 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Nonsmooth Regularized Risk Minimization with Continuation
Feb 25, 2016
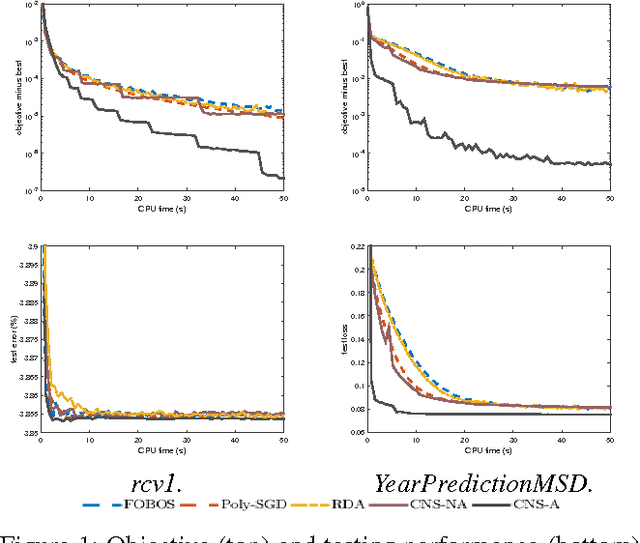
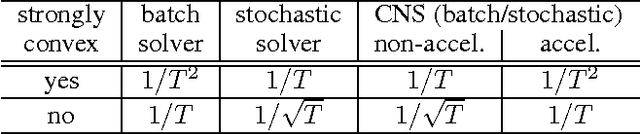
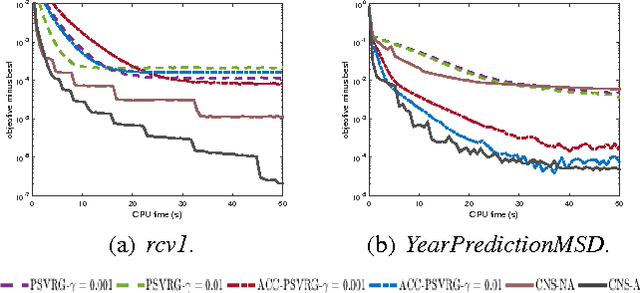
In regularized risk minimization, the associated optimization problem becomes particularly difficult when both the loss and regularizer are nonsmooth. Existing approaches either have slow or unclear convergence properties, are restricted to limited problem subclasses, or require careful setting of a smoothing parameter. In this paper, we propose a continuation algorithm that is applicable to a large class of nonsmooth regularized risk minimization problems, can be flexibly used with a number of existing solvers for the underlying smoothed subproblem, and with convergence results on the whole algorithm rather than just one of its subproblems. In particular, when accelerated solvers are used, the proposed algorithm achieves the fastest known rates of $O(1/T^2)$ on strongly convex problems, and $O(1/T)$ on general convex problems. Experiments on nonsmooth classification and regression tasks demonstrate that the proposed algorithm outperforms the state-of-the-art.
Asynchronous Distributed Semi-Stochastic Gradient Optimization
Dec 04, 2015
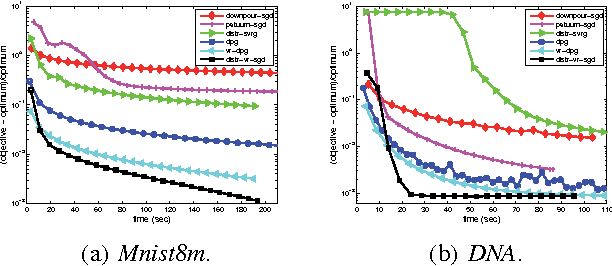
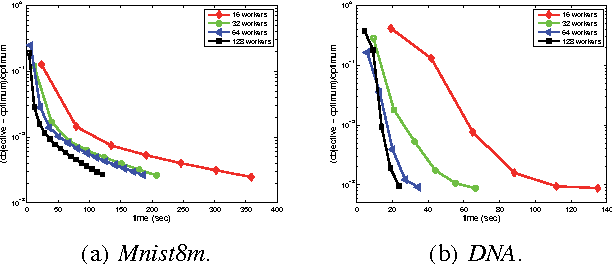
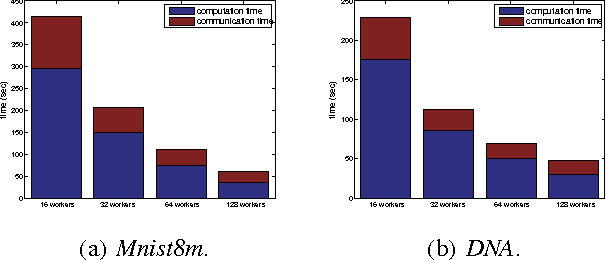
With the recent proliferation of large-scale learning problems,there have been a lot of interest on distributed machine learning algorithms, particularly those that are based on stochastic gradient descent (SGD) and its variants. However, existing algorithms either suffer from slow convergence due to the inherent variance of stochastic gradients, or have a fast linear convergence rate but at the expense of poorer solution quality. In this paper, we combine their merits by proposing a fast distributed asynchronous SGD-based algorithm with variance reduction. A constant learning rate can be used, and it is also guaranteed to converge linearly to the optimal solution. Experiments on the Google Cloud Computing Platform demonstrate that the proposed algorithm outperforms state-of-the-art distributed asynchronous algorithms in terms of both wall clock time and solution quality.
TV-SVM: Total Variation Support Vector Machine for Semi-Supervised Data Classification
Oct 02, 2012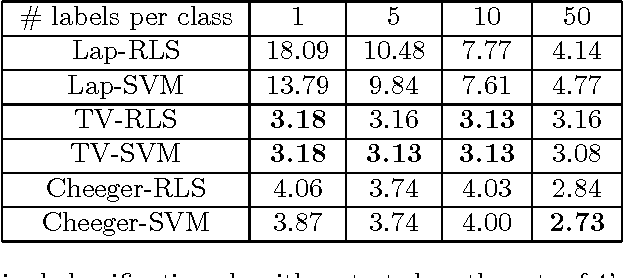
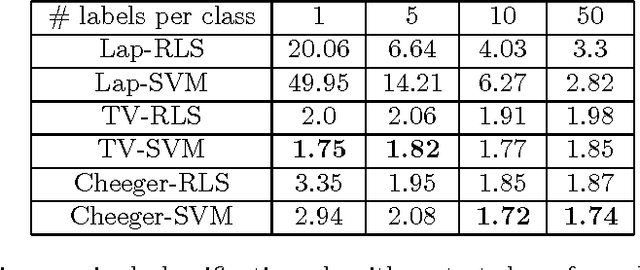
We introduce semi-supervised data classification algorithms based on total variation (TV), Reproducing Kernel Hilbert Space (RKHS), support vector machine (SVM), Cheeger cut, labeled and unlabeled data points. We design binary and multi-class semi-supervised classification algorithms. We compare the TV-based classification algorithms with the related Laplacian-based algorithms, and show that TV classification perform significantly better when the number of labeled data is small.