 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunityFish: A Poisson-based Document Scaling With Hierarchical Clustering
Aug 28, 2023Document scaling has been a key component in text-as-data applications for social scientists and a major field of interest for political researchers, who aim at uncovering differences between speakers or parties with the help of different probabilistic and non-probabilistic approaches. Yet, most of these techniques are either built upon the agnostically bag-of-word hypothesis or use prior information borrowed from external sources that might embed the results with a significant bias. If the corpus has long been considered as a collection of documents, it can also be seen as a dense network of connected words whose structure could be clustered to differentiate independent groups of words, based on their co-occurrences in documents, known as communities. This paper introduces CommunityFish as an augmented version of Wordfish based on a hierarchical clustering, namely the Louvain algorithm, on the word space to yield communities as semantic and independent n-grams emerging from the corpus and use them as an input to Wordfish method, instead of considering the word space. This strategy emphasizes the interpretability of the results, since communities have a non-overlapping structure, hence a crucial informative power in discriminating parties or speakers, in addition to allowing a faster execution of the Poisson scaling model. Aside from yielding communities, assumed to be subtopic proxies, the application of this technique outperforms the classic Wordfish model by highlighting historical developments in the U.S. State of the Union addresses and was found to replicate the prevailing political stance in Germany when using the corpus of parties' legislative manifestos.
Topic Scaling: A Joint Document Scaling -- Topic Model Approach To Learn Time-Specific Topics
Mar 31, 2021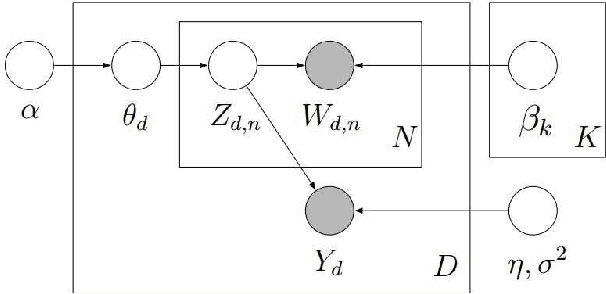
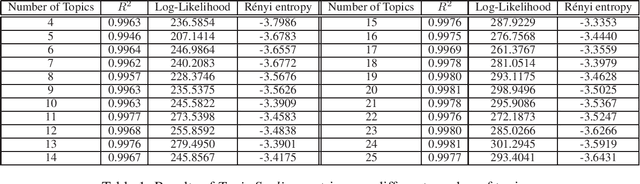
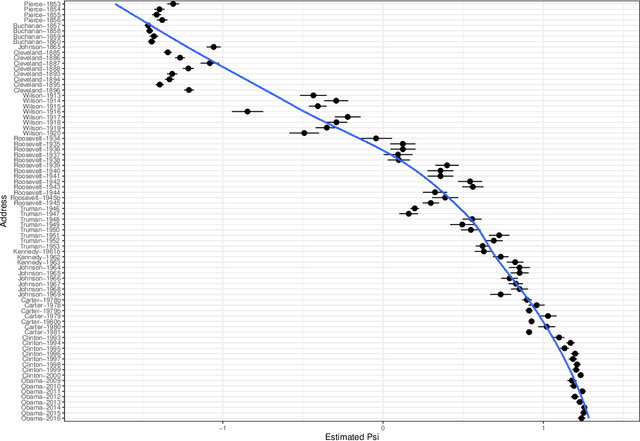

This paper proposes a new methodology to study sequential corpora by implementing a two-stage algorithm that learns time-based topics with respect to a scale of document positions and introduces the concept of Topic Scaling which ranks learned topics within the same document scale. The first stage ranks documents using Wordfish, a Poisson-based document scaling method, to estimate document positions that serve, in the second stage, as a dependent variable to learn relevant topics via a supervised Latent Dirichlet Allocation. This novelty brings two innovations in text mining as it explains document positions, whose scale is a latent variable, and ranks the inferred topics on the document scale to match their occurrences within the corpus and track their evolution. Tested on the U.S. State Of The Union two-party addresses, this inductive approach reveals that each party dominates one end of the learned scale with interchangeable transitions that follow the parties' term of office. Besides a demonstrated high accuracy in predicting in-sample documents' positions from topic scores, this method reveals further hidden topics that differentiate similar documents by increasing the number of learned topics to unfold potential nested hierarchical topic structures. Compared to other popular topic models, Topic Scaling learns topics with respect to document similarities without specifying a time frequency to learn topic evolution, thus capturing broader topic patterns than dynamic topic models and yielding more interpretable outputs than a plain latent Dirichlet allocation.