 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem
May 04, 2022
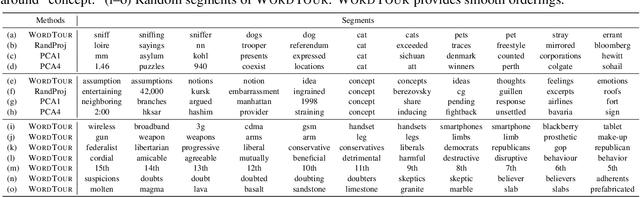
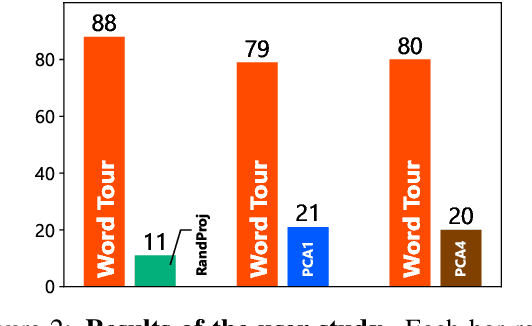
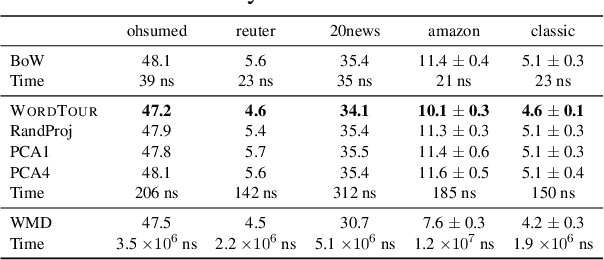
Word embeddings are one of the most fundamental technologies used in natural language processing. Existing word embeddings are high-dimensional and consume considerable computational resources. In this study, we propose WordTour, unsupervised one-dimensional word embeddings. To achieve the challenging goal, we propose a decomposition of the desiderata of word embeddings into two parts, completeness and soundness, and focus on soundness in this paper. Owing to the single dimensionality, WordTour is extremely efficient and provides a minimal means to handle word embeddings. We experimentally confirmed the effectiveness of the proposed method via user study and document classification.
Retrieving Black-box Optimal Images from External Databases
Dec 30, 2021



Suppose we have a black-box function (e.g., deep neural network) that takes an image as input and outputs a value that indicates preference. How can we retrieve optimal images with respect to this function from an external database on the Internet? Standard retrieval problems in the literature (e.g., item recommendations) assume that an algorithm has full access to the set of items. In other words, such algorithms are designed for service providers. In this paper, we consider the retrieval problem under different assumptions. Specifically, we consider how users with limited access to an image database can retrieve images using their own black-box functions. This formulation enables a flexible and finer-grained image search defined by each user. We assume the user can access the database through a search query with tight API limits. Therefore, a user needs to efficiently retrieve optimal images in terms of the number of queries. We propose an efficient retrieval algorithm Tiara for this problem. In the experiments, we confirm that our proposed method performs better than several baselines under various settings.
Fixed Support Tree-Sliced Wasserstein Barycenter
Sep 08, 2021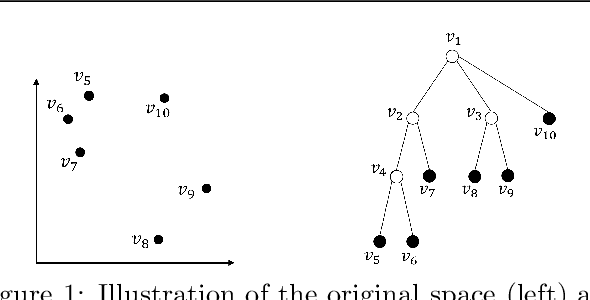
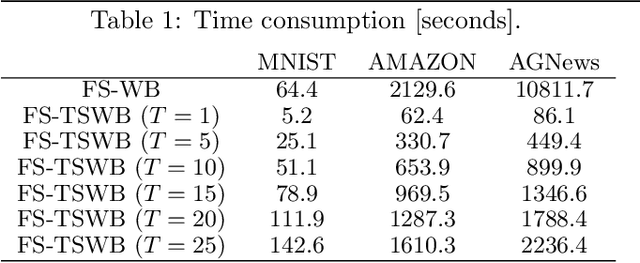
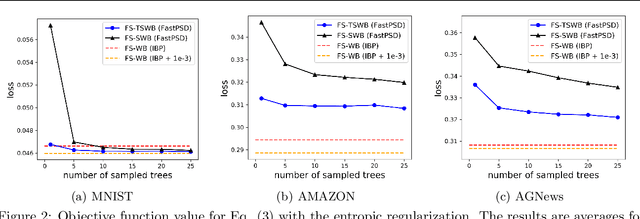
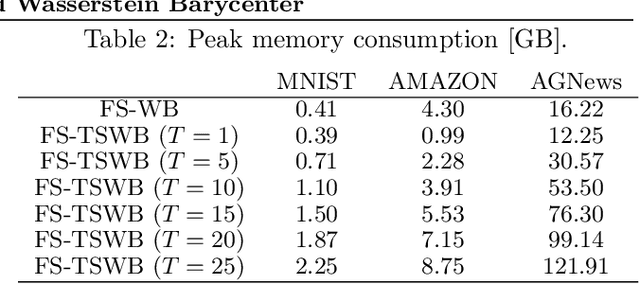
The Wasserstein barycenter has been widely studied in various fields, including natural language processing, and computer vision. However, it requires a high computational cost to solve the Wasserstein barycenter problem because the computation of the Wasserstein distance requires a quadratic time with respect to the number of supports. By contrast, the Wasserstein distance on a tree, called the tree-Wasserstein distance, can be computed in linear time and allows for the fast comparison of a large number of distributions. In this study, we propose a barycenter under the tree-Wasserstein distance, called the fixed support tree-Wasserstein barycenter (FS-TWB) and its extension, called the fixed support tree-sliced Wasserstein barycenter (FS-TSWB). More specifically, we first show that the FS-TWB and FS-TSWB problems are convex optimization problems and can be solved by using the projected subgradient descent. Moreover, we propose a more efficient algorithm to compute the subgradient and objective function value by using the properties of tree-Wasserstein barycenter problems. Through real-world experiments, we show that, by using the proposed algorithm, the FS-TWB and FS-TSWB can be solved two orders of magnitude faster than the original Wasserstein barycenter.
Enumerating Fair Packages for Group Recommendations
May 30, 2021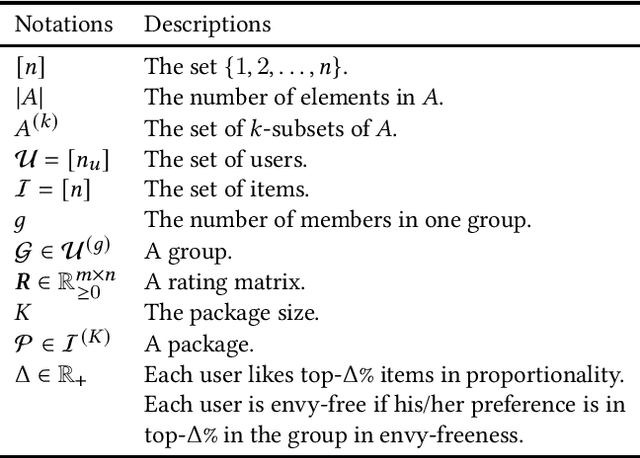
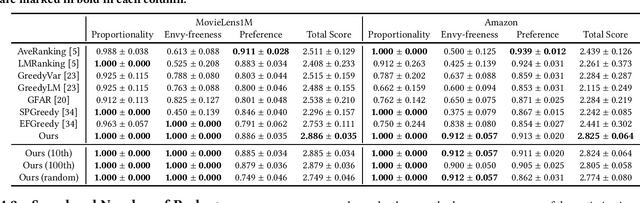
In package recommendations, a set of items is regarded as a unified package towards a single common goal, whereas conventional recommender systems treat items independently. For example, for music playlist recommendations, each package (i.e., playlist) should be consistent with respect to the genres. In group recommendations, items are recommended to a group of users, whereas conventional recommender systems recommend items to an individual user. Different from the conventional settings, it is difficult to measure the utility of group recommendations because it involves more than one user. In particular, fairness is crucial in group recommendations. Even if some members in a group are substantially satisfied with a recommendation, it is undesirable if other members are ignored to increase the total utility. Various methods for evaluating and applying the fairness of group recommendations have been proposed in the literature. However, all these methods maximize the score and output only a single package. This is in contrast to conventional recommender systems, which output several (e.g., top-$K$) candidates. This can be problematic because a group can be dissatisfied with the recommended package owing to some unobserved reasons, even if the score is high. In particular, each fairness measure is not absolute, and users may call for different fairness criteria than the one adopted in the recommender system in operation. To address this issue, we propose a method to enumerate fair packages so that a group can select their favorite packages from the list. Our proposed method can enumerate fair packages efficiently, and users can search their favorite packages by various filtering queries. We confirm that our algorithm scales to large datasets and can balance several aspects of the utility of the packages.
Re-evaluating Word Mover's Distance
May 30, 2021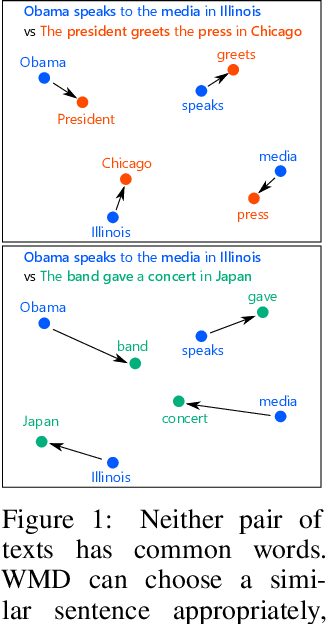
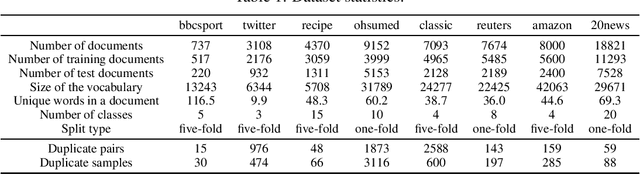
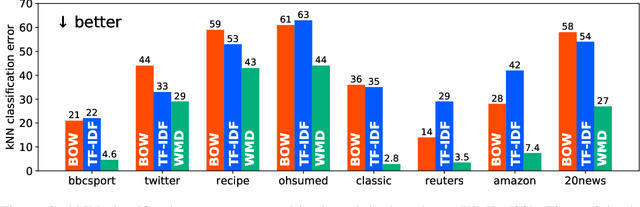
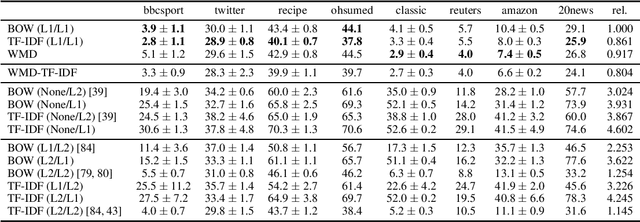
The word mover's distance (WMD) is a fundamental technique for measuring the similarity of two documents. As the crux of WMD, it can take advantage of the underlying geometry of the word space by employing an optimal transport formulation. The original study on WMD reported that WMD outperforms classical baselines such as bag-of-words (BOW) and TF-IDF by significant margins in various datasets. In this paper, we point out that the evaluation in the original study could be misleading. We re-evaluate the performances of WMD and the classical baselines and find that the classical baselines are competitive with WMD if we employ an appropriate preprocessing, i.e., L1 normalization. However, this result is not intuitive. WMD should be superior to BOW because WMD can take the underlying geometry into account, whereas BOW cannot. Our analysis shows that this is due to the high-dimensional nature of the underlying metric. We find that WMD in high-dimensional spaces behaves more similarly to BOW than in low-dimensional spaces due to the curse of dimensionality.
Private Recommender Systems: How Can Users Build Their Own Fair Recommender Systems without Log Data?
May 26, 2021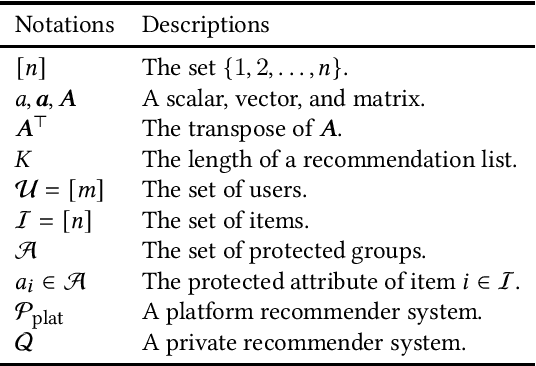

Fairness is an important property in data-mining applications, including recommender systems. In this work, we investigate a case where users of a recommender system need (or want) to be fair to a protected group of items. For example, in a job market, the user is the recruiter, an item is the job seeker, and the protected attribute is gender or race. Even if recruiters want to use a fair talent recommender system, the platform may not provide a fair recommender system, or recruiters may not be able to ascertain whether the recommender system's algorithm is fair. In this case, recruiters cannot utilize the recommender system, or they may become unfair to job seekers. In this work, we propose methods to enable the users to build their own fair recommender systems. Our methods can generate fair recommendations even when the platform does not (or cannot) provide fair recommender systems. The key challenge is that a user does not have access to the log data of other users or the latent representations of items. This restriction prohibits us from adopting existing methods, which are designed for platforms. The main idea is that a user has access to unfair recommendations provided by the platform. Our methods leverage the outputs of an unfair recommender system to construct a new fair recommender system. We empirically validate that our proposed method improves fairness substantially without harming much performance of the original unfair system.
Supervised Tree-Wasserstein Distance
Jan 27, 2021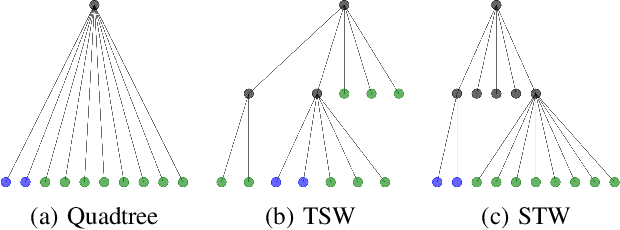

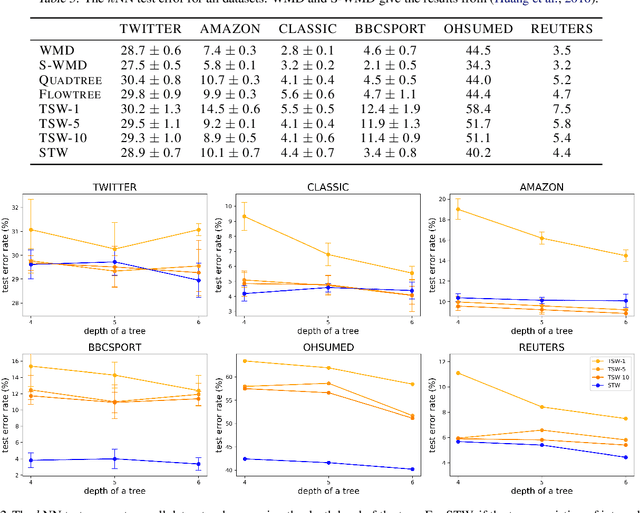
To measure the similarity of documents, the Wasserstein distance is a powerful tool, but it requires a high computational cost. Recently, for fast computation of the Wasserstein distance, methods for approximating the Wasserstein distance using a tree metric have been proposed. These tree-based methods allow fast comparisons of a large number of documents; however, they are unsupervised and do not learn task-specific distances. In this work, we propose the Supervised Tree-Wasserstein (STW) distance, a fast, supervised metric learning method based on the tree metric. Specifically, we rewrite the Wasserstein distance on the tree metric by the parent-child relationships of a tree, and formulate it as a continuous optimization problem using a contrastive loss. Experimentally, we show that the STW distance can be computed fast, and improves the accuracy of document classification tasks. Furthermore, the STW distance is formulated by matrix multiplications, runs on a GPU, and is suitable for batch processing. Therefore, we show that the STW distance is extremely efficient when comparing a large number of documents.
Poincare: Recommending Publication Venues via Treatment Effect Estimation
Oct 19, 2020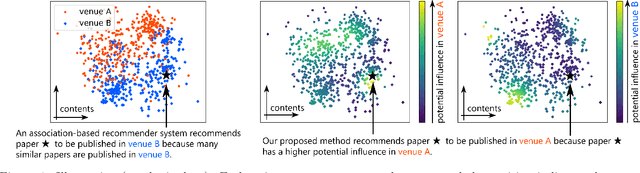


Choosing a publication venue for an academic paper is a crucial step in the research process. However, in many cases, decisions are based on the experience of researchers, which often leads to suboptimal results. Although some existing methods recommend publication venues, they just recommend venues where a paper is likely to be published. In this study, we aim to recommend publication venues from a different perspective. We estimate the number of citations a paper will receive if the paper is published in each venue and recommend the venue where the paper has the most potential impact. However, there are two challenges to this task. First, a paper is published in only one venue, and thus, we cannot observe the number of citations the paper would receive if the paper were published in another venue. Secondly, the contents of a paper and the publication venue are not statistically independent; that is, there exist selection biases in choosing publication venues. In this paper, we propose to use a causal inference method to estimate the treatment effects of choosing a publication venue effectively and to recommend venues based on the potential influence of papers.
Fast Unbalanced Optimal Transport on Tree
Jun 04, 2020

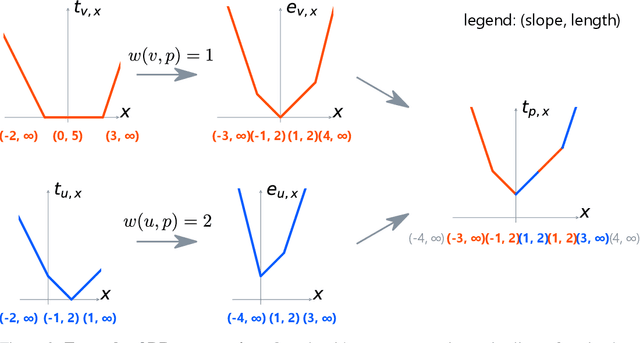

This study examines the time complexities of the unbalanced optimal transport problems from an algorithmic perspective for the first time. We reveal which problems in unbalanced optimal transport can/cannot be solved efficiently. Specifically, we prove that the Kantrovich Rubinstein distance and optimal partial transport in Euclidean metric cannot be computed in strongly subquadratic time under the strong exponential time hypothesis. Then, we propose an algorithm that solves a more general unbalanced optimal transport problem exactly in quasi-linear time on a tree metric. The proposed algorithm processes a tree with one million nodes in less than one second. Our analysis forms a foundation for the theoretical study of unbalanced optimal transport algorithms and opens the door to the applications of unbalanced optimal transport to million-scale datasets.
A Survey on The Expressive Power of Graph Neural Networks
Mar 15, 2020
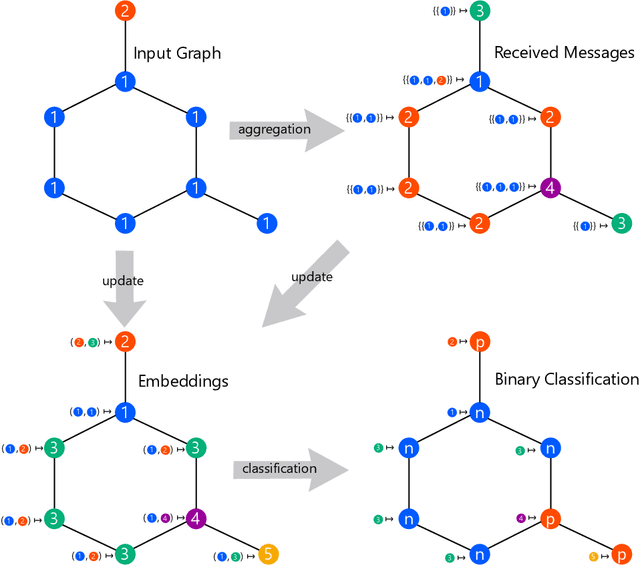
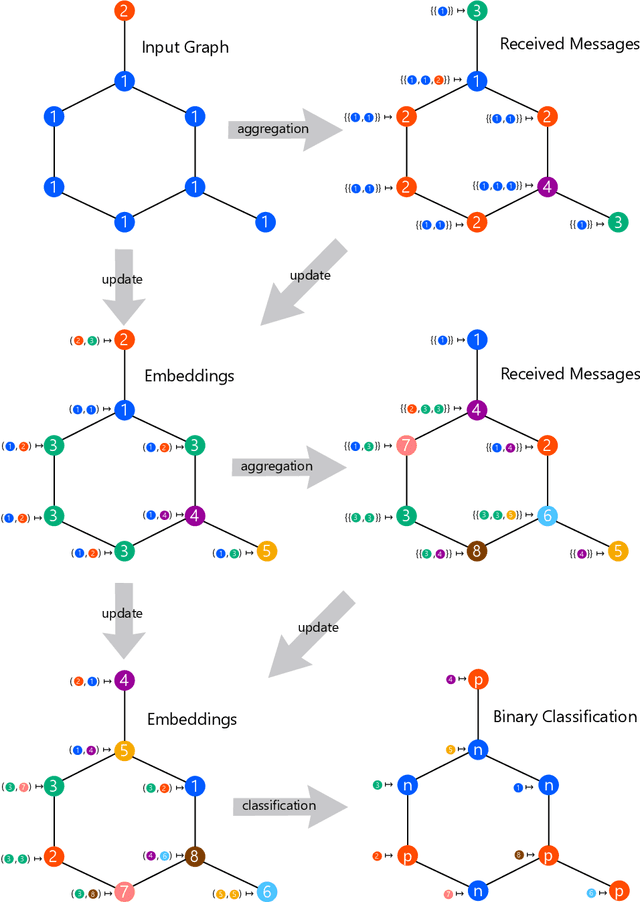

Graph neural networks (GNNs) are effective machine learning models for various graph learning problems. Despite their empirical successes, the theoretical limitations of GNNs have been revealed recently. Consequently, many GNN models have been proposed to overcome these limitations. In this survey, we provide a comprehensive overview of the expressive power of GNNs and provably powerful variants of GNNs.