 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generative AI-Enhanced Content: A Conceptual Framework Using Qualitative, Quantitative, and Mixed-Methods Approaches
Nov 26, 2024Generative AI (GenAI) has revolutionized content generation, offering transformative capabilities for improving language coherence, readability, and overall quality. This manuscript explores the application of qualitative, quantitative, and mixed-methods research approaches to evaluate the performance of GenAI models in enhancing scientific writing. Using a hypothetical use case involving a collaborative medical imaging manuscript, we demonstrate how each method provides unique insights into the impact of GenAI. Qualitative methods gather in-depth feedback from expert reviewers, analyzing their responses using thematic analysis tools to capture nuanced improvements and identify limitations. Quantitative approaches employ automated metrics such as BLEU, ROUGE, and readability scores, as well as user surveys, to objectively measure improvements in coherence, fluency, and structure. Mixed-methods research integrates these strengths, combining statistical evaluations with detailed qualitative insights to provide a comprehensive assessment. These research methods enable quantifying improvement levels in GenAI-generated content, addressing critical aspects of linguistic quality and technical accuracy. They also offer a robust framework for benchmarking GenAI tools against traditional editing processes, ensuring the reliability and effectiveness of these technologies. By leveraging these methodologies, researchers can evaluate the performance boost driven by GenAI, refine its applications, and guide its responsible adoption in high-stakes domains like healthcare and scientific research. This work underscores the importance of rigorous evaluation frameworks for advancing trust and innovation in GenAI.
Formulating A Strategic Plan Based On Statistical Analyses And Applications For Financial Companies Through A Real-World Use Case
Jul 17, 2023


Business statistics play a crucial role in implementing a data-driven strategic plan at the enterprise level to employ various analytics where the outcomes of such a plan enable an enterprise to enhance the decision-making process or to mitigate risks to the organization. In this work, a strategic plan informed by the statistical analysis is introduced for a financial company called LendingClub, where the plan is comprised of exploring the possibility of onboarding a big data platform along with advanced feature selection capacities. The main objectives of such a plan are to increase the company's revenue while reducing the risks of granting loans to borrowers who cannot return their loans. In this study, different hypotheses formulated to address the company's concerns are studied, where the results reveal that the amount of loans profoundly impacts the number of borrowers charging off their loans. Also, the proposed strategic plan includes onboarding advanced analytics such as machine learning technologies that allow the company to build better generalized data-driven predictive models.
French Word Recognition through a Quick Survey on Recurrent Neural Networks Using Long-Short Term Memory RNN-LSTM
Apr 10, 2018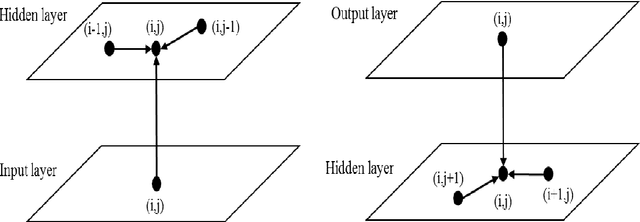

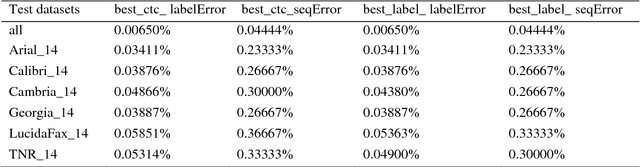
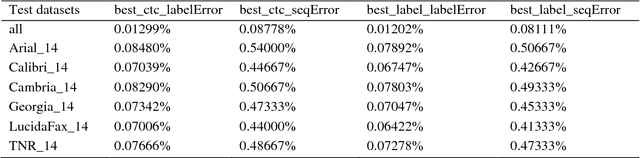
Optical character recognition (OCR) is a fundamental problem in computer vision. Research studies have shown significant progress in classifying printed characters using deep learning-based methods and topologies. Among current algorithms, recurrent neural networks with long-short term memory blocks called RNN-LSTM have provided the highest performance in terms of accuracy rate. Using the top 5,000 French words collected from the internet including all signs and accents, RNN-LSTM models were trained and tested for several cases. Six fonts were used to generate OCR samples and an additional dataset that included all samples from these six fonts was prepared for training and testing purposes. The trained RNN-LSTM models were tested and achieved the accuracy rates of 99.98798% and 99.91889% for edit distance and sequence error, respectively. An accurate preprocessing followed by height normalization (standardization methods in deep learning) enabled the RNN-LSTM model to be trained in the most efficient way. This machine learning work also revealed the robustness of RNN-LSTM topology to recognize printed characters.
Classification of Alzheimer's Disease Structural MRI Data by Deep Learning Convolutional Neural Networks
May 19, 2017



Recently, machine learning techniques especially predictive modeling and pattern recognition in biomedical sciences from drug delivery system to medical imaging has become one of the important methods which are assisting researchers to have deeper understanding of entire issue and to solve complex medical problems. Deep learning is a powerful machine learning algorithm in classification while extracting low to high-level features. In this paper, we used convolutional neural network to classify Alzheimer's brain from normal healthy brain. The importance of classifying this kind of medical data is to potentially develop a predict model or system in order to recognize the type disease from normal subjects or to estimate the stage of the disease. Classification of clinical data such as Alzheimer's disease has been always challenging and most problematic part has been always selecting the most discriminative features. Using Convolutional Neural Network (CNN) and the famous architecture LeNet-5, we successfully classified structural MRI data of Alzheimer's subjects from normal controls where the accuracy of test data on trained data reached 98.84%. This experiment suggests us the shift and scale invariant features extracted by CNN followed by deep learning classification is most powerful method to distinguish clinical data from healthy data in fMRI. This approach also enables us to expand our methodology to predict more complicated systems.
Cognitive Dynamic Systems: A Technical Review of Cognitive Radar
May 26, 2016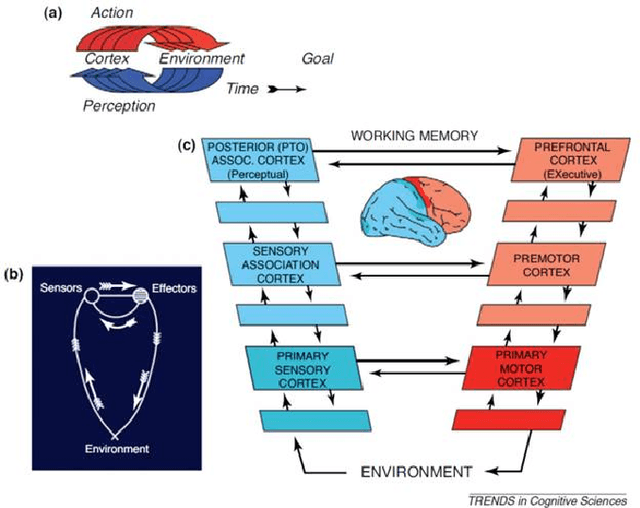
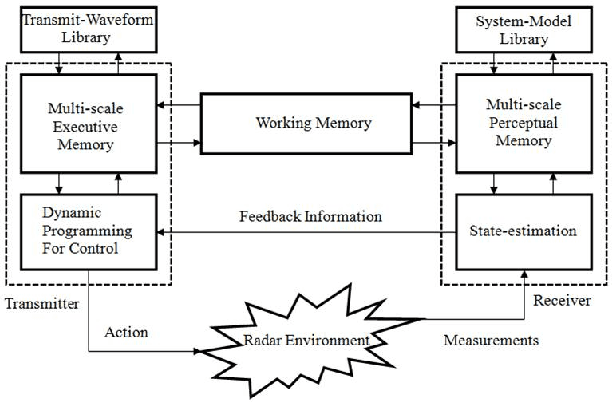
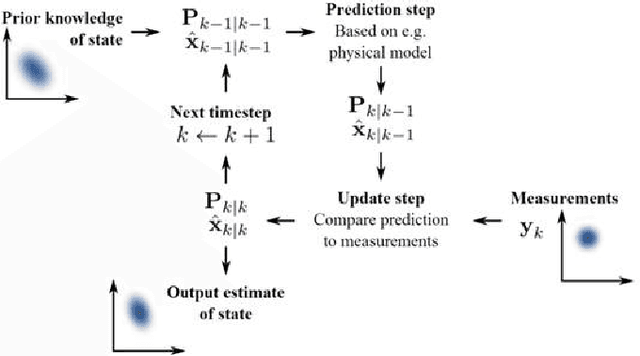
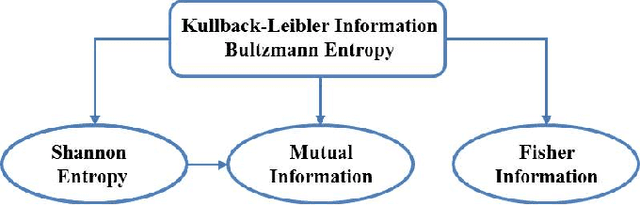
We start with the history of cognitive radar, where origins of the PAC, Fuster research on cognition and principals of cognition are provided. Fuster describes five cognitive functions: perception, memory, attention, language, and intelligence. We describe the Perception-Action Cyclec as it applies to cognitive radar, and then discuss long-term memory, memory storage, memory retrieval and working memory. A comparison between memory in human cognition and cognitive radar is given as well. Attention is another function described by Fuster, and we have given the comparison of attention in human cognition and cognitive radar. We talk about the four functional blocks from the PAC: Bayesian filter, feedback information, dynamic programming and state-space model for the radar environment. Then, to show that the PAC improves the tracking accuracy of Cognitive Radar over Traditional Active Radar, we have provided simulation results. In the simulation, three nonlinear filters: Cubature Kalman Filter, Unscented Kalman Filter and Extended Kalman Filter are compared. Based on the results, radars implemented with CKF perform better than the radars implemented with UKF or radars implemented with EKF. Further, radar with EKF has the worst accuracy and has the biggest computation load because of derivation and evaluation of Jacobian matrices. We suggest using the concept of risk management to better control parameters and improve performance in cognitive radar. We believe, spectrum sensing can be seen as a potential interest to be used in cognitive radar and we propose a new approach Probabilistic ICA which will presumably reduce noise based on estimation error in cognitive radar. Parallel computing is a concept based on divide and conquers mechanism, and we suggest using the parallel computing approach in cognitive radar by doing complicated calculations or tasks to reduce processing time.
Classification of Alzheimer's Disease using fMRI Data and Deep Learning Convolutional Neural Networks
Mar 29, 2016



Over the past decade, machine learning techniques especially predictive modeling and pattern recognition in biomedical sciences from drug delivery system to medical imaging has become one of the important methods which are assisting researchers to have deeper understanding of entire issue and to solve complex medical problems. Deep learning is power learning machine learning algorithm in classification while extracting high-level features. In this paper, we used convolutional neural network to classify Alzheimer's brain from normal healthy brain. The importance of classifying this kind of medical data is to potentially develop a predict model or system in order to recognize the type disease from normal subjects or to estimate the stage of the disease. Classification of clinical data such as Alzheimer's disease has been always challenging and most problematic part has been always selecting the most discriminative features. Using Convolutional Neural Network (CNN) and the famous architecture LeNet-5, we successfully classified functional MRI data of Alzheimer's subjects from normal controls where the accuracy of test data on trained data reached 96.85%. This experiment suggests us the shift and scale invariant features extracted by CNN followed by deep learning classification is most powerful method to distinguish clinical data from healthy data in fMRI. This approach also enables us to expand our methodology to predict more complicated systems.