a foundation model that is interpretable-by-design in two ways: First, it provides local interpretability for individual images through class evidence maps that are faithful to the decision-making process. Second, it provides global interpretability for entire datasets through a 2D projection layer that allows for direct visualization of the model's representation space. We trained our model on over 800,000 color fundus photography from various sources to learn generalizable, interpretable representations for different downstream tasks. Our results show that our model reaches a performance range similar to that of state-of-the-art foundation models with up to $16\times$ the number of parameters, while providing interpretable predictions on out-of-distribution data. Our results suggest that large-scale SSL pretraining paired with inherent interpretability can lead to robust representations for retinal imaging.
A Hybrid Fully Convolutional CNN-Transformer Model for Inherently Interpretable Medical Image Classification
Apr 11, 2025In many medical imaging tasks, convolutional neural networks (CNNs) efficiently extract local features hierarchically. More recently, vision transformers (ViTs) have gained popularity, using self-attention mechanisms to capture global dependencies, but lacking the inherent spatial localization of convolutions. Therefore, hybrid models combining CNNs and ViTs have been developed to combine the strengths of both architectures. However, such hybrid CNN-ViT models are difficult to interpret, which hinders their application in medical imaging. In this work, we introduce an interpretable-by-design hybrid fully convolutional CNN-Transformer architecture for medical image classification. Unlike widely used post-hoc saliency methods for ViTs, our approach generates faithful and localized evidence maps that directly reflect the model's decision process. We evaluated our method on two medical image classification tasks using color fundus images. Our model not only achieves state-of-the-art predictive performance compared to both black-box and interpretable models but also provides class-specific sparse evidence maps in a single forward pass. The code is available at: https://anonymous.4open.science/r/Expl-CNN-Transformer/.
Towards the Localisation of Lesions in Diabetic Retinopathy
Feb 02, 2021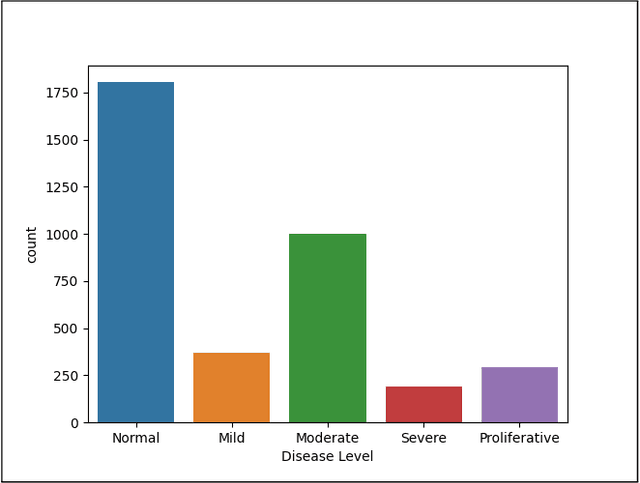
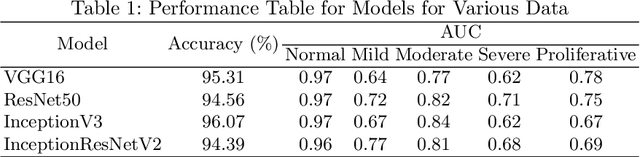
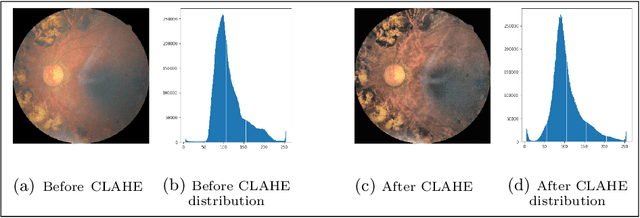
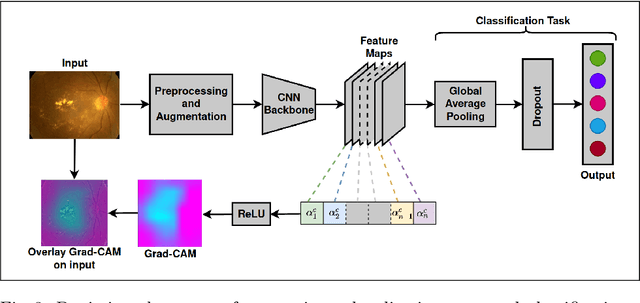
Convolutional Neural Networks (CNNs) have successfully been used to classify diabetic retinopathy (DR) fundus images in recent times. However, deeper representations in CNNs may capture higher-level semantics at the expense of spatial resolution. To make predictions usable for ophthalmologists, we use a post-attention technique called Gradient-weighted Class Activation Mapping (Grad-CAM) on the penultimate layer of deep learning models to produce coarse localisation maps on DR fundus images. This is to help identify discriminative regions in the images, consequently providing evidence for ophthalmologists to make a diagnosis and potentially save lives by early diagnosis. Specifically, this study uses pre-trained weights from four state-of-the-art deep learning models to produce and compare localisation maps of DR fundus images. The models used include VGG16, ResNet50, InceptionV3, and InceptionResNetV2. We find that InceptionV3 achieves the best performance with a test classification accuracy of 96.07%, and localise lesions better and faster than the other models.