 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew logarithmic step size for stochastic gradient descent
Apr 01, 2024In this paper, we propose a novel warm restart technique using a new logarithmic step size for the stochastic gradient descent (SGD) approach. For smooth and non-convex functions, we establish an $O(\frac{1}{\sqrt{T}})$ convergence rate for the SGD. We conduct a comprehensive implementation to demonstrate the efficiency of the newly proposed step size on the ~FashionMinst,~ CIFAR10, and CIFAR100 datasets. Moreover, we compare our results with nine other existing approaches and demonstrate that the new logarithmic step size improves test accuracy by $0.9\%$ for the CIFAR100 dataset when we utilize a convolutional neural network (CNN) model.
Modified Step Size for Enhanced Stochastic Gradient Descent: Convergence and Experiments
Sep 03, 2023This paper introduces a novel approach to enhance the performance of the stochastic gradient descent (SGD) algorithm by incorporating a modified decay step size based on $\frac{1}{\sqrt{t}}$. The proposed step size integrates a logarithmic term, leading to the selection of smaller values in the final iterations. Our analysis establishes a convergence rate of $O(\frac{\ln T}{\sqrt{T}})$ for smooth non-convex functions without the Polyak-{\L}ojasiewicz condition. To evaluate the effectiveness of our approach, we conducted numerical experiments on image classification tasks using the FashionMNIST, and CIFAR10 datasets, and the results demonstrate significant improvements in accuracy, with enhancements of $0.5\%$ and $1.4\%$ observed, respectively, compared to the traditional $\frac{1}{\sqrt{t}}$ step size. The source code can be found at \\\url{https://github.com/Shamaeem/LNSQRTStepSize}.
Binary Orthogonal Non-negative Matrix Factorization
Oct 19, 2022
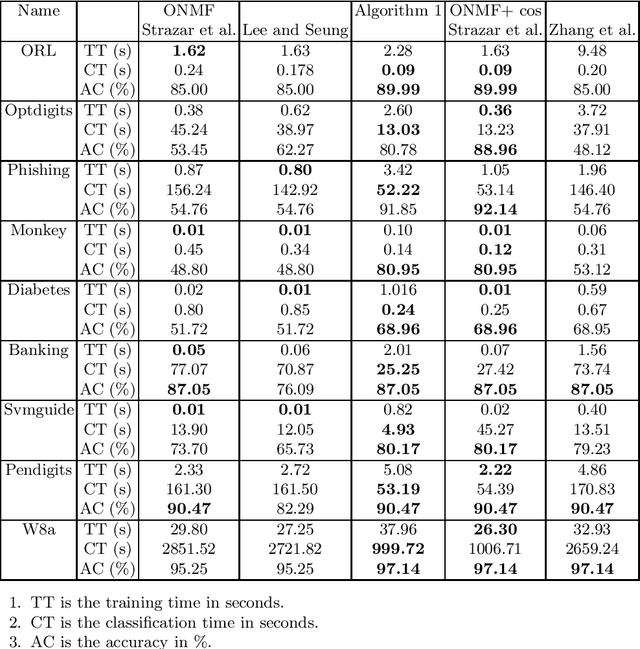
We propose a method for computing binary orthogonal non-negative matrix factorization (BONMF) for clustering and classification. The method is tested on several representative real-world data sets. The numerical results confirm that the method has improved accuracy compared to the related techniques. The proposed method is fast for training and classification and space efficient.