 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Model Probabilistic Programming
Aug 12, 2022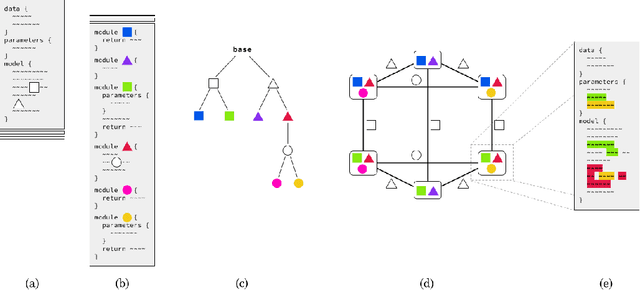
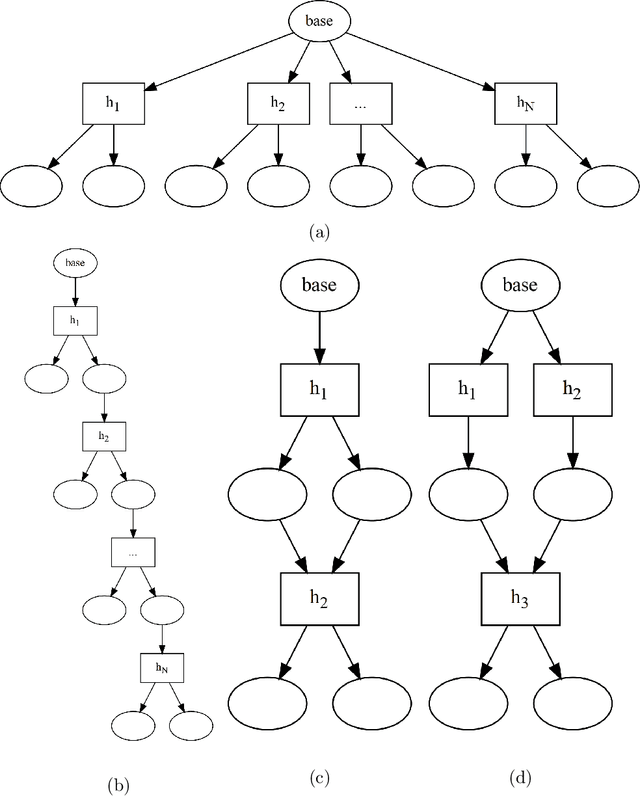
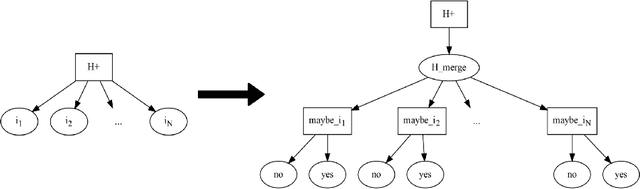
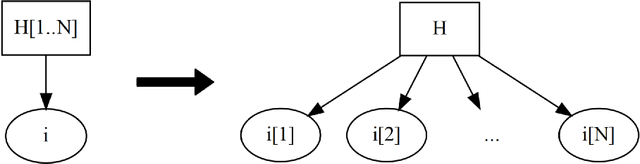
Probabilistic programming makes it easy to represent a probabilistic model as a program. Building an individual model, however, is only one step of probabilistic modeling. The broader challenge of probabilistic modeling is in understanding and navigating spaces of alternative models. There is currently no good way to represent these spaces of alternative models, despite their central role. We present an extension of probabilistic programming that lets each program represent a network of interrelated probabilistic models. We give a formal semantics for these multi-model probabilistic programs, a collection of efficient algorithms for network-of-model operations, and an example implementation built on top of the popular probabilistic programming language Stan. This network-of-models representation opens many doors, including search and automation in model-space, tracking and communication of model development, and explicit modeler degrees of freedom to mitigate issues like p-hacking. We demonstrate automatic model search and model development tracking using our Stan implementation, and we propose many more possible applications.
Transforming Probabilistic Programs for Model Checking
Aug 21, 2020Probabilistic programming is perfectly suited to reliable and transparent data science, as it allows the user to specify their models in a high-level language without worrying about the complexities of how to fit the models. Static analysis of probabilistic programs presents even further opportunities for enabling a high-level style of programming, by automating time-consuming and error-prone tasks. We apply static analysis to probabilistic programs to automate large parts of two crucial model checking methods: Prior Predictive Checks and Simulation-Based Calibration. Our method transforms a probabilistic program specifying a density function into an efficient forward-sampling form. To achieve this transformation, we extract a factor graph from a probabilistic program using static analysis, generate a set of proposal directed acyclic graphs using a SAT solver, select a graph which will produce provably correct sampling code, then generate one or more sampling programs. We allow minimal user interaction to broaden the scope of application beyond what is possible with static analysis alone. We present an implementation targeting the popular Stan probabilistic programming language, automating large parts of a robust Bayesian workflow for a wide community of probabilistic programming users.
Static Analysis for Probabilistic Programs
Sep 10, 2019



Probabilistic programming is a powerful abstraction for statistical machine learning. Applying static analysis methods to probabilistic programs could serve to optimize the learning process, automatically verify properties of models, and improve the programming interface for users. This field of static analysis for probabilistic programming (SAPP) is young and unorganized, consisting of a constellation of techniques with various goals and limitations. The primary aim of this work is to synthesize the major contributions of the SAPP field within an organizing structure and context. We provide technical background for static analysis and probabilistic programming, suggest a functional taxonomy for probabilistic programming languages, and analyze the applicability of major ideas in the SAPP field. We conclude that, while current static analysis techniques for probabilistic programs have practical limitations, there are a number of future directions with high potential to improve the state of statistical machine learning.