 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Foundations of Forward Feature Selection Methods based on Mutual Information
Feb 14, 2018
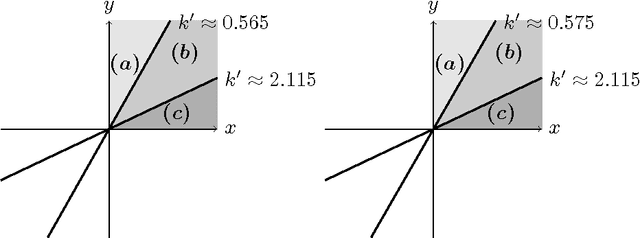
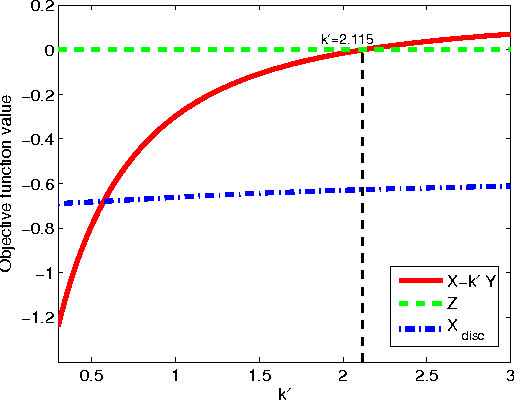
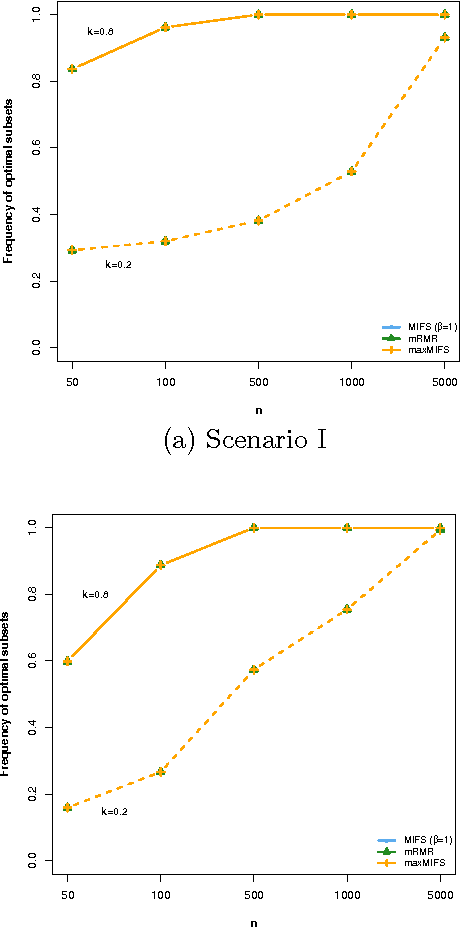
Feature selection problems arise in a variety of applications, such as microarray analysis, clinical prediction, text categorization, image classification and face recognition, multi-label learning, and classification of internet traffic. Among the various classes of methods, forward feature selection methods based on mutual information have become very popular and are widely used in practice. However, comparative evaluations of these methods have been limited by being based on specific datasets and classifiers. In this paper, we develop a theoretical framework that allows evaluating the methods based on their theoretical properties. Our framework is grounded on the properties of the target objective function that the methods try to approximate, and on a novel categorization of features, according to their contribution to the explanation of the class; we derive upper and lower bounds for the target objective function and relate these bounds with the feature types. Then, we characterize the types of approximations taken by the methods, and analyze how these approximations cope with the good properties of the target objective function. Additionally, we develop a distributional setting designed to illustrate the various deficiencies of the methods, and provide several examples of wrong feature selections. Based on our work, we identify clearly the methods that should be avoided, and the methods that currently have the best performance.
Theoretical Evaluation of Feature Selection Methods based on Mutual Information
Oct 07, 2016


Feature selection methods are usually evaluated by wrapping specific classifiers and datasets in the evaluation process, resulting very often in unfair comparisons between methods. In this work, we develop a theoretical framework that allows obtaining the true feature ordering of two-dimensional sequential forward feature selection methods based on mutual information, which is independent of entropy or mutual information estimation methods, classifiers, or datasets, and leads to an undoubtful comparison of the methods. Moreover, the theoretical framework unveils problems intrinsic to some methods that are otherwise difficult to detect, namely inconsistencies in the construction of the objective function used to select the candidate features, due to various types of indeterminations and to the possibility of the entropy of continuous random variables taking null and negative values.