 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Solve Fair $k$-Center in Massive Data Models
Feb 24, 2020
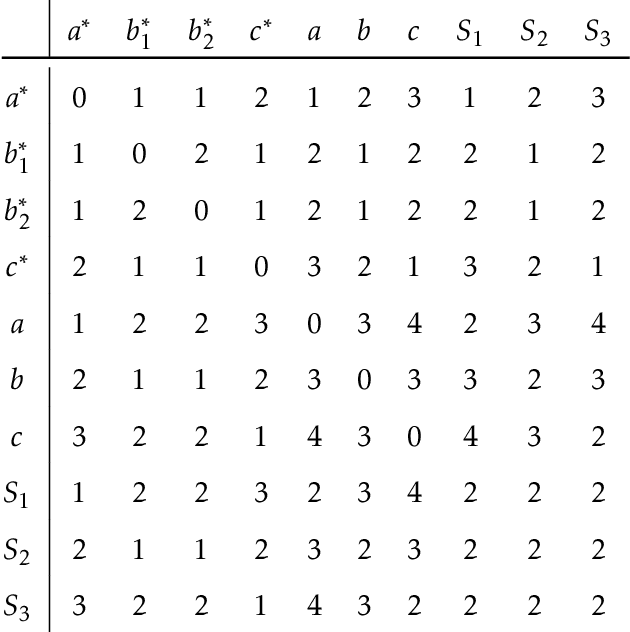
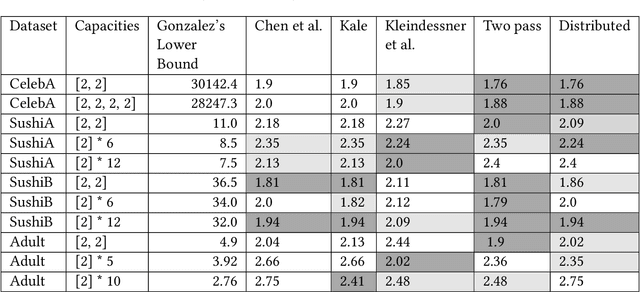
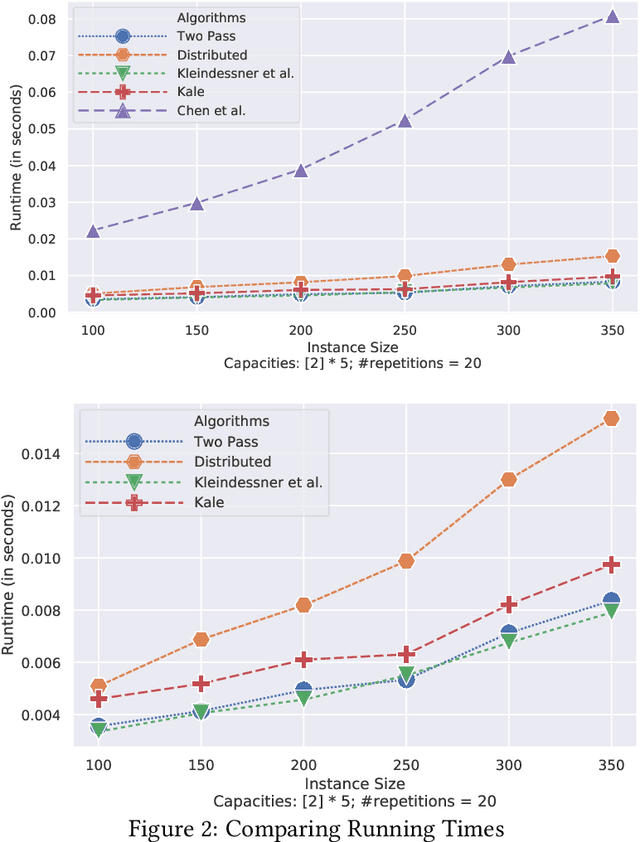
Fueled by massive data, important decision making is being automated with the help of algorithms, therefore, fairness in algorithms has become an especially important research topic. In this work, we design new streaming and distributed algorithms for the fair $k$-center problem that models fair data summarization. The streaming and distributed models of computation have an attractive feature of being able to handle massive data sets that do not fit into main memory. Our main contributions are: (a) the first distributed algorithm; which has provably constant approximation ratio and is extremely parallelizable, and (b) a two-pass streaming algorithm with a provable approximation guarantee matching the best known algorithm (which is not a streaming algorithm). Our algorithms have the advantages of being easy to implement in practice, being fast with linear running times, having very small working memory and communication, and outperforming existing algorithms on several real and synthetic data sets. To complement our distributed algorithm, we also give a hardness result for natural distributed algorithms, which holds for even the special case of $k$-center.
Maximizing a Nonnegative, Monotone, Submodular Function Constrained to Matchings
Jan 10, 2013Submodular functions have many applications. Matchings have many applications. The bitext word alignment problem can be modeled as the problem of maximizing a nonnegative, monotone, submodular function constrained to matchings in a complete bipartite graph where each vertex corresponds to a word in the two input sentences and each edge represents a potential word-to-word translation. We propose a more general problem of maximizing a nonnegative, monotone, submodular function defined on the edge set of a complete graph constrained to matchings; we call this problem the CSM-Matching problem. CSM-Matching also generalizes the maximum-weight matching problem, which has a polynomial-time algorithm; however, we show that it is NP-hard to approximate CSM-Matching within a factor of e/(e-1) by reducing the max k-cover problem to it. Our main result is a simple, greedy, 3-approximation algorithm for CSM-Matching. Then we reduce CSM-Matching to maximizing a nonnegative, monotone, submodular function over two matroids, i.e., CSM-2-Matroids. CSM-2-Matroids has a (2+epsilon)-approximation algorithm - called LSV2. We show that we can find a (4+epsilon)-approximate solution to CSM-Matching using LSV2. We extend this approach to similar problems.