 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Hear Your True Colors: Image Guided Audio Generation
Nov 06, 2022We propose Im2Wav, an image guided open-domain audio generation system. Given an input image or a sequence of images, Im2Wav generates a semantically relevant sound. Im2Wav is based on two Transformer language models, that operate over a hierarchical discrete audio representation obtained from a VQ-VAE based model. We first produce a low-level audio representation using a language model. Then, we upsample the audio tokens using an additional language model to generate a high-fidelity audio sample. We use the rich semantics of a pre-trained CLIP embedding as a visual representation to condition the language model. In addition, to steer the generation process towards the conditioning image, we apply the classifier-free guidance method. Results suggest that Im2Wav significantly outperforms the evaluated baselines in both fidelity and relevance evaluation metrics. Additionally, we provide an ablation study to better assess the impact of each of the method components on overall performance. Lastly, to better evaluate image-to-audio models, we propose an out-of-domain image dataset, denoted as ImageHear. ImageHear can be used as a benchmark for evaluating future image-to-audio models. Samples and code can be found inside the manuscript.
PnP-Net: A hybrid Perspective-n-Point Network
Mar 10, 2020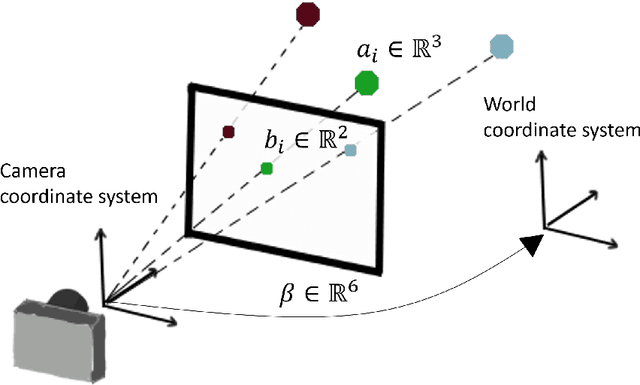
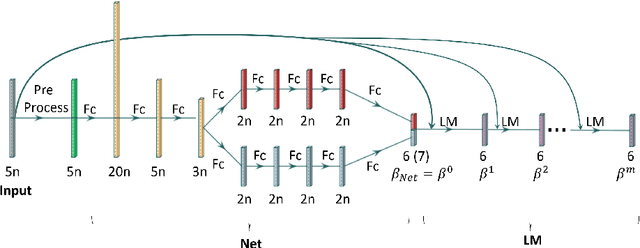
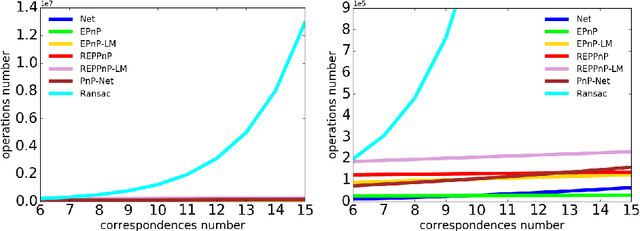
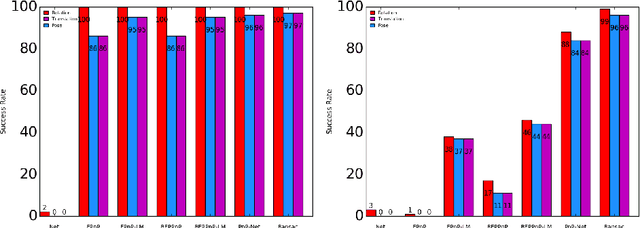
We consider the robust Perspective-n-Point (PnP) problem using a hybrid approach that combines deep learning with model based algorithms. PnP is the problem of estimating the pose of a calibrated camera given a set of 3D points in the world and their corresponding 2D projections in the image. In its more challenging robust version, some of the correspondences may be mismatched and must be efficiently discarded. Classical solutions address PnP via iterative robust non-linear least squares method that exploit the problem's geometry but are either inaccurate or computationally intensive. In contrast, we propose to combine a deep learning initial phase followed by a model-based fine tuning phase. This hybrid approach, denoted by PnP-Net, succeeds in estimating the unknown pose parameters under correspondence errors and noise, with low and fixed computational complexity requirements. We demonstrate its advantages on both synthetic data and real world data.