 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural posterior estimation of the neutrino direction in IceCube using transformer-encoded normalizing flows on the sphere
Apr 21, 2026IceCube is a cubic-kilometer-scale neutrino detector located at the geographic South Pole. A precise directional reconstruction of IceCube neutrinos is vital for associations with astronomical objects. In this context, we discuss neural posterior estimation of the neutrino direction via a transformer encoder that maps to a normalizing flow on the 2-sphere. It achieves a new state-of-the-art angular resolution for the two main event morphologies in IceCube - tracks and showers - while being significantly faster than traditional B-spline-based likelihood reconstructions. All-sky scans can be performed within seconds rather than hours, and take constant computation time, regardless of whether the posterior extent is arc-minutes or spans the whole sky. We utilize a combination of $C^2$-smooth rational-quadratic splines, scale transformations and rotations to define a novel spherical normalizing-flow distribution whose parameters are predicted as a whole as the output of the transformer encoder. We test several structural choices diverting from the vanilla transformer architecture. In particular, we find dual residual streams, nonlinear QKV projection and a separate class token with its own cross-attention processing to boost test-time performance. The angular resolution for both showers and tracks improves substantially over the whole trained energy range from 100 GeV to 100 PeV. At 100 TeV deposited energy, for example, the median angular resolution improves by a factor of $1.3$ for throughgoing tracks, by a factor of $1.7$ for showers and by a factor of $2.5$ for starting tracks compared to state-of-the art likelihood reconstructions based on B-splines. While previous machine-learning (ML) efforts have managed to obtain competitive shower resolutions, this is the first time an ML-based method outperforms likelihood-based muon reconstructions above 100 GeV.
Two halves of a meaningful text are statistically different
Apr 09, 2020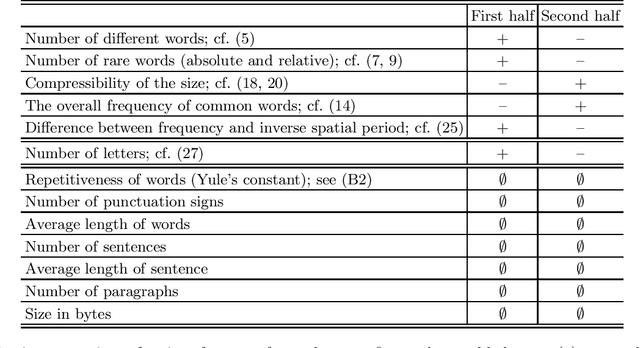
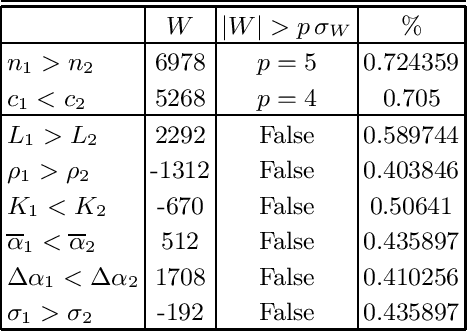
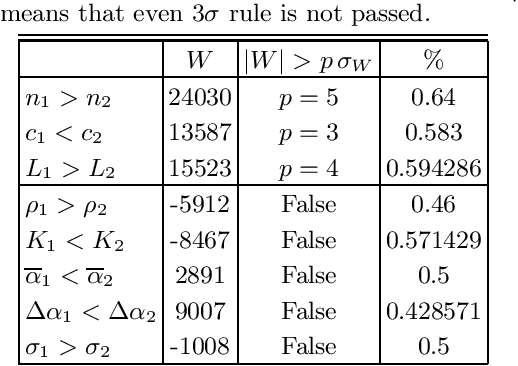
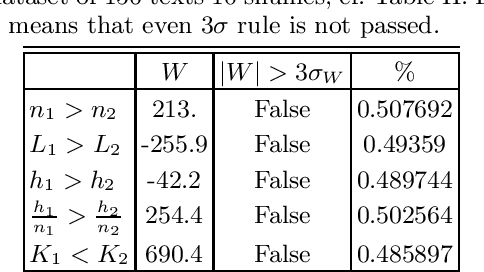
Which statistical features distinguish a meaningful text (possibly written in an unknown system) from a meaningless set of symbols? Here we answer this question by comparing features of the first half of a text to its second half. This comparison can uncover hidden effects, because the halves have the same values of many parameters (style, genre {\it etc}). We found that the first half has more different words and more rare words than the second half. Also, words in the first half are distributed less homogeneously over the text in the sense of of the difference between the frequency and the inverse spatial period. These differences hold for the significant majority of several hundred relatively short texts we studied. The statistical significance is confirmed via the Wilcoxon test. Differences disappear after random permutation of words that destroys the linear structure of the text. The differences reveal a temporal asymmetry in meaningful texts, which is confirmed by showing that texts are much better compressible in their natural way (i.e. along the narrative) than in the word-inverted form. We conjecture that these results connect the semantic organization of a text (defined by the flow of its narrative) to its statistical features.