 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Measuring of Readability to Improve Documents Accessibility for Arabic Language Learners
Sep 09, 2021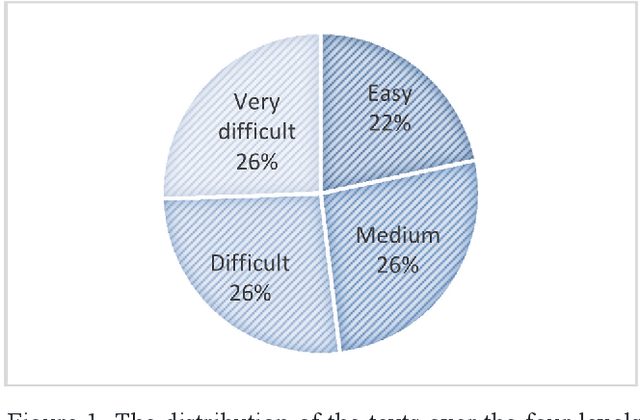
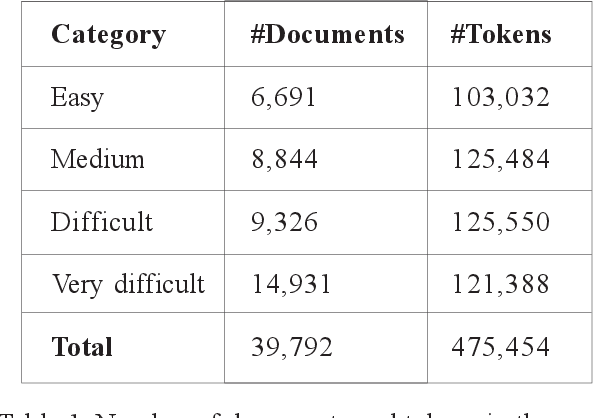
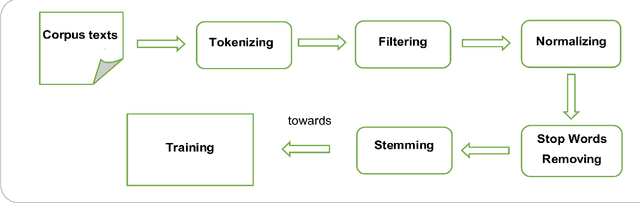
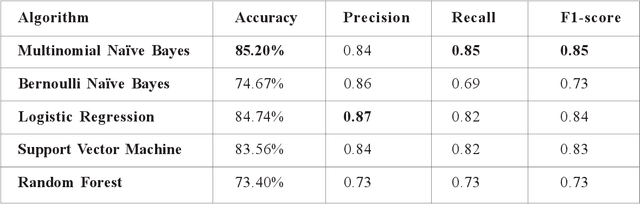
This paper presents an approach based on supervised machine learning methods to build a classifier that can identify text complexity in order to present Arabic language learners with texts suitable to their levels. The approach is based on machine learning classification methods to discriminate between the different levels of difficulty in reading and understanding a text. Several models were trained on a large corpus mined from online Arabic websites and manually annotated. The model uses both Count and TF-IDF representations and applies five machine learning algorithms; Multinomial Naive Bayes, Bernoulli Naive Bayes, Logistic Regression, Support Vector Machine and Random Forest, using unigrams and bigrams features. With the goal of extracting the text complexity, the problem is usually addressed by formulating the level identification as a classification task. Experimental results showed that n-gram features could be indicative of the reading level of a text and could substantially improve performance, and showed that SVM and Multinomial Naive Bayes are the most accurate in predicting the complexity level. Best results were achieved using TF-IDF Vectors trained by a combination of word-based unigrams and bigrams with an overall accuracy of 87.14% over four classes of complexity.
Contribution au Niveau de l'Approche Indirecte à Base de Transfert dans la Traduction Automatique
Nov 16, 2019


In this thesis, we address several important issues concerning the morphological analysis of Arabic language applied to textual data and machine translation. First, we provided an overview on machine translation, its history and its development, then we exposed human translation techniques for eventual inspiration in machine translation, and we exposed linguistic approaches and particularly indirect transfer approaches. Finally, we presented our contributions to the resolution of morphosyntactic problems in computer linguistics as multilingual information retrieval and machine translation. As a first contribution, we developed a morphological analyzer for Arabic, and we have exploited it in the bilingual information retrieval such as a computer application of multilingual documentary. Results validation showed a statistically significant performance. In a second contribution, we proposed a list of morphosyntactic transfer rules from English to Arabic for translation in three phases: analysis, transfer, generation. We focused on the transfer phase without semantic distortion for an abstraction of English in a sufficient subset of Arabic.
* in French
Un systeme de lemmatisation pour les applications de TALN
Nov 16, 2019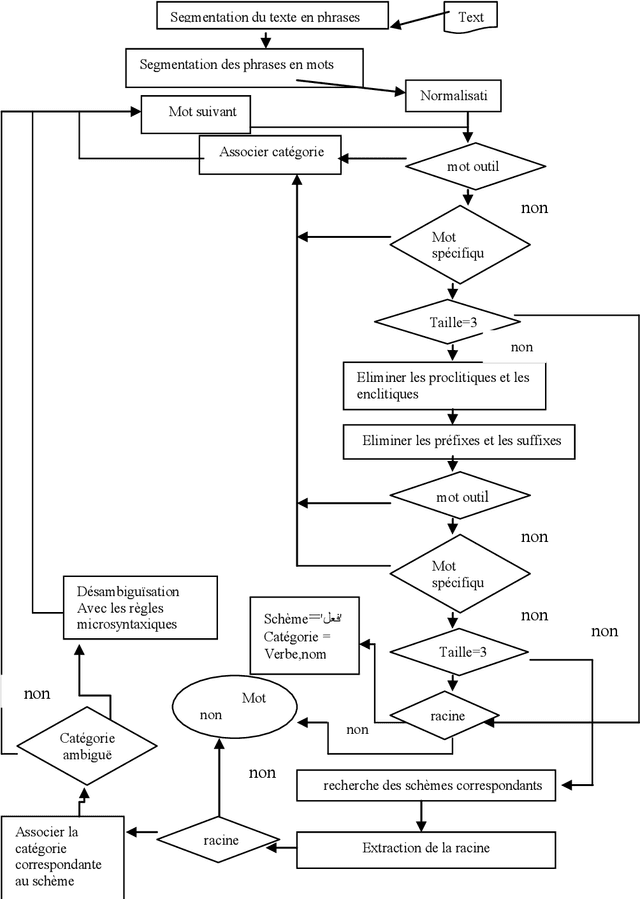

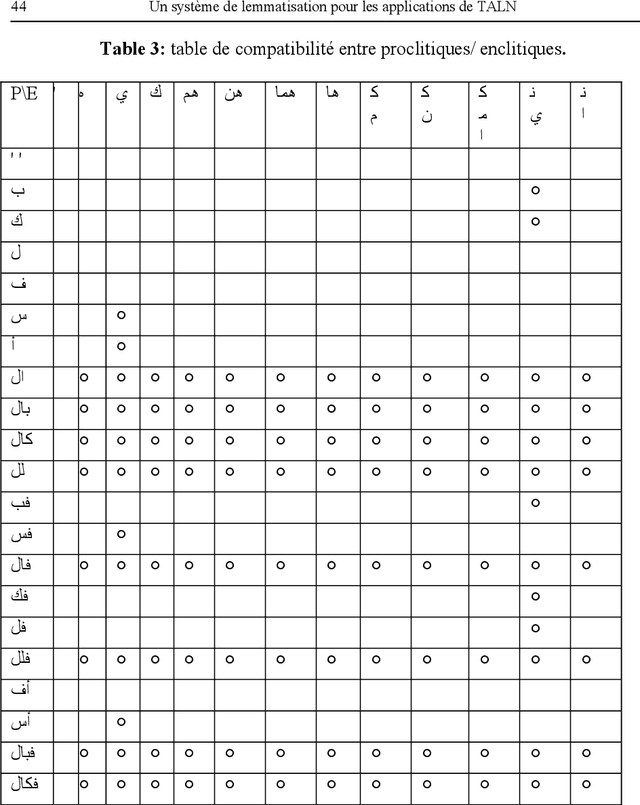
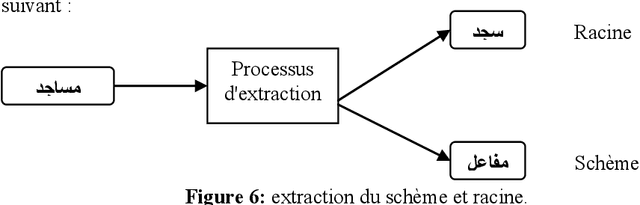
This paper presents a method of stemming for the Arabian texts based on the linguistic techniques of the natural language processing. This method leans on the notion of scheme (one of the strong points of the morphology of the Arabian language). The advantage of this approach is that it doesn't use a dictionary of inflexions but a smart dynamic recognition of the different words of the language.
An Accuracy-Enhanced Stemming Algorithm for Arabic Information Retrieval
Nov 15, 2019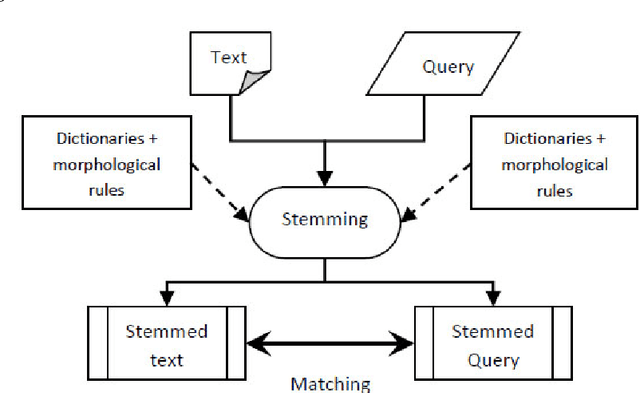
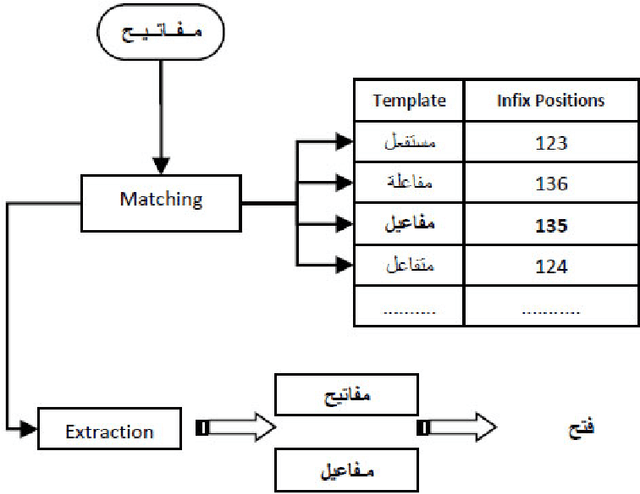
This paper provides a method for indexing and retrieving Arabic texts, based on natural language processing. Our approach exploits the notion of template in word stemming and replaces the words by their stems. This technique has proven to be effective since it has returned significant relevant retrieval results by decreasing silence during the retrieval phase. Series of experiments have been conducted to test the performance of the proposed algorithm ESAIR (Enhanced Stemmer for Arabic Information Retrieval). The results obtained indicate that the algorithm extracts the exact root with an accuracy rate up to 96% and hence, improving information retrieval.
Subjective Sentiment Analysis for Arabic Newswire Comments
Nov 09, 2019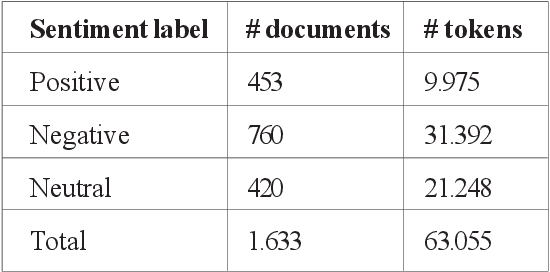
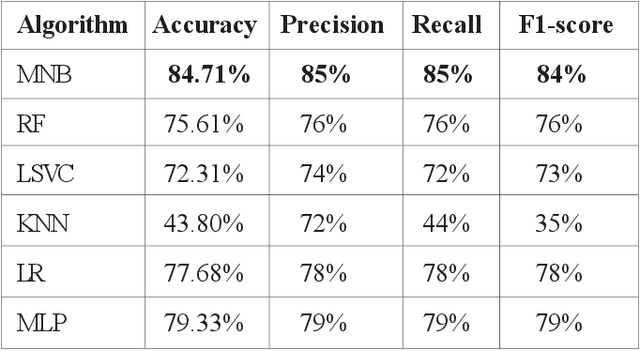
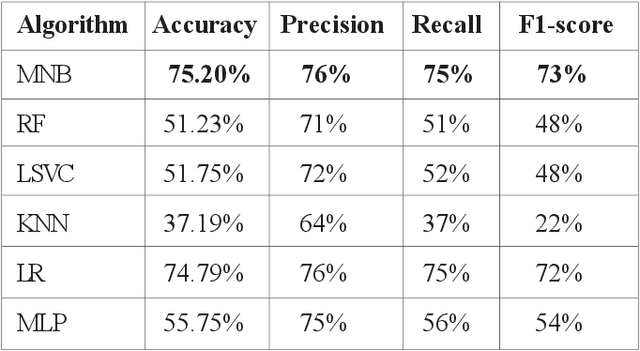
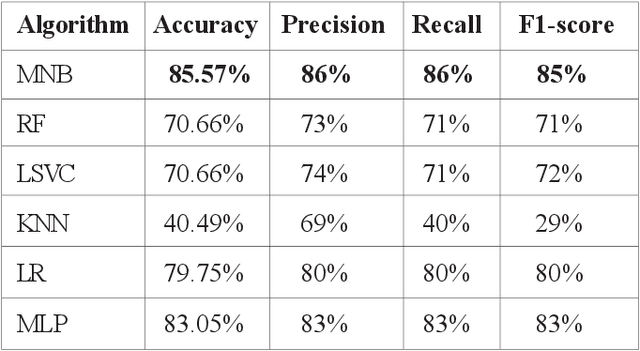
This paper presents an approach based on supervised machine learning methods to discriminate between positive, negative and neutral Arabic reviews in online newswire. The corpus is labeled for subjectivity and sentiment analysis (SSA) at the sentence-level. The model uses both count and TF-IDF representations and apply six machine learning algorithms; Multinomial Naive Bayes, Support Vector Machines (SVM), Random Forest, Logistic Regression, Multi-layer perceptron and k-nearest neighbors using uni-grams, bi-grams features. With the goal of extracting users sentiment from written text. Experimental results showed that n-gram features could substantially improve performance; and showed that the Multinomial Naive Bayes approach is the most accurate in predicting topic polarity. Best results were achieved using count vectors trained by combination of word-based uni-grams and bi-grams with an overall accuracy of 85.57% over two classes and 65.64% over three classes.
* 7 pages, 7 tables, article in journal