 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of test smells for prediction of flaky tests
Aug 26, 2021
Regression testing is an important phase to deliver software with quality. However, flaky tests hamper the evaluation of test results and can increase costs. This is because a flaky test may pass or fail non-deterministically and to identify properly the flakiness of a test requires rerunning the test suite multiple times. To cope with this challenge, approaches have been proposed based on prediction models and machine learning. Existing approaches based on the use of the test case vocabulary may be context-sensitive and prone to overfitting, presenting low performance when executed in a cross-project scenario. To overcome these limitations, we investigate the use of test smells as predictors of flaky tests. We conducted an empirical study to understand if test smells have good performance as a classifier to predict the flakiness in the cross-project context, and analyzed the information gain of each test smell. We also compared the test smell-based approach with the vocabulary-based one. As a result, we obtained a classifier that had a reasonable performance (Random Forest, 0.83%) to predict the flakiness in the testing phase. This classifier presented better performance than vocabulary-based model for cross-project prediction. The Assertion Roulette and Sleepy Test test smell types are the ones associated with the best information gain values.
What is the Vocabulary of Flaky Tests? An Extended Replication
Mar 23, 2021
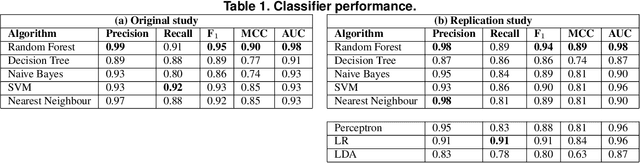

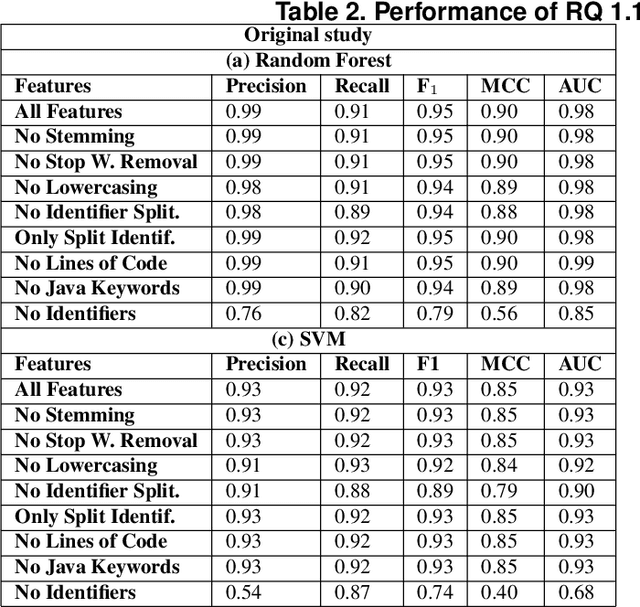
Software systems have been continuously evolved and delivered with high quality due to the widespread adoption of automated tests. A recurring issue hurting this scenario is the presence of flaky tests, a test case that may pass or fail non-deterministically. A promising, but yet lacking more empirical evidence, approach is to collect static data of automated tests and use them to predict their flakiness. In this paper, we conducted an empirical study to assess the use of code identifiers to predict test flakiness. To do so, we first replicate most parts of the previous study of Pinto~et~al.~(MSR~2020). This replication was extended by using a different ML Python platform (Scikit-learn) and adding different learning algorithms in the analyses. Then, we validated the performance of trained models using datasets with other flaky tests and from different projects. We successfully replicated the results of Pinto~et~al.~(2020), with minor differences using Scikit-learn; different algorithms had performance similar to the ones used previously. Concerning the validation, we noticed that the recall of the trained models was smaller, and classifiers presented a varying range of decreases. This was observed in both intra-project and inter-projects test flakiness prediction.