 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel approach to measuring patent claim scope based on probabilities obtained from language models
Sep 28, 2023This work proposes to measure the scope of a patent claim as the reciprocal of the self-information contained in this claim. A probability of occurrence of the claim is obtained from a language model and this probability is used to compute the self-information. Grounded in information theory, this approach is based on the assumption that an unlikely concept is more informative than a usual concept, insofar as it is more surprising. In turn, the more surprising the information required to defined the claim, the narrower its scope. Five language models are considered, ranging from simplest models (each word or character is assigned an identical probability) to intermediate models (using average word or character frequencies), to a large language model (GPT2). Interestingly, the scope resulting from the simplest language models is proportional to the reciprocal of the number of words or characters involved in the claim, a metric already used in previous works. Application is made to multiple series of patent claims directed to distinct inventions, where each series consists of claims devised to have a gradually decreasing scope. The performance of the language models is assessed with respect to several ad hoc tests. The more sophisticated the model, the better the results. I.e., the GPT2 probability model outperforms models based on word and character frequencies, which themselves outdo the simplest models based on word or character counts. Still, the character count appears to be a more reliable indicator than the word count.
Measuring the originality of intellectual property assets based on machine learning outputs
Oct 14, 2020
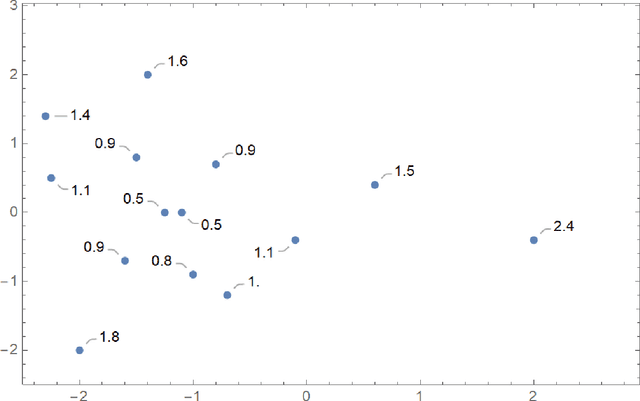
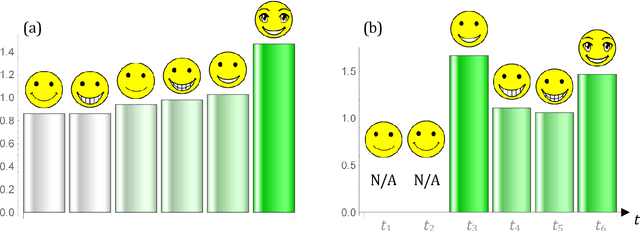

Originality criteria are frequently used to assess the validity of intellectual property (IP) rights, such as copyright and design rights. In this work, the originality of an asset is formulated as a function of the distances between this asset and its comparands, using concepts of maximum entropy and surprisal analysis. Namely, this function is defined as the reciprocal of the surprisal associated with a given asset. Creative assets can justifiably be compared to particles that repel each other. This allows a very simple formula to be obtained, in which the originality of a given asset writes as the ratio of a reference energy to an interaction energy imparted to that asset. In particular, using an electrostatic-like pair potential makes it possible to rewrite the originality function as the ratio of two average distances, i.e., as the harmonic mean of the distances from the given asset to its comparands divided by the harmonic mean of the distances between the sole comparands. Thus, the originality of objects such as IP assets can be simply estimated based on distances computed according to vectors extracted thanks to unsupervised machine learning techniques or other algorithms. Application is made to various types of IP assets, including emojis, typeface designs, paintings, and novel titles.