 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial Recognition for Automated Progress Monitoring using Deep Learning Methods
Jun 29, 2020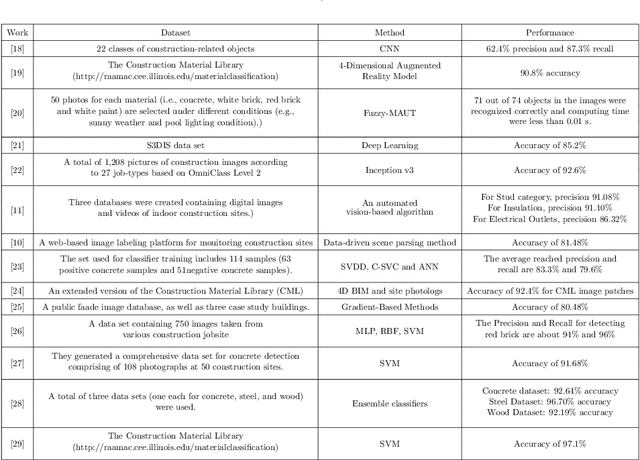

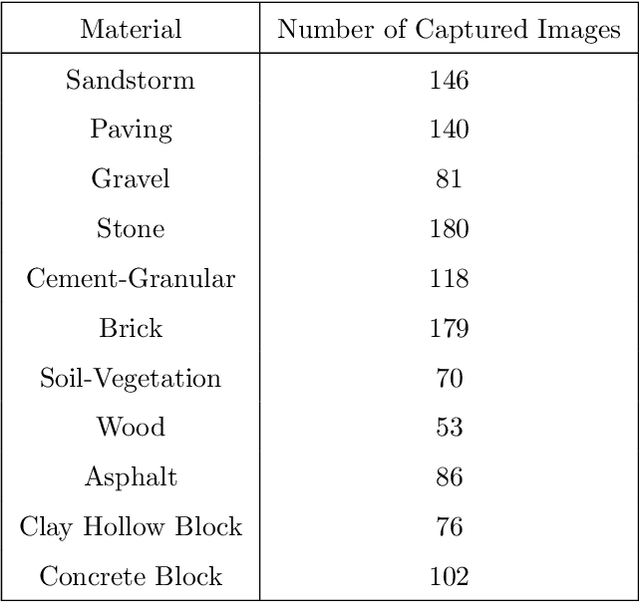
Recent advancements in Artificial intelligence, especially deep learning, has changed many fields irreversibly by introducing state of the art methods for automation. Construction monitoring has not been an exception; as a part of construction monitoring systems, material classification and recognition have drawn the attention of deep learning and machine vision researchers. However, to create production-ready systems, there is still a long path to cover. Real-world problems such as varying illuminations and reaching acceptable accuracies need to be addressed in order to create robust systems. In this paper, we have addressed these issues and reached a state of the art performance, i.e., 97.35% accuracy rate for this task. Also, a new dataset containing 1231 images of 11 classes taken from several construction sites is gathered and publicly published to help other researchers in this field.
Review, Analyze, and Design a Comprehensive Deep Reinforcement Learning Framework
Feb 27, 2020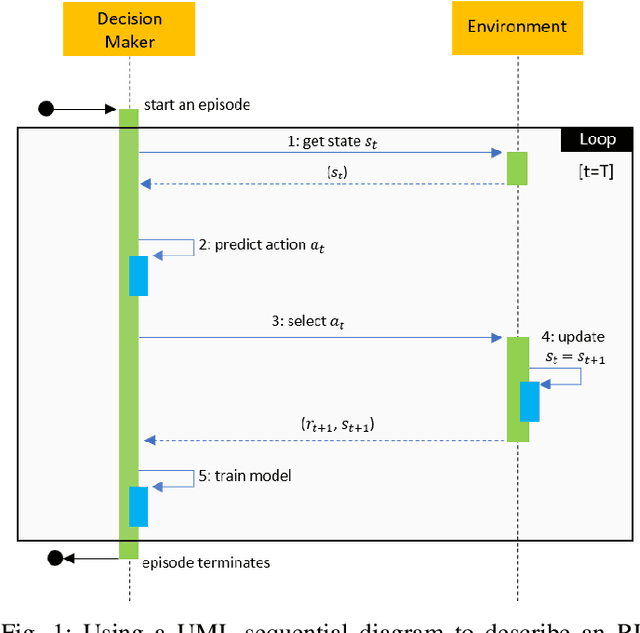
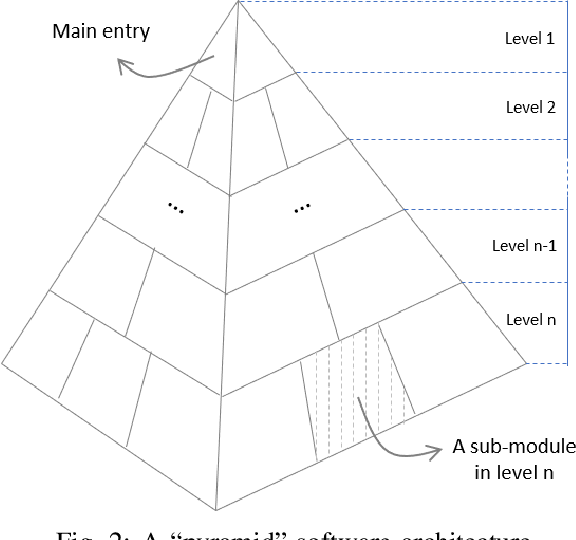
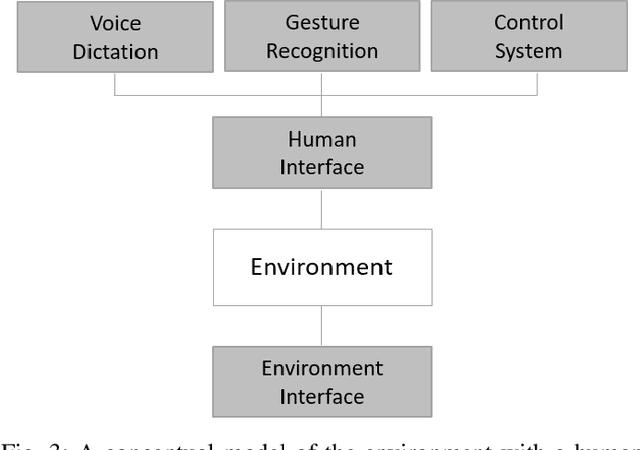
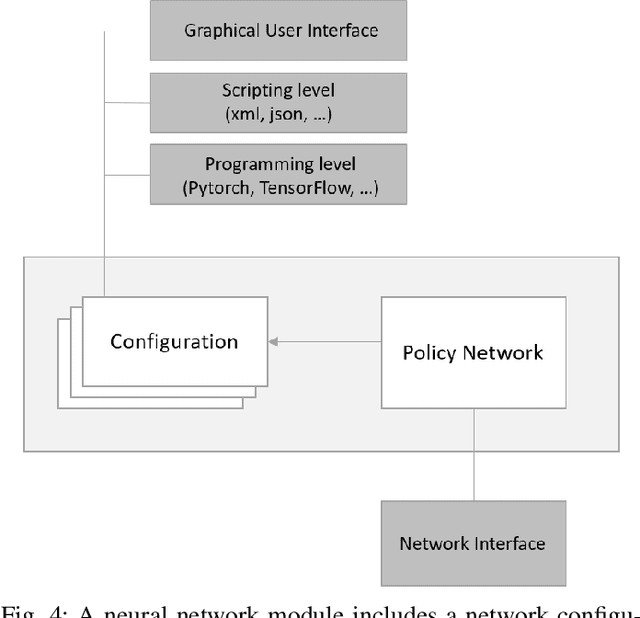
Reinforcement learning (RL) has emerged as a standard approach for building an intelligent system, which involves multiple self-operated agents to collectively accomplish a designated task. More importantly, there has been a great attention to RL since the introduction of deep learning that essentially makes RL feasible to operate in high-dimensional environments. However, current research interests are diverted into different directions, such as multi-agent and multi-objective learning, and human-machine interactions. Therefore, in this paper, we propose a comprehensive software architecture that not only plays a vital role in designing a connect-the-dots deep RL architecture but also provides a guideline to develop a realistic RL application in a short time span. By inheriting the proposed architecture, software managers can foresee any challenges when designing a deep RL-based system. As a result, they can expedite the design process and actively control every stage of software development, which is especially critical in agile development environments. For this reason, we designed a deep RL-based framework that strictly ensures flexibility, robustness, and scalability. Finally, to enforce generalization, the proposed architecture does not depend on a specific RL algorithm, a network configuration, the number of agents, or the type of agents.
A Visual Communication Map for Multi-Agent Deep Reinforcement Learning
Feb 27, 2020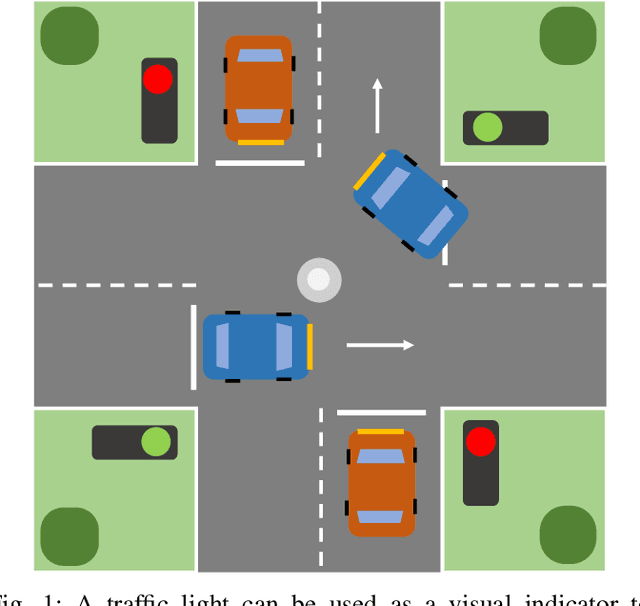
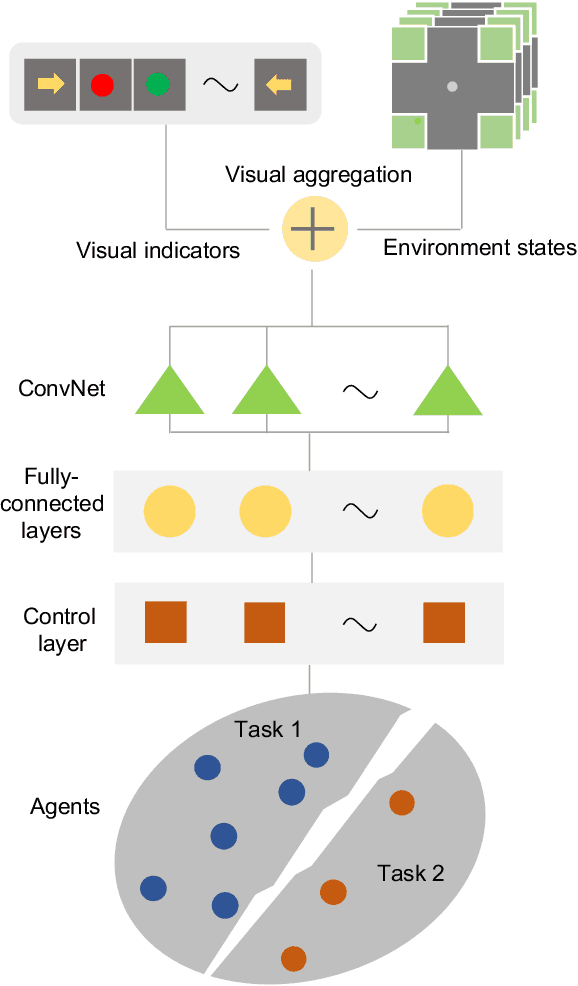

Multi-agent learning distinctly poses significant challenges in the effort to allocate a concealed communication medium. Agents receive thorough knowledge from the medium to determine subsequent actions in a distributed nature. Apparently, the goal is to leverage the cooperation of multiple agents to achieve a designated objective efficiently. Recent studies typically combine a specialized neural network with reinforcement learning to enable communication between agents. This approach, however, limits the number of agents or necessitates the homogeneity of the system. In this paper, we have proposed a more scalable approach that not only deals with a great number of agents but also enables collaboration between dissimilar functional agents and compatibly combined with any deep reinforcement learning methods. Specifically, we create a global communication map to represent the status of each agent in the system visually. The visual map and the environmental state are fed to a shared-parameter network to train multiple agents concurrently. Finally, we select the Asynchronous Advantage Actor-Critic (A3C) algorithm to demonstrate our proposed scheme, namely Visual communication map for Multi-agent A3C (VMA3C). Simulation results show that the use of visual communication map improves the performance of A3C regarding learning speed, reward achievement, and robustness in multi-agent problems.
Optimal Uncertainty-guided Neural Network Training
Dec 30, 2019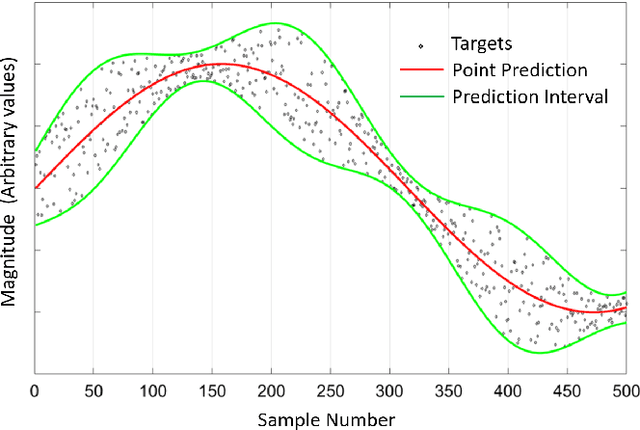
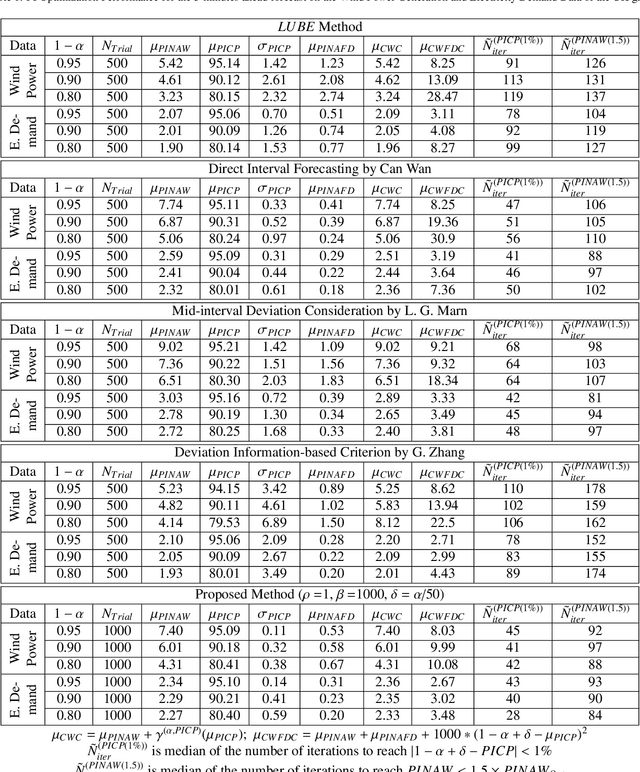
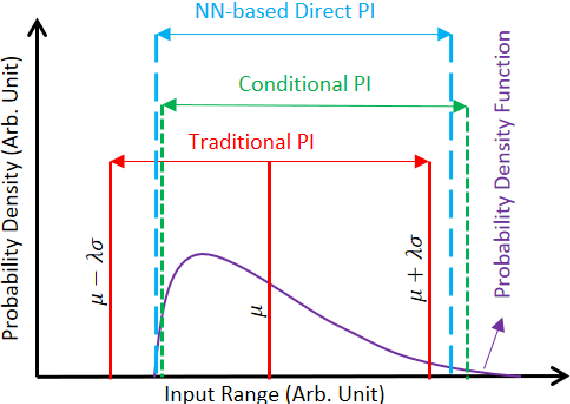
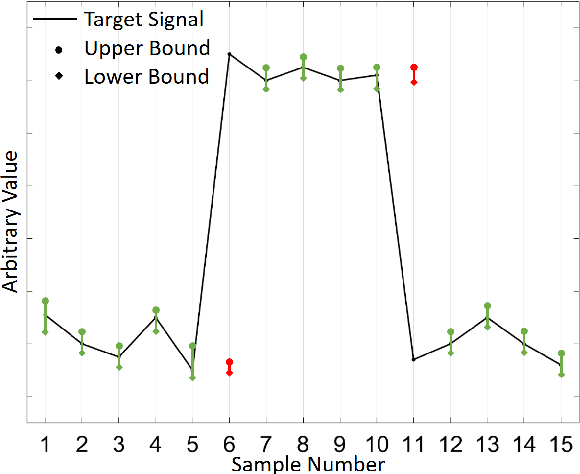
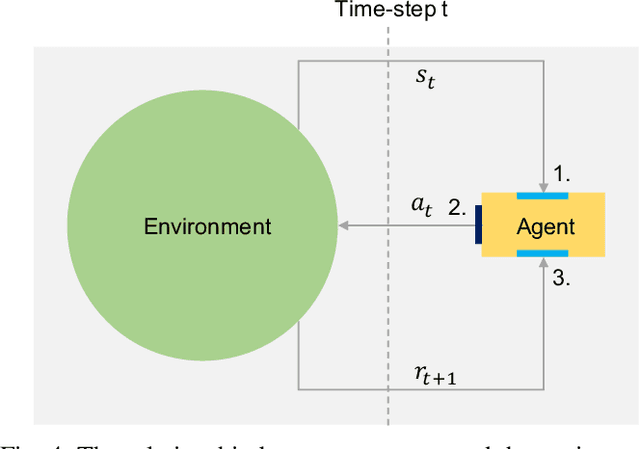
The neural network (NN)-based direct uncertainty quantification (UQ) methods have achieved the state of the art performance since the first inauguration, known as the lower-upper-bound estimation (LUBE) method. However, currently-available cost functions for uncertainty guided NN training are not always converging and all converged NNs are not generating optimized prediction intervals (PIs). Moreover, several groups have proposed different quality criteria for PIs. These raise a question about their relative effectiveness. Most of the existing cost functions of uncertainty guided NN training are not customizable and the convergence of training is uncertain. Therefore, in this paper, we propose a highly customizable smooth cost function for developing NNs to construct optimal PIs. The optimized average width of PIs, PI-failure distances and the PI coverage probability (PICP) are computed for the test dataset. The performance of the proposed method is examined for the wind power generation and the electricity demand data. Results show that the proposed method reduces variation in the quality of PIs, accelerates the training, and improves convergence probability from 99.2% to 99.8%.
Deep Learning for Deepfakes Creation and Detection
Sep 25, 2019
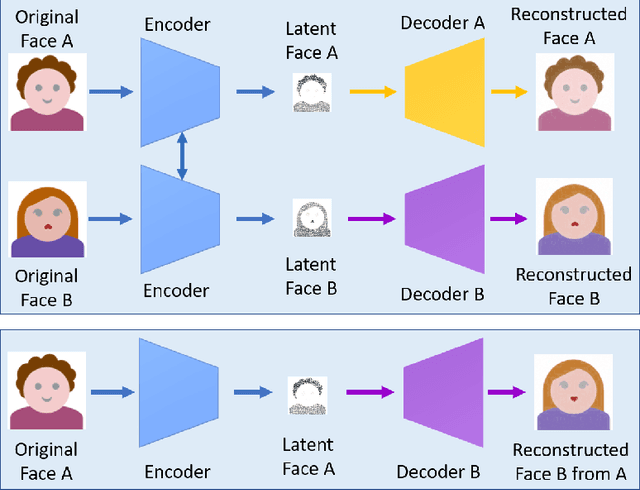
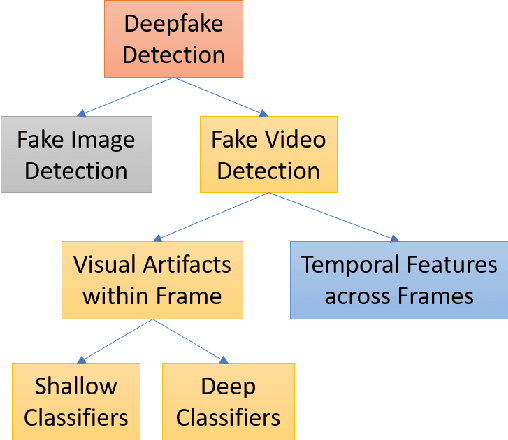
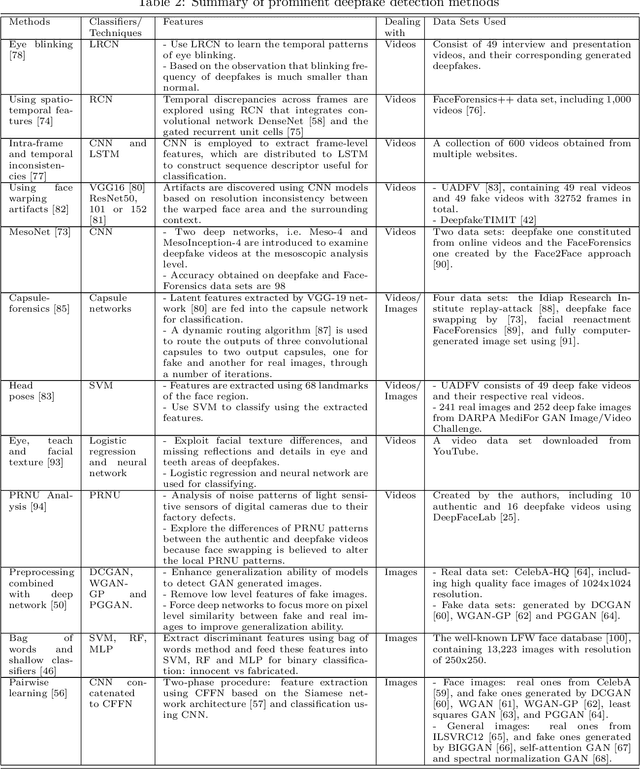
Deep learning has been successfully applied to solve various complex problems ranging from big data analytics to computer vision and human-level control. Deep learning advances however have also been employed to create software that can cause threats to privacy, democracy and national security. One of those deep learning-powered applications recently emerged is "deepfake". Deepfake algorithms can create fake images and videos that humans cannot distinguish them from authentic ones. The proposal of technologies that can automatically detect and assess the integrity of digital visual media is therefore indispensable. This paper presents a survey of algorithms used to create deepfakes and, more importantly, methods proposed to detect deepfakes in the literature to date. We present extensive discussions on challenges, research trends and directions related to deepfake technologies. By reviewing the background of deepfakes and state-of-the-art deepfake detection methods, this study provides a comprehensive overview of deepfake techniques and facilitates the development of new and more robust methods to deal with the increasingly challenging deepfakes.
Real-time Intent Prediction of Pedestrians for Autonomous Ground Vehicles via Spatio-Temporal DenseNet
Apr 22, 2019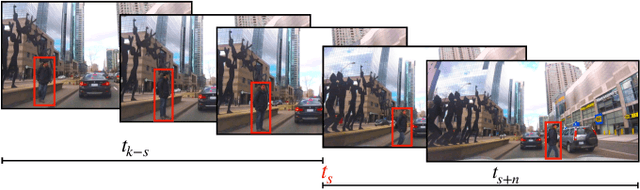
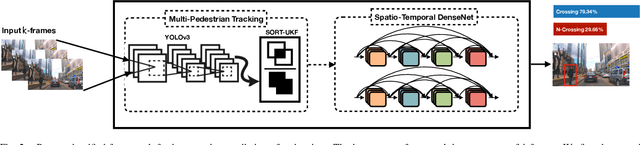
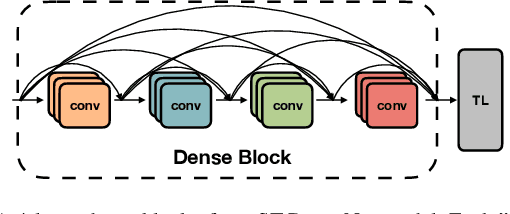
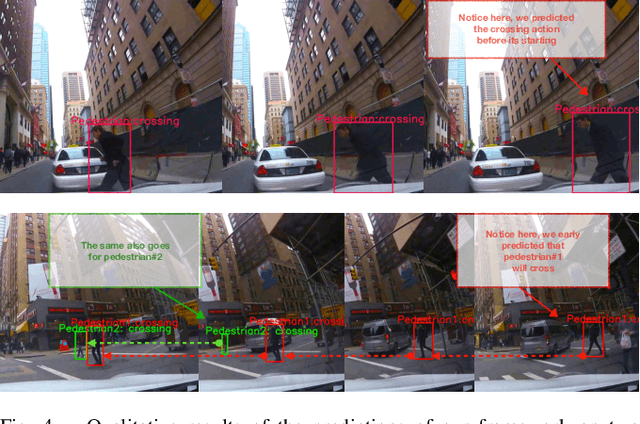
Understanding the behaviors and intentions of humans are one of the main challenges autonomous ground vehicles still faced with. More specifically, when it comes to complex environments such as urban traffic scenes, inferring the intentions and actions of vulnerable road users such as pedestrians become even harder. In this paper, we address the problem of intent action prediction of pedestrians in urban traffic environments using only image sequences from a monocular RGB camera. We propose a real-time framework that can accurately detect, track and predict the intended actions of pedestrians based on a tracking-by-detection technique in conjunction with a novel spatio-temporal DenseNet model. We trained and evaluated our framework based on real data collected from urban traffic environments. Our framework has shown resilient and competitive results in comparison to other baseline approaches. Overall, we achieved an average precision score of 84.76% with a real-time performance at 20 FPS.
Realistic Hair Simulation Using Image Blending
Apr 19, 2019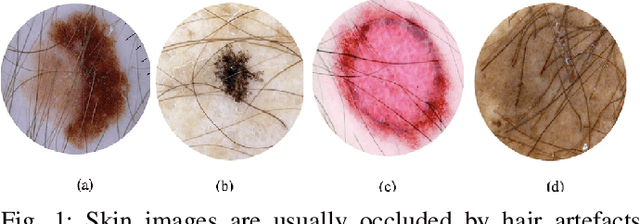

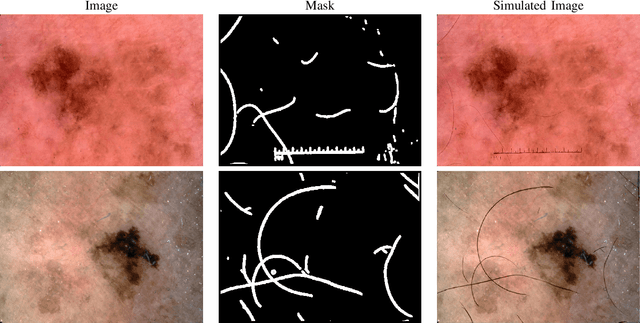
In this presented work, we propose a realistic hair simulator using image blending for dermoscopic images. This hair simulator can be used for benchmarking and validation of the hair removal methods and in data augmentation for improving computer aided diagnostic tools. We adopted one of the popular implementation of image blending to superimpose realistic hair masks to hair lesion. This method was able to produce realistic hair masks according to a predefined mask for hair. Thus, the produced hair images and masks can be used as ground truth for hair segmentation and removal methods by inpainting hair according to a pre-defined hair masks on hairfree areas. Also, we achieved a realism score equals to 1.65 in comparison to 1.59 for the state-of-the-art hair simulator.
Manipulating Soft Tissues by Deep Reinforcement Learning for Autonomous Robotic Surgery
Feb 14, 2019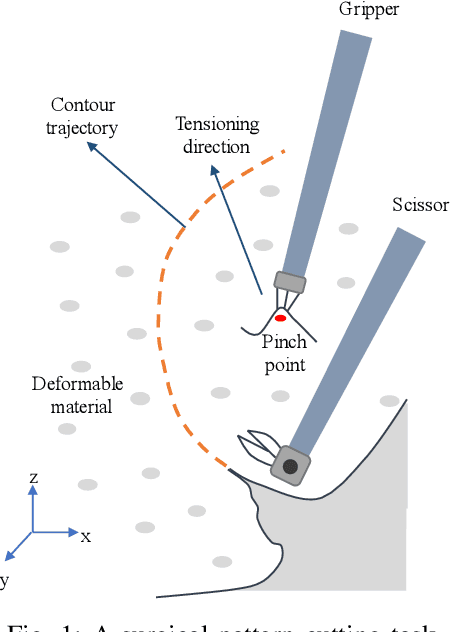
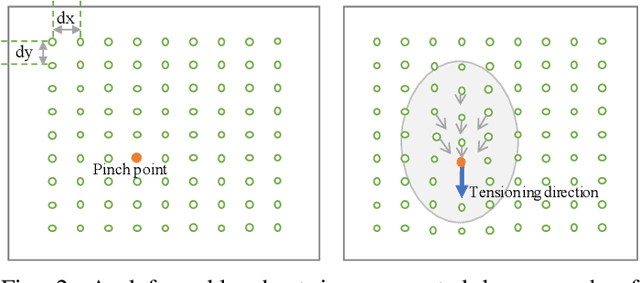
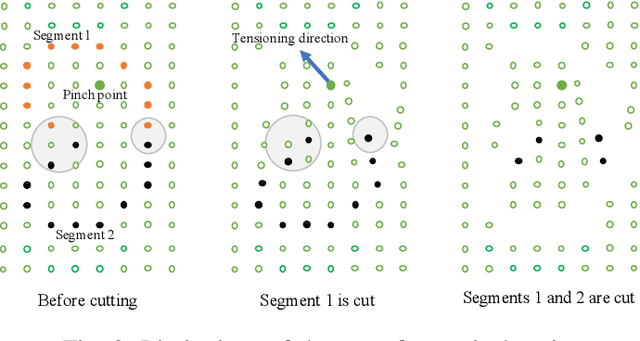
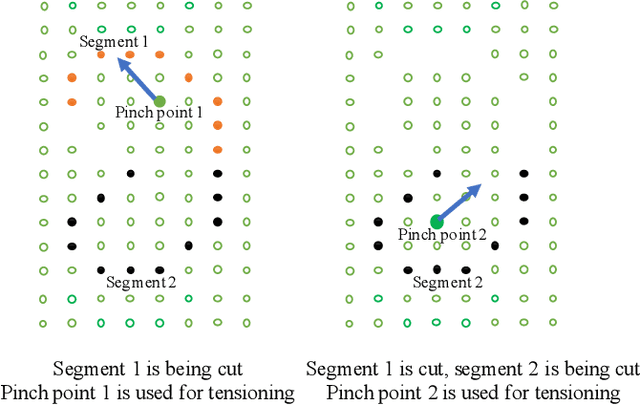
In robotic surgery, pattern cutting through a deformable material is a challenging research field. The cutting procedure requires a robot to concurrently manipulate a scissor and a gripper to cut through a predefined contour trajectory on the deformable sheet. The gripper ensures the cutting accuracy by nailing a point on the sheet and continuously tensioning the pinch point to different directions while the scissor is in action. The goal is to find a pinch point and a corresponding tensioning policy to minimize damage to the material and increase cutting accuracy measured by the symmetric difference between the predefined contour and the cut contour. Previous study considers finding one fixed pinch point during the course of cutting, which is inaccurate and unsafe when the contour trajectory is complex. In this paper, we examine the soft tissue cutting task by using multiple pinch points, which imitates human operations while cutting. This approach, however, does not require the use of a multi-gripper robot. We use a deep reinforcement learning algorithm to find an optimal tensioning policy of a pinch point. Simulation results show that the multi-point approach outperforms the state-of-the-art method in soft pattern cutting task with respect to both accuracy and reliability.
A New Tensioning Method using Deep Reinforcement Learning for Surgical Pattern Cutting
Jan 10, 2019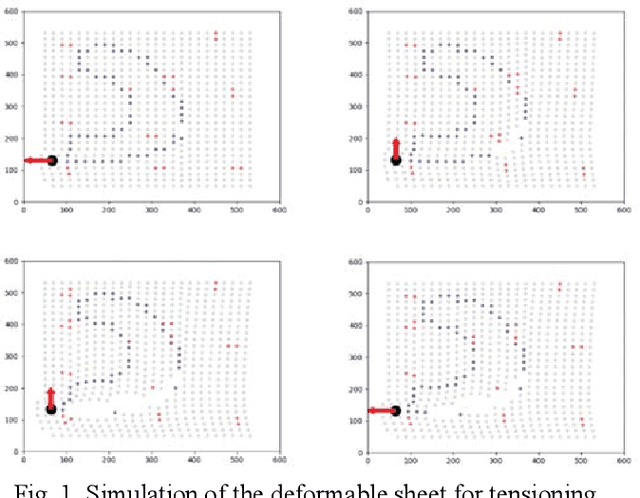
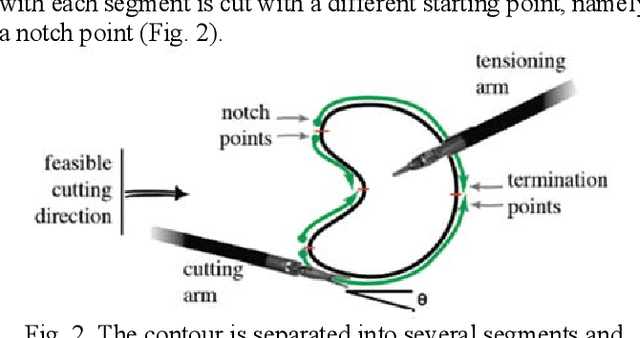
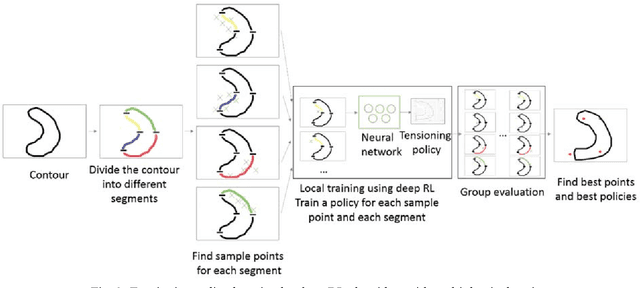
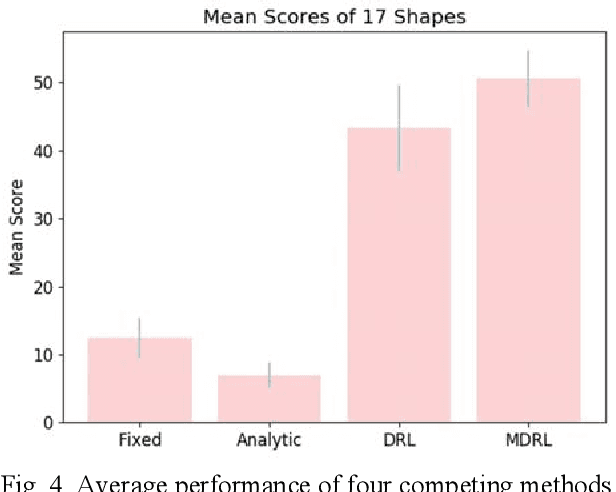
Surgeons normally need surgical scissors and tissue grippers to cut through a deformable surgical tissue. The cutting accuracy depends on the skills to manipulate these two tools. Such skills are part of basic surgical skills training as in the Fundamentals of Laparoscopic Surgery. The gripper is used to pinch a point on the surgical sheet and pull the tissue to a certain direction to maintain the tension while the scissors cut through a trajectory. As the surgical materials are deformable, it requires a comprehensive tensioning policy to yield appropriate tensioning direction at each step of the cutting process. Automating a tensioning policy for a given cutting trajectory will support not only the human surgeons but also the surgical robots to improve the cutting accuracy and reliability. This paper presents a multiple pinch point approach to modelling an autonomous tensioning planner based on a deep reinforcement learning algorithm. Experiments on a simulator show that the proposed method is superior to existing methods in terms of both performance and robustness.
Deep Reinforcement Learning for Multi-Agent Systems: A Review of Challenges, Solutions and Applications
Dec 31, 2018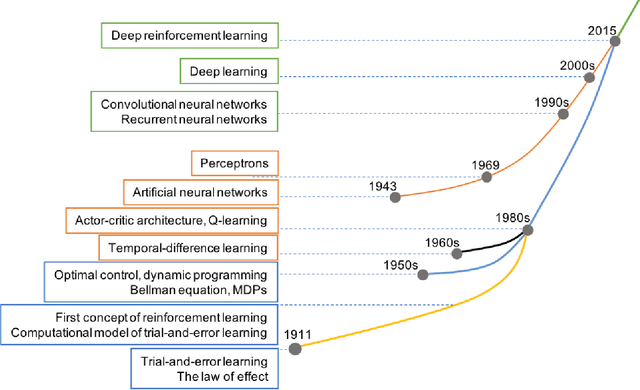
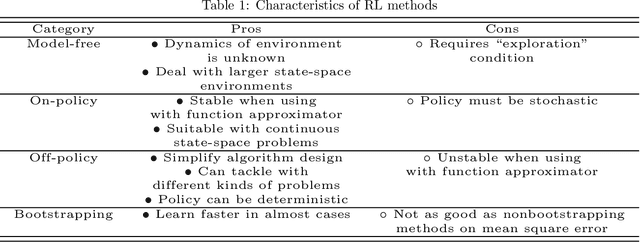
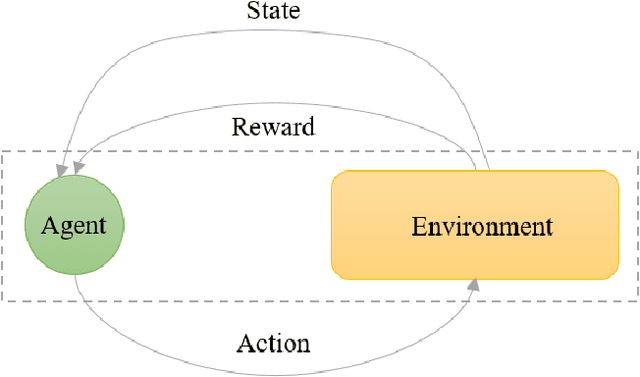

Reinforcement learning (RL) algorithms have been around for decades and been employed to solve various sequential decision-making problems. These algorithms however have faced great challenges when dealing with high-dimensional environments. The recent development of deep learning has enabled RL methods to drive optimal policies for sophisticated and capable agents, which can perform efficiently in these challenging environments. This paper addresses an important aspect of deep RL related to situations that demand multiple agents to communicate and cooperate to solve complex tasks. A survey of different approaches to problems related to multi-agent deep RL (MADRL) is presented, including non-stationarity, partial observability, continuous state and action spaces, multi-agent training schemes, multi-agent transfer learning. The merits and demerits of the reviewed methods will be analyzed and discussed, with their corresponding applications explored. It is envisaged that this review provides insights about various MADRL methods and can lead to future development of more robust and highly useful multi-agent learning methods for solving real-world problems.