 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Improved Metric for Evaluating Disentangled Representations
Oct 04, 2024Disentangled representation learning plays a pivotal role in making representations controllable, interpretable and transferable. Despite its significance in the domain, the quest for reliable and consistent quantitative disentanglement metric remains a major challenge. This stems from the utilisation of diverse metrics measuring different properties and the potential bias introduced by their design. Our work undertakes a comprehensive examination of existing popular disentanglement evaluation metrics, comparing them in terms of measuring aspects of disentanglement (viz. Modularity, Compactness, and Explicitness), detecting the factor-code relationship, and describing the degree of disentanglement. We propose a new framework for quantifying disentanglement, introducing a metric entitled \emph{EDI}, that leverages the intuitive concept of \emph{exclusivity} and improved factor-code relationship to minimize ad-hoc decisions. An in-depth analysis reveals that EDI measures essential properties while offering more stability than existing metrics, advocating for its adoption as a standardised approach.
DriftGAN: Using historical data for Unsupervised Recurring Drift Detection
Jul 09, 2024In real-world applications, input data distributions are rarely static over a period of time, a phenomenon known as concept drift. Such concept drifts degrade the model's prediction performance, and therefore we require methods to overcome these issues. The initial step is to identify concept drifts and have a training method in place to recover the model's performance. Most concept drift detection methods work on detecting concept drifts and signalling the requirement to retrain the model. However, in real-world cases, there could be concept drifts that recur over a period of time. In this paper, we present an unsupervised method based on Generative Adversarial Networks(GAN) to detect concept drifts and identify whether a specific concept drift occurred in the past. Our method reduces the time and data the model requires to get up to speed for recurring drifts. Our key results indicate that our proposed model can outperform the current state-of-the-art models in most datasets. We also test our method on a real-world use case from astrophysics, where we detect the bow shock and magnetopause crossings with better results than the existing methods in the domain.
LLMs in the Loop: Leveraging Large Language Model Annotations for Active Learning in Low-Resource Languages
Apr 02, 2024



Low-resource languages face significant barriers in AI development due to limited linguistic resources and expertise for data labeling, rendering them rare and costly. The scarcity of data and the absence of preexisting tools exacerbate these challenges, especially since these languages may not be adequately represented in various NLP datasets. To address this gap, we propose leveraging the potential of LLMs in the active learning loop for data annotation. Initially, we conduct evaluations to assess inter-annotator agreement and consistency, facilitating the selection of a suitable LLM annotator. The chosen annotator is then integrated into a training loop for a classifier using an active learning paradigm, minimizing the amount of queried data required. Empirical evaluations, notably employing GPT-4-Turbo, demonstrate near-state-of-the-art performance with significantly reduced data requirements, as indicated by estimated potential cost savings of at least 42.45 times compared to human annotation. Our proposed solution shows promising potential to substantially reduce both the monetary and computational costs associated with automation in low-resource settings. By bridging the gap between low-resource languages and AI, this approach fosters broader inclusion and shows the potential to enable automation across diverse linguistic landscapes.
Knowledge distillation with Segment Anything (SAM) model for Planetary Geological Mapping
May 15, 2023



Planetary science research involves analysing vast amounts of remote sensing data, which are often costly and time-consuming to annotate and process. One of the essential tasks in this field is geological mapping, which requires identifying and outlining regions of interest in planetary images, including geological features and landforms. However, manually labelling these images is a complex and challenging task that requires significant domain expertise and effort. To expedite this endeavour, we propose the use of knowledge distillation using the recently introduced cutting-edge Segment Anything (SAM) model. We demonstrate the effectiveness of this prompt-based foundation model for rapid annotation and quick adaptability to a prime use case of mapping planetary skylights. Our work reveals that with a small set of annotations obtained with the right prompts from the model and subsequently training a specialised domain decoder, we can achieve satisfactory semantic segmentation on this task. Key results indicate that the use of knowledge distillation can significantly reduce the effort required by domain experts for manual annotation and improve the efficiency of image segmentation tasks. This approach has the potential to accelerate extra-terrestrial discovery by automatically detecting and segmenting Martian landforms.
Conditional Generative Adversarial Networks for Speed Control in Trajectory Simulation
Mar 21, 2021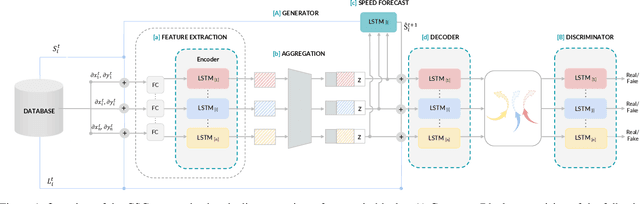
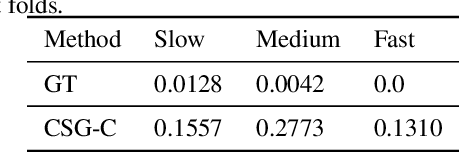
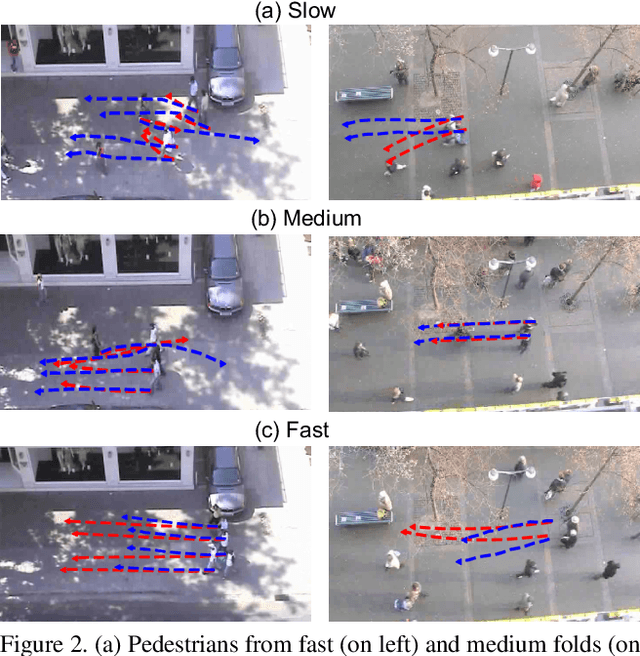
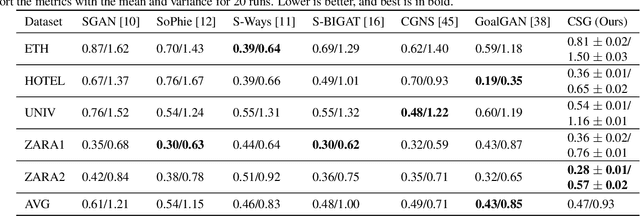
Motion behaviour is driven by several factors -- goals, presence and actions of neighbouring agents, social relations, physical and social norms, the environment with its variable characteristics, and further. Most factors are not directly observable and must be modelled from context. Trajectory prediction, is thus a hard problem, and has seen increasing attention from researchers in the recent years. Prediction of motion, in application, must be realistic, diverse and controllable. In spite of increasing focus on multimodal trajectory generation, most methods still lack means for explicitly controlling different modes of the data generation. Further, most endeavours invest heavily in designing special mechanisms to learn the interactions in latent space. We present Conditional Speed GAN (CSG), that allows controlled generation of diverse and socially acceptable trajectories, based on user controlled speed. During prediction, CSG forecasts future speed from latent space and conditions its generation based on it. CSG is comparable to state-of-the-art GAN methods in terms of the benchmark distance metrics, while being simple and useful for simulation and data augmentation for different contexts such as fast or slow paced environments. Additionally, we compare the effect of different aggregation mechanisms and show that a naive approach of concatenation works comparable to its attention and pooling alternatives.
Lessons Learned from the 1st ARIEL Machine Learning Challenge: Correcting Transiting Exoplanet Light Curves for Stellar Spots
Oct 29, 2020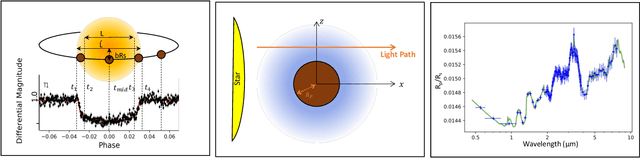

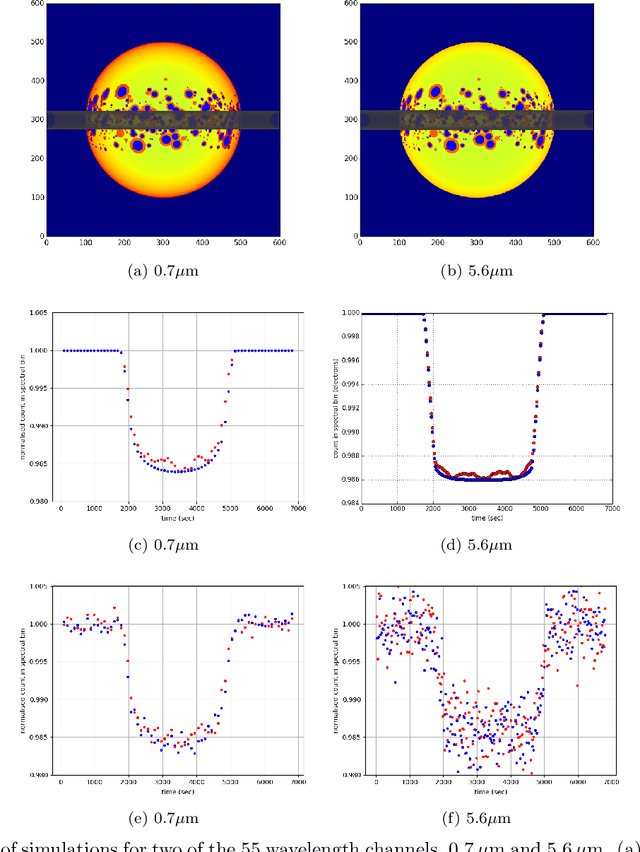
The last decade has witnessed a rapid growth of the field of exoplanet discovery and characterisation. However, several big challenges remain, many of which could be addressed using machine learning methodology. For instance, the most prolific method for detecting exoplanets and inferring several of their characteristics, transit photometry, is very sensitive to the presence of stellar spots. The current practice in the literature is to identify the effects of spots visually and correct for them manually or discard the affected data. This paper explores a first step towards fully automating the efficient and precise derivation of transit depths from transit light curves in the presence of stellar spots. The methods and results we present were obtained in the context of the 1st Machine Learning Challenge organized for the European Space Agency's upcoming Ariel mission. We first present the problem, the simulated Ariel-like data and outline the Challenge while identifying best practices for organizing similar challenges in the future. Finally, we present the solutions obtained by the top-5 winning teams, provide their code and discuss their implications. Successful solutions either construct highly non-linear (w.r.t. the raw data) models with minimal preprocessing -deep neural networks and ensemble methods- or amount to obtaining meaningful statistics from the light curves, constructing linear models on which yields comparably good predictive performance.