 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Compressed Tokenizer Can Generate Without Training
Jun 09, 2025Commonly used image tokenizers produce a 2D grid of spatially arranged tokens. In contrast, so-called 1D image tokenizers represent images as highly compressed one-dimensional sequences of as few as 32 discrete tokens. We find that the high degree of compression achieved by a 1D tokenizer with vector quantization enables image editing and generative capabilities through heuristic manipulation of tokens, demonstrating that even very crude manipulations -- such as copying and replacing tokens between latent representations of images -- enable fine-grained image editing by transferring appearance and semantic attributes. Motivated by the expressivity of the 1D tokenizer's latent space, we construct an image generation pipeline leveraging gradient-based test-time optimization of tokens with plug-and-play loss functions such as reconstruction or CLIP similarity. Our approach is demonstrated for inpainting and text-guided image editing use cases, and can generate diverse and realistic samples without requiring training of any generative model.
Joint Localization and Planning using Diffusion
Sep 26, 2024



Diffusion models have been successfully applied to robotics problems such as manipulation and vehicle path planning. In this work, we explore their application to end-to-end navigation -- including both perception and planning -- by considering the problem of jointly performing global localization and path planning in known but arbitrary 2D environments. In particular, we introduce a diffusion model which produces collision-free paths in a global reference frame given an egocentric LIDAR scan, an arbitrary map, and a desired goal position. To this end, we implement diffusion in the space of paths in SE(2), and describe how to condition the denoising process on both obstacles and sensor observations. In our evaluation, we show that the proposed conditioning techniques enable generalization to realistic maps of considerably different appearance than the training environment, demonstrate our model's ability to accurately describe ambiguous solutions, and run extensive simulation experiments showcasing our model's use as a real-time, end-to-end localization and planning stack.
Multi-Modal Motion Planning Using Composite Pose Graph Optimization
Jul 06, 2021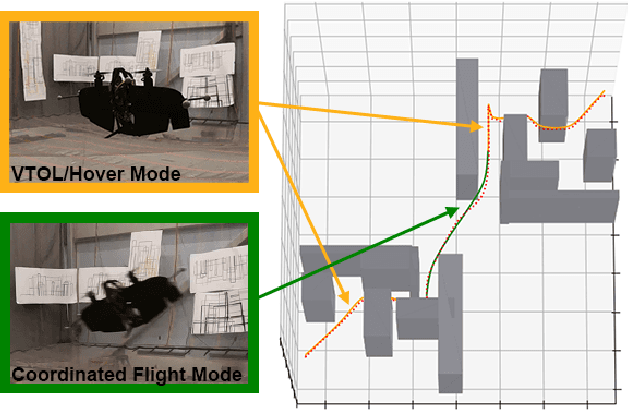
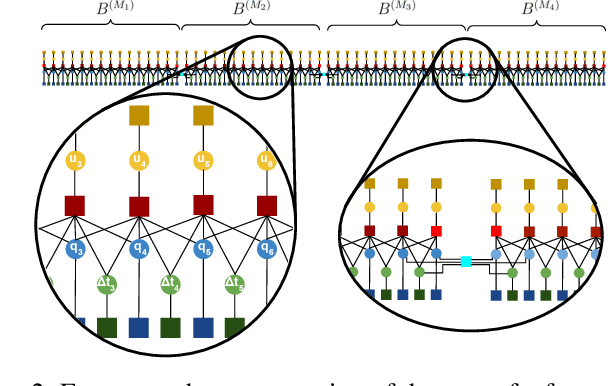
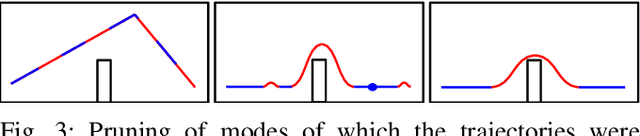
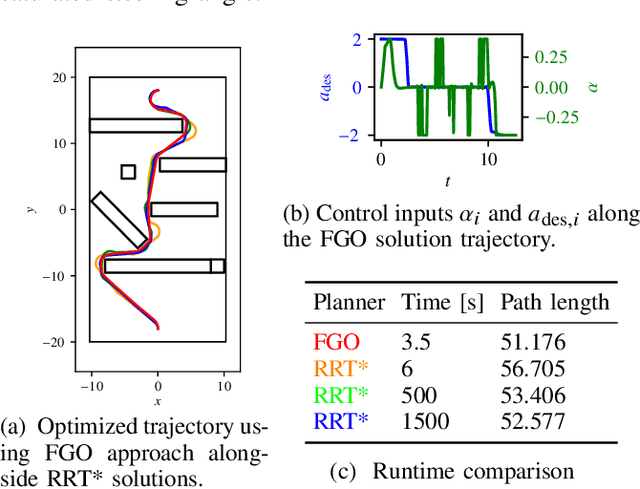
In this paper, we present a motion planning framework for multi-modal vehicle dynamics. Our proposed algorithm employs transcription of the optimization objective function, vehicle dynamics, and state and control constraints into sparse factor graphs, which -- combined with mode transition constraints -- constitute a composite pose graph. By formulating the multi-modal motion planning problem in composite pose graph form, we enable utilization of efficient techniques for optimization on sparse graphs, such as those widely applied in dual estimation problems, e.g., simultaneous localization and mapping (SLAM). The resulting motion planning algorithm optimizes the multi-modal trajectory, including the location of mode transitions, and is guided by the pose graph optimization process to eliminate unnecessary transitions, enabling efficient discovery of optimized mode sequences from rough initial guesses. We demonstrate multi-modal trajectory optimization in both simulation and real-world experiments for vehicles with various dynamics models, such as an airplane with taxi and flight modes, and a vertical take-off and landing (VTOL) fixed-wing aircraft that transitions between hover and horizontal flight modes.