 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Machine Learning Reconstruction Techniques for Accelerated Brain MRI Scans
Sep 08, 2025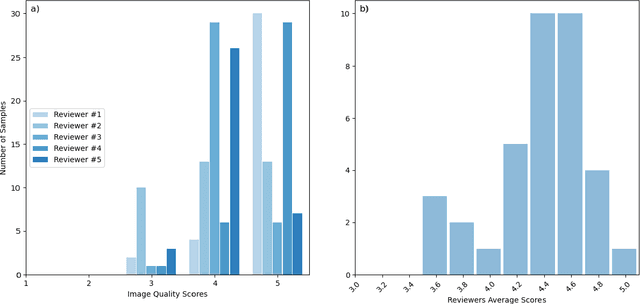
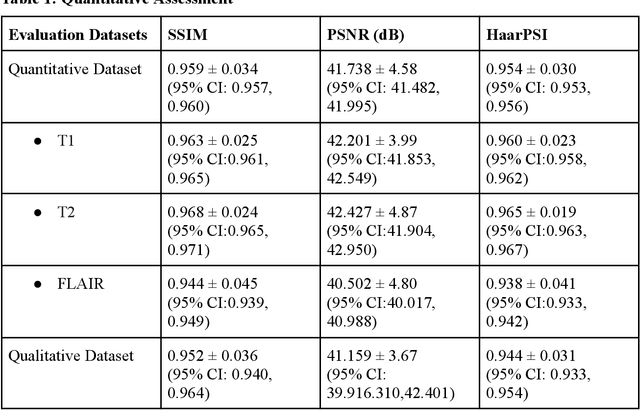
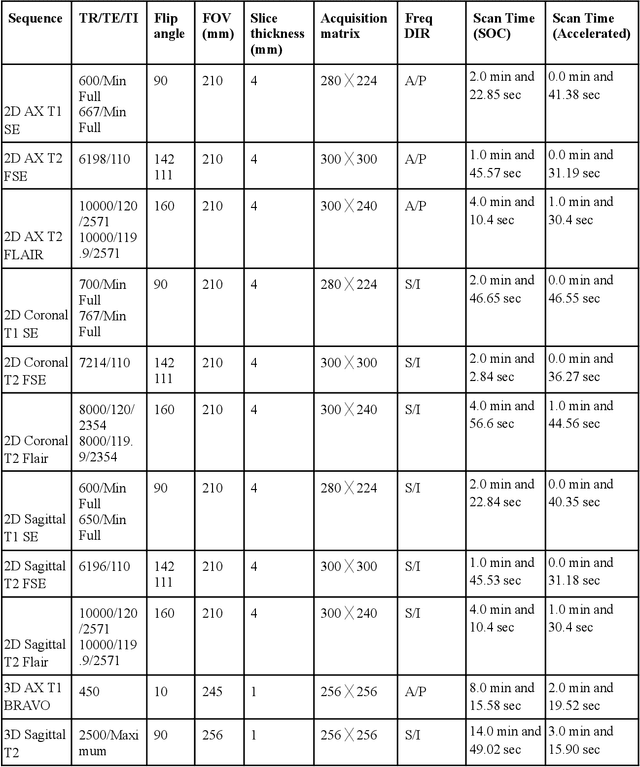
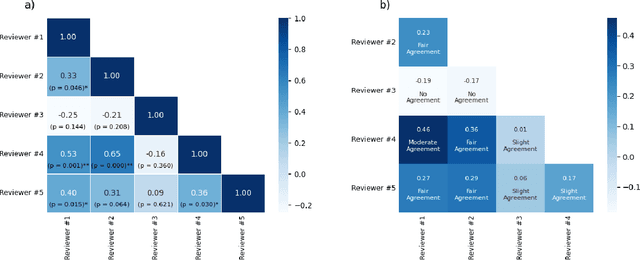
This retrospective-prospective study evaluated whether a deep learning-based MRI reconstruction algorithm can preserve diagnostic quality in brain MRI scans accelerated up to fourfold, using both public and prospective clinical data. The study included 18 healthy volunteers (scans acquired at 3T, January 2024-March 2025), as well as selected fastMRI public datasets with diverse pathologies. Phase-encoding-undersampled 2D/3D T1, T2, and FLAIR sequences were reconstructed with DeepFoqus-Accelerate and compared with standard-of-care (SOC). Three board-certified neuroradiologists and two MRI technologists independently reviewed 36 paired SOC/AI reconstructions from both datasets using a 5-point Likert scale, while quantitative similarity was assessed for 408 scans and 1224 datasets using Structural Similarity Index (SSIM), Peak Signal-to-Noise Ratio (PSNR), and Haar wavelet-based Perceptual Similarity Index (HaarPSI). No AI-reconstructed scan scored below 3 (minimally acceptable), and 95% scored $\geq 4$. Mean SSIM was 0.95 $\pm$ 0.03 (90% cases >0.90), PSNR >41.0 dB, and HaarPSI >0.94. Inter-rater agreement was slight to moderate. Rare artifacts did not affect diagnostic interpretation. These findings demonstrate that DeepFoqus-Accelerate enables robust fourfold brain MRI acceleration with 75% reduced scan time, while preserving diagnostic image quality and supporting improved workflow efficiency.
Automated Fake News Detection using cross-checking with reliable sources
Jan 01, 2022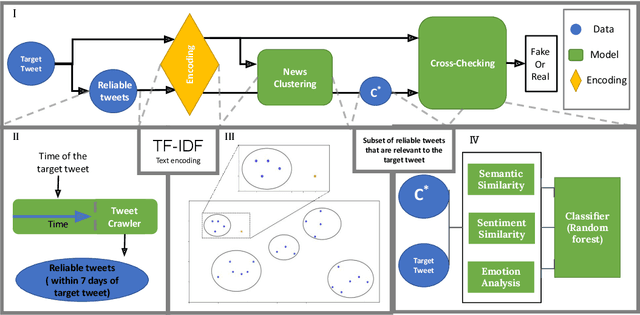
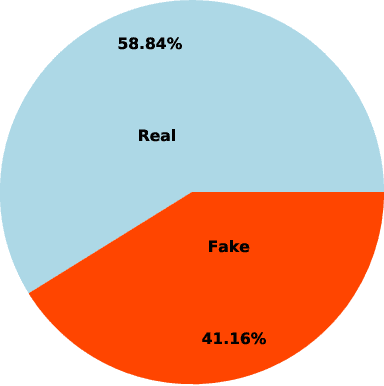
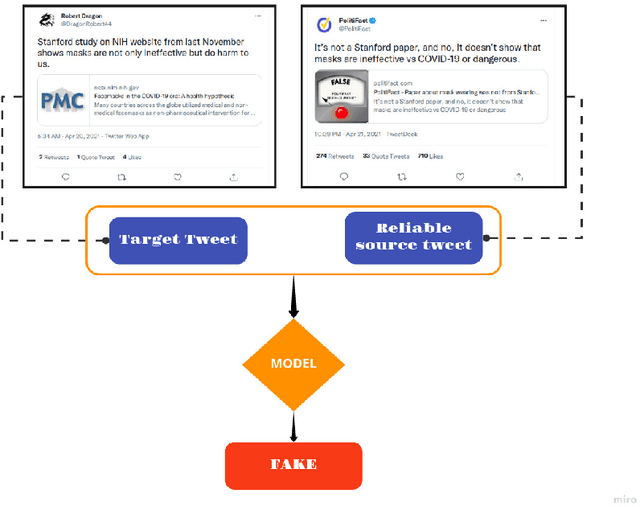
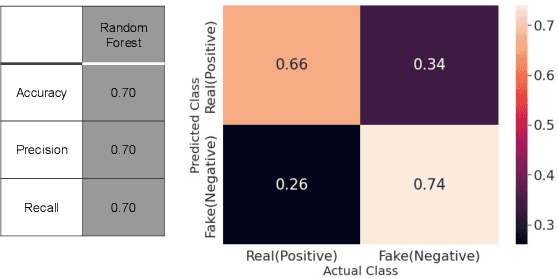
Over the past decade, fake news and misinformation have turned into a major problem that has impacted different aspects of our lives, including politics and public health. Inspired by natural human behavior, we present an approach that automates the detection of fake news. Natural human behavior is to cross-check new information with reliable sources. We use Natural Language Processing (NLP) and build a machine learning (ML) model that automates the process of cross-checking new information with a set of predefined reliable sources. We implement this for Twitter and build a model that flags fake tweets. Specifically, for a given tweet, we use its text to find relevant news from reliable news agencies. We then train a Random Forest model that checks if the textual content of the tweet is aligned with the trusted news. If it is not, the tweet is classified as fake. This approach can be generally applied to any kind of information and is not limited to a specific news story or a category of information. Our implementation of this approach gives a $70\%$ accuracy which outperforms other generic fake-news classification models. These results pave the way towards a more sensible and natural approach to fake news detection.