 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Controllable Image Generation by Explicit Spatial Constraint Enforcement
Jan 02, 2025



Recent text-to-image generation favors various forms of spatial conditions, e.g., masks, bounding boxes, and key points. However, the majority of the prior art requires form-specific annotations to fine-tune the original model, leading to poor test-time generalizability. Meanwhile, existing training-free methods work well only with simplified prompts and spatial conditions. In this work, we propose a novel yet generic test-time controllable generation method that aims at natural text prompts and complex conditions. Specifically, we decouple spatial conditions into semantic and geometric conditions and then enforce their consistency during the image-generation process individually. As for the former, we target bridging the gap between the semantic condition and text prompts, as well as the gap between such condition and the attention map from diffusion models. To achieve this, we propose to first complete the prompt w.r.t. semantic condition, and then remove the negative impact of distracting prompt words by measuring their statistics in attention maps as well as distances in word space w.r.t. this condition. To further cope with the complex geometric conditions, we introduce a geometric transform module, in which Region-of-Interests will be identified in attention maps and further used to translate category-wise latents w.r.t. geometric condition. More importantly, we propose a diffusion-based latents-refill method to explicitly remove the impact of latents at the RoI, reducing the artifacts on generated images. Experiments on Coco-stuff dataset showcase 30$\%$ relative boost compared to SOTA training-free methods on layout consistency evaluation metrics.
InfAnFace: Bridging the infant-adult domain gap in facial landmark estimation in the wild
Oct 17, 2021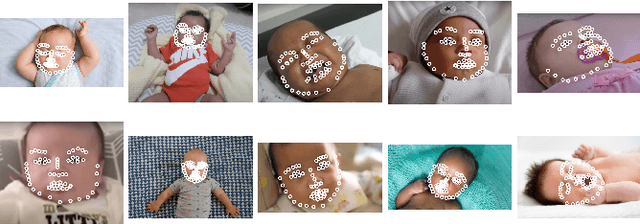
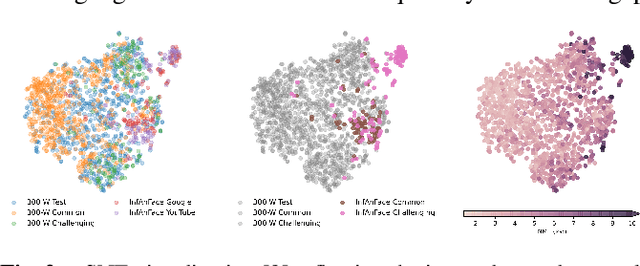
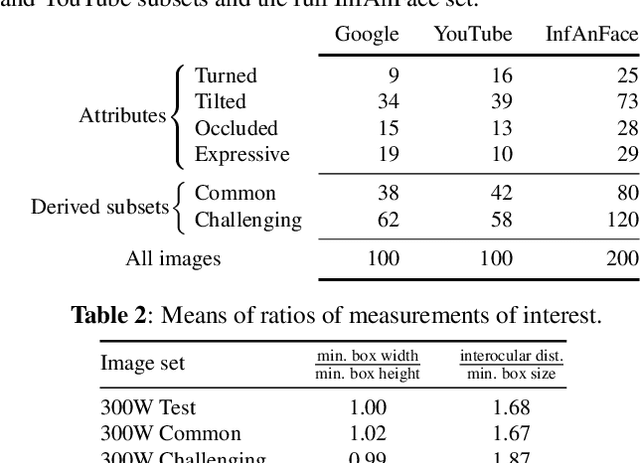
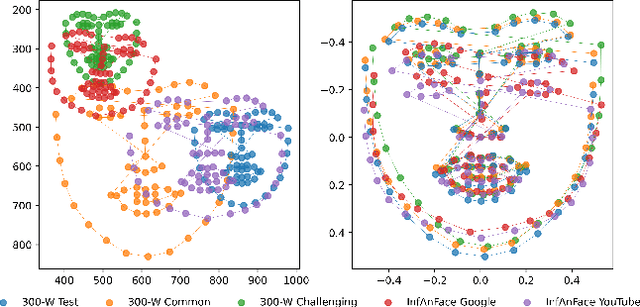
There is promising potential in the application of algorithmic facial landmark estimation to the early prediction, in infants, of pediatric developmental disorders and other conditions. However, the performance of these deep learning algorithms is severely hampered by the scarcity of infant data. To spur the development of facial landmarking systems for infants, we introduce InfAnFace, a diverse, richly-annotated dataset of infant faces. We use InfAnFace to benchmark the performance of existing facial landmark estimation algorithms that are trained on adult faces and demonstrate there is a significant domain gap between the representations learned by these algorithms when applied on infant vs. adult faces. Finally, we put forward the next potential steps to bridge that gap.