 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic text summarization based on latent semantic analysis to enhance arabic documents clustering
Feb 06, 2013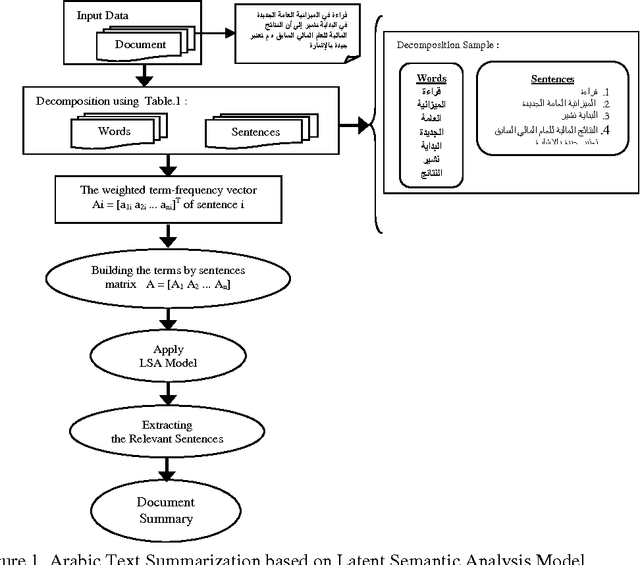

Arabic Documents Clustering is an important task for obtaining good results with the traditional Information Retrieval (IR) systems especially with the rapid growth of the number of online documents present in Arabic language. Documents clustering aim to automatically group similar documents in one cluster using different similarity/distance measures. This task is often affected by the documents length, useful information on the documents is often accompanied by a large amount of noise, and therefore it is necessary to eliminate this noise while keeping useful information to boost the performance of Documents clustering. In this paper, we propose to evaluate the impact of text summarization using the Latent Semantic Analysis Model on Arabic Documents Clustering in order to solve problems cited above, using five similarity/distance measures: Euclidean Distance, Cosine Similarity, Jaccard Coefficient, Pearson Correlation Coefficient and Averaged Kullback-Leibler Divergence, for two times: without and with stemming. Our experimental results indicate that our proposed approach effectively solves the problems of noisy information and documents length, and thus significantly improve the clustering performance.
A comparative study of root-based and stem-based approaches for measuring the similarity between arabic words for arabic text mining applications
Dec 14, 2012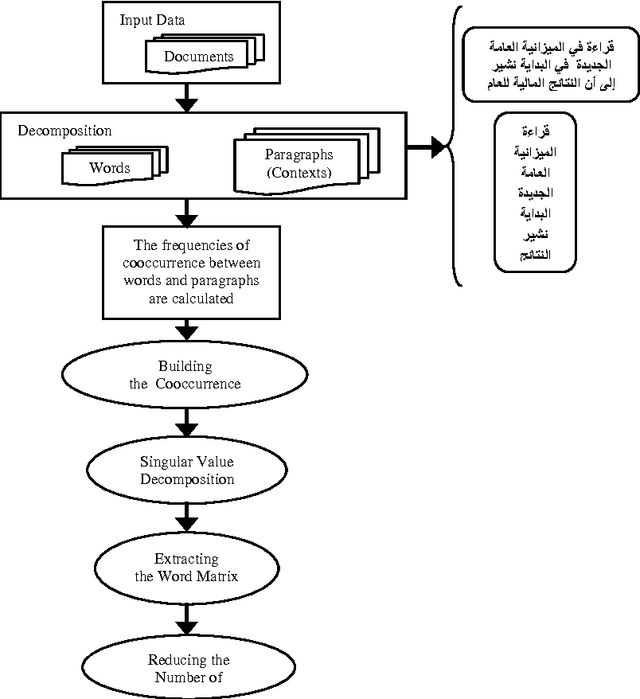
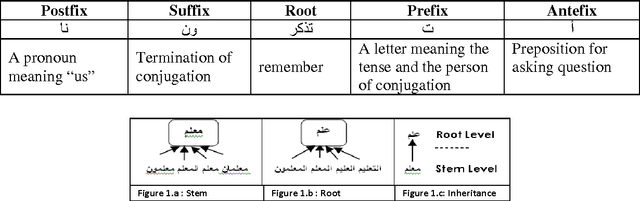
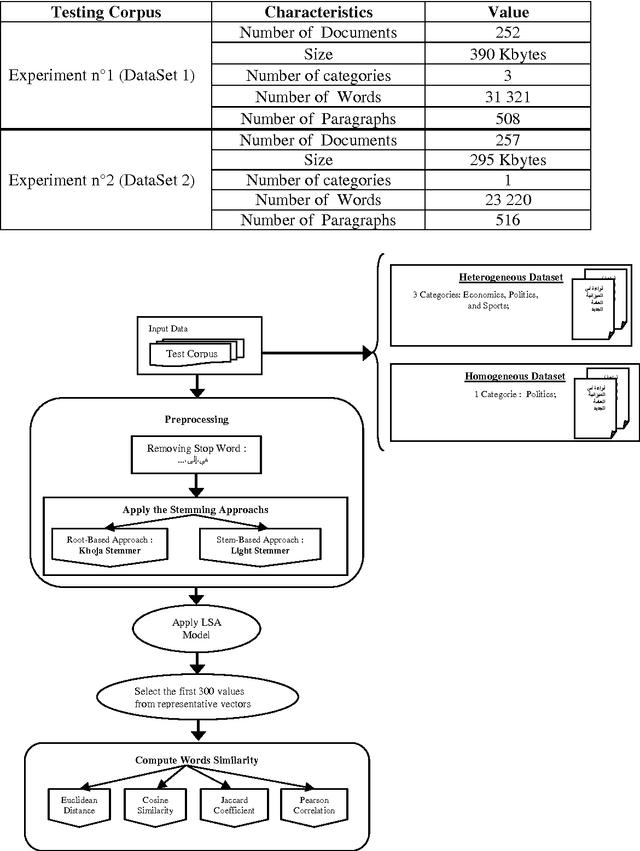
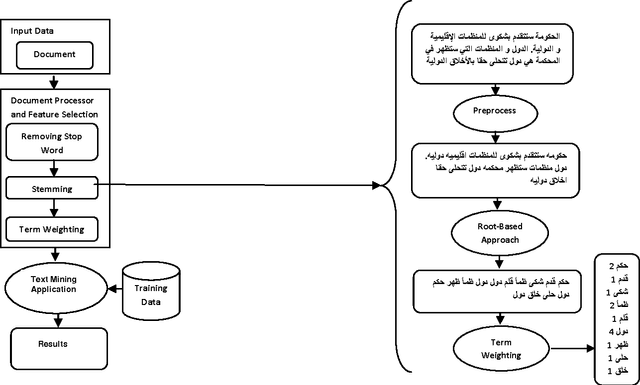
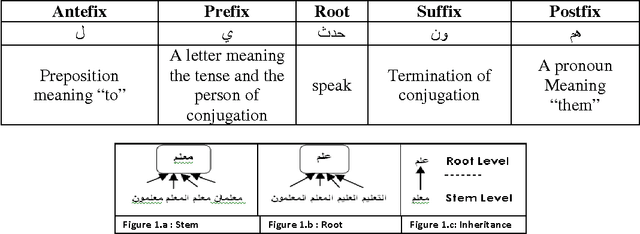
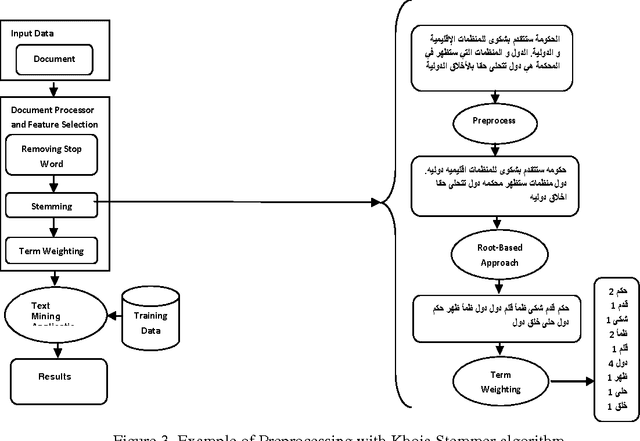
Representation of semantic information contained in the words is needed for any Arabic Text Mining applications. More precisely, the purpose is to better take into account the semantic dependencies between words expressed by the co-occurrence frequencies of these words. There have been many proposals to compute similarities between words based on their distributions in contexts. In this paper, we compare and contrast the effect of two preprocessing techniques applied to Arabic corpus: Rootbased (Stemming), and Stem-based (Light Stemming) approaches for measuring the similarity between Arabic words with the well known abstractive model -Latent Semantic Analysis (LSA)- with a wide variety of distance functions and similarity measures, such as the Euclidean Distance, Cosine Similarity, Jaccard Coefficient, and the Pearson Correlation Coefficient. The obtained results show that, on the one hand, the variety of the corpus produces more accurate results; on the other hand, the Stem-based approach outperformed the Root-based one because this latter affects the words meanings.