 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombinatorial and computational investigations of Neighbor-Joining bias
Jul 18, 2020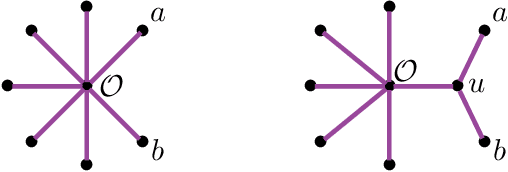

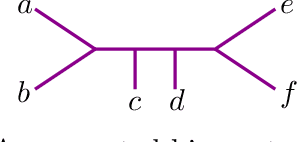

The Neighbor-Joining algorithm is a popular distance-based phylogenetic method that computes a tree metric from a dissimilarity map arising from biological data. Realizing dissimilarity maps as points in Euclidean space, the algorithm partitions the input space into polyhedral regions indexed by the combinatorial type of the trees returned. A full combinatorial description of these regions has not been found yet; different sequences of Neighbor-Joining agglomeration events can produce the same combinatorial tree, therefore associating multiple geometric regions to the same algorithmic output. We resolve this confusion by defining agglomeration orders on trees, leading to a bijection between distinct regions of the output space and weighted Motzkin paths. As a result, we give a formula for the number of polyhedral regions depending only on the number of taxa. We conclude with a computational comparison between these polyhedral regions, to unveil biases introduced in any implementation of the algorithm.
RGB image-based data analysis via discrete Morse theory and persistent homology
Jan 09, 2018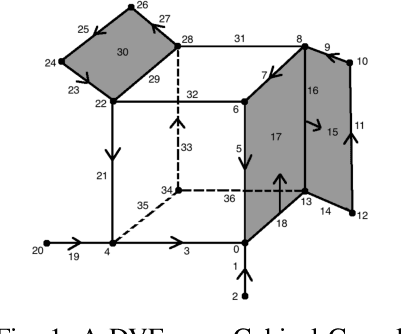
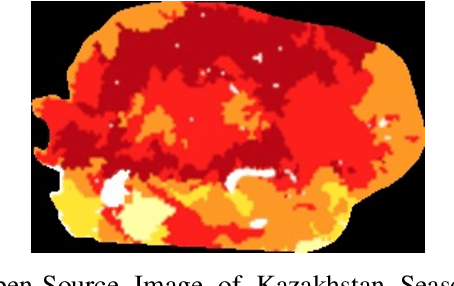

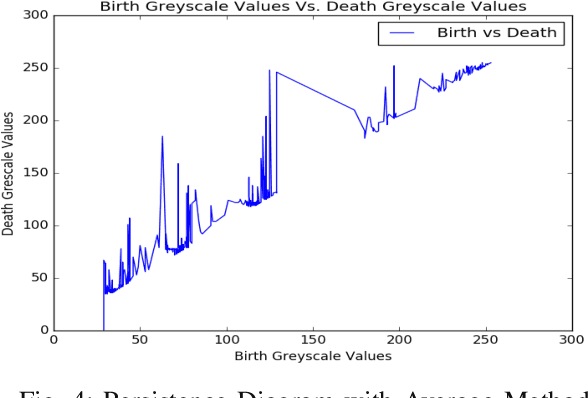
Understanding and comparing images for the purposes of data analysis is currently a very computationally demanding task. A group at Australian National University (ANU) recently developed open-source code that can detect fundamental topological features of a grayscale image in a computationally feasible manner. This is made possible by the fact that computers store grayscale images as cubical cellular complexes. These complexes can be studied using the techniques of discrete Morse theory. We expand the functionality of the ANU code by introducing methods and software for analyzing images encoded in red, green, and blue (RGB), because this image encoding is very popular for publicly available data. Our methods allow the extraction of key topological information from RGB images via informative persistence diagrams by introducing novel methods for transforming RGB-to-grayscale. This paradigm allows us to perform data analysis directly on RGB images representing water scarcity variability as well as crime variability. We introduce software enabling a a user to predict future image properties, towards the eventual aim of more rapid image-based data behavior prediction.