 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Projected Upper Bound for Mining High Utility Patterns from Interval-Based Event Sequences
Dec 21, 2022High utility pattern mining is an interesting yet challenging problem. The intrinsic computational cost of the problem will impose further challenges if efficiency in addition to the efficacy of a solution is sought. Recently, this problem was studied on interval-based event sequences with a constraint on the length and size of the patterns. However, the proposed solution lacks adequate efficiency. To address this issue, we propose a projected upper bound on the utility of the patterns discovered from sequences of interval-based events. To show its effectiveness, the upper bound is utilized by a pruning strategy employed by the HUIPMiner algorithm. Experimental results show that the new upper bound improves HUIPMiner performance in terms of both execution time and memory usage.
High Utility Interval-Based Sequences
Dec 24, 2019

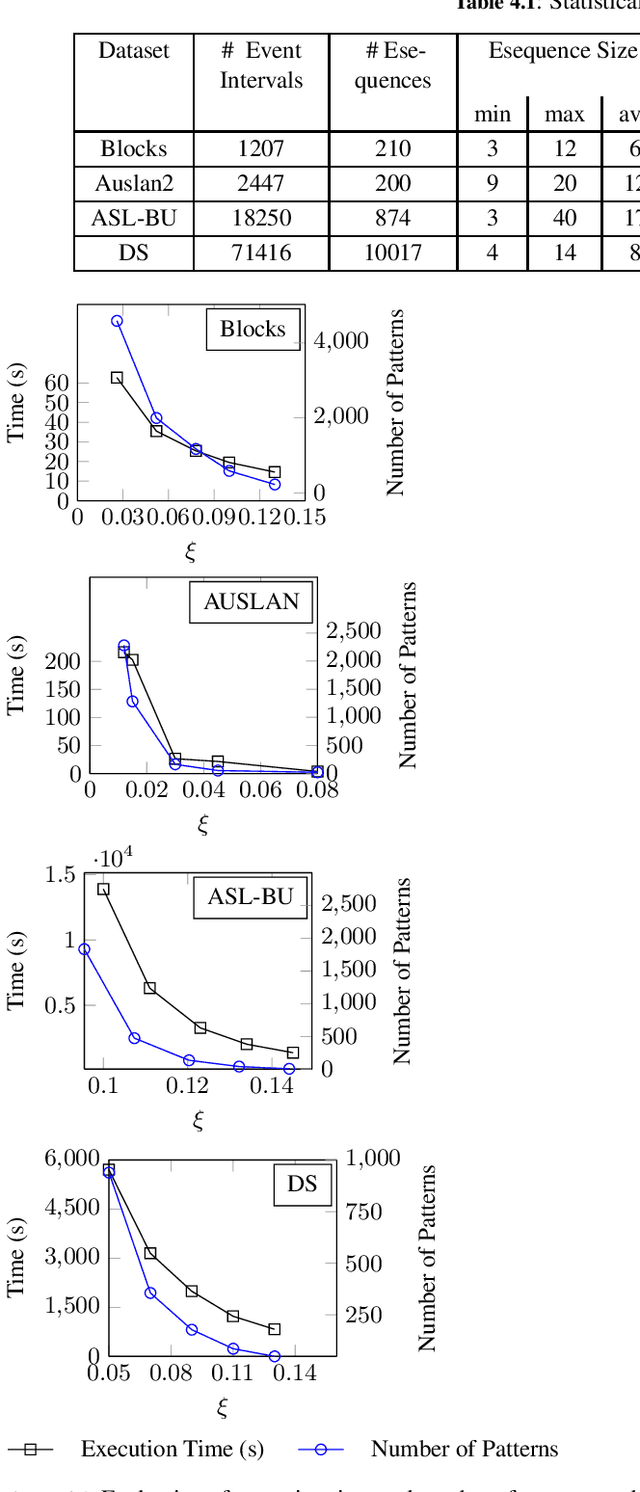
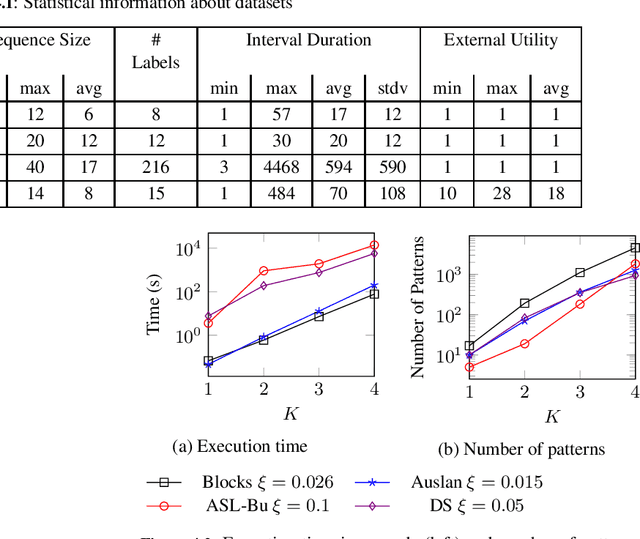
Sequential pattern mining is an interesting research area with broad range of applications. Most prior research on sequential pattern mining has considered point-based data where events occur instantaneously. However, in many application domains, events persist over intervals of time of varying lengths. Furthermore, traditional frameworks of sequential pattern mining assume all events to have the same weight or utility. This simplifying assumption neglects the opportunity to find informative patterns in terms of utilities such as costs. To address these issues, we incorporate the concept of utility into interval-based sequences and define a framework to mine high utility patterns in interval-based sequences i.e., patterns whose utility meets or exceeds a minimum threshold. In the proposed framework, the utility of events is considered while assuming multiple events can occur coincidentally and persist over varying periods of time. An Apriori-based algorithm name High Utility Interval-based Pattern Miner (HUIPMiner) is proposed and applied to real datasets. To achieve an efficient solution, HUIPMiner is augmented with a pruning strategy. Experimental results show that HUIPMiner is an effective solution to the problem of mining high utility interval-based sequences.
FIBS: A Generic Framework for Classifying Interval-based Temporal Sequences
Dec 19, 2019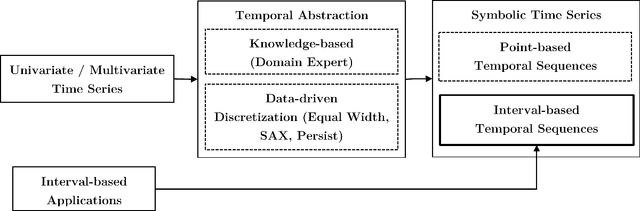
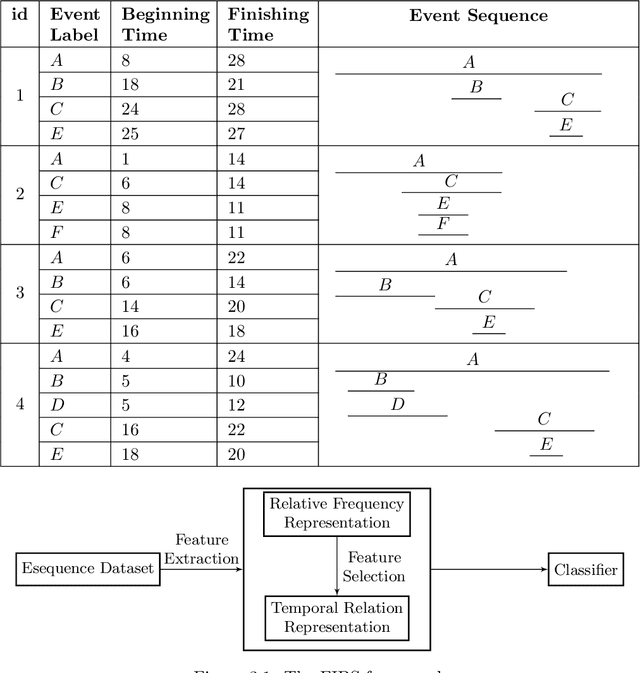
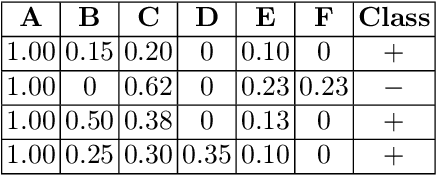

We study the problem of classification of interval-based temporal sequences (IBTSs). Since common classification algorithms cannot be directly applied to IBTSs, the main challenge is to define a set of features that effectively represents the data such that learning classifiers are able to perform. Most prior work utilizes frequent pattern mining to define a feature set based on discovered patterns. However, frequent pattern mining is computationally expensive and often discovers many irrelevant patterns. To address this shortcoming, we propose the FIBS framework for classifying IBTSs. FIBS extracts features relevant to classification from IBTSs based on relative frequency and temporal relations. To avoid selecting irrelevant features, a filter-based selection strategy is incorporated into FIBS. Our empirical evaluation on five real-world datasets demonstrate the effectiveness of our methods in practice. The results provide evidence that FIBS framework effectively represents IBTSs for classification algorithms and it can even achieve better performance when the selection strategy is applied.