 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLVAR: Fast covariance-based heterogeneity analysis with pose refinement for cryo-EM
Feb 19, 2026Cryo-electron microscopy (cryo-EM) has emerged as a powerful technique for resolving the three-dimensional structures of macromolecules. A key challenge in cryo-EM is characterizing continuous heterogeneity, where molecules adopt a continuum of conformational states. Covariance-based methods offer a principled approach to modeling structural variability. However, estimating the covariance matrix efficiently remains a challenging computational task. In this paper, we present SOLVAR (Stochastic Optimization for Low-rank Variability Analysis), which leverages a low-rank assumption on the covariance matrix to provide a tractable estimator for its principal components, despite the apparently prohibitive large size of the covariance matrix. Under this low-rank assumption, our estimator can be formulated as an optimization problem that can be solved quickly and accurately. Moreover, our framework enables refinement of the poses of the input particle images, a capability absent from most heterogeneity-analysis methods, and all covariance-based methods. Numerical experiments on both synthetic and experimental datasets demonstrate that the algorithm accurately captures dominant components of variability while maintaining computational efficiency. SOLVAR achieves state-of-the-art performance across multiple datasets in a recent heterogeneity benchmark. The code of the algorithm is freely available at https://github.com/RoeyYadgar/SOLVAR.
The Catastrophic Failure of The k-Means Algorithm in High Dimensions, and How Hartigan's Algorithm Avoids It
Feb 10, 2026Lloyd's k-means algorithm is one of the most widely used clustering methods. We prove that in high-dimensional, high-noise settings, the algorithm exhibits catastrophic failure: with high probability, essentially every partition of the data is a fixed point. Consequently, Lloyd's algorithm simply returns its initial partition - even when the underlying clusters are trivially recoverable by other methods. In contrast, we prove that Hartigan's k-means algorithm does not exhibit this pathology. Our results show the stark difference between these algorithms and offer a theoretical explanation for the empirical difficulties often observed with k-means in high dimensions.
An Observation on Lloyd's k-Means Algorithm in High Dimensions
Jun 17, 2025Clustering and estimating cluster means are core problems in statistics and machine learning, with k-means and Expectation Maximization (EM) being two widely used algorithms. In this work, we provide a theoretical explanation for the failure of k-means in high-dimensional settings with high noise and limited sample sizes, using a simple Gaussian Mixture Model (GMM). We identify regimes where, with high probability, almost every partition of the data becomes a fixed point of the k-means algorithm. This study is motivated by challenges in the analysis of more complex cases, such as masked GMMs, and those arising from applications in Cryo-Electron Microscopy.
On Manifold Learning in Plato's Cave: Remarks on Manifold Learning and Physical Phenomena
Apr 27, 2023Many techniques in machine learning attempt explicitly or implicitly to infer a low-dimensional manifold structure of an underlying physical phenomenon from measurements without an explicit model of the phenomenon or the measurement apparatus. This paper presents a cautionary tale regarding the discrepancy between the geometry of measurements and the geometry of the underlying phenomenon in a benign setting. The deformation in the metric illustrated in this paper is mathematically straightforward and unavoidable in the general case, and it is only one of several similar effects. While this is not always problematic, we provide an example of an arguably standard and harmless data processing procedure where this effect leads to an incorrect answer to a seemingly simple question. Although we focus on manifold learning, these issues apply broadly to dimensionality reduction and unsupervised learning.
Using VAEs to Learn Latent Variables: Observations on Applications in cryo-EM
Mar 13, 2023



Variational autoencoders (VAEs) are a popular generative model used to approximate distributions. The encoder part of the VAE is used in amortized learning of latent variables, producing a latent representation for data samples. Recently, VAEs have been used to characterize physical and biological systems. In this case study, we qualitatively examine the amortization properties of a VAE used in biological applications. We find that in this application the encoder bears a qualitative resemblance to more traditional explicit representation of latent variables.
Geometric Ergodicity in Modified Variations of Riemannian Manifold and Lagrangian Monte Carlo
Jan 04, 2023Riemannian manifold Hamiltonian (RMHMC) and Lagrangian Monte Carlo (LMC) have emerged as powerful methods of Bayesian inference. Unlike Euclidean Hamiltonian Monte Carlo (EHMC) and the Metropolis-adjusted Langevin algorithm (MALA), the geometric ergodicity of these Riemannian algorithms has not been extensively studied. On the other hand, the manifold Metropolis-adjusted Langevin algorithm (MMALA) has recently been shown to exhibit geometric ergodicity under certain conditions. This work investigates the mixture of the LMC and RMHMC transition kernels with MMALA in order to equip the resulting method with an "inherited" geometric ergodicity theory. We motivate this mixture kernel based on an analogy between single-step HMC and MALA. We then proceed to evaluate the original and modified transition kernels on several benchmark Bayesian inference tasks.
Manifold Density Estimation via Generalized Dequantization
Feb 14, 2021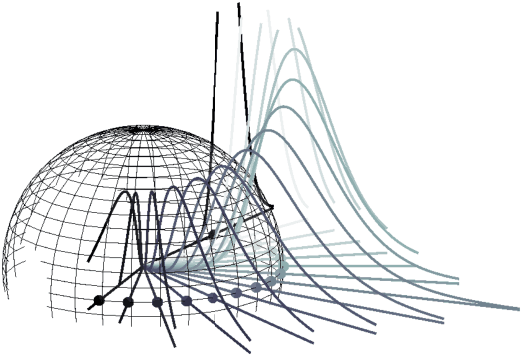

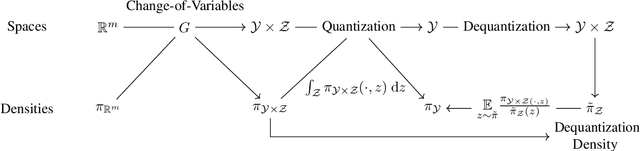

Density estimation is an important technique for characterizing distributions given observations. Much existing research on density estimation has focused on cases wherein the data lies in a Euclidean space. However, some kinds of data are not well-modeled by supposing that their underlying geometry is Euclidean. Instead, it can be useful to model such data as lying on a {\it manifold} with some known structure. For instance, some kinds of data may be known to lie on the surface of a sphere. We study the problem of estimating densities on manifolds. We propose a method, inspired by the literature on "dequantization," which we interpret through the lens of a coordinate transformation of an ambient Euclidean space and a smooth manifold of interest. Using methods from normalizing flows, we apply this method to the dequantization of smooth manifold structures in order to model densities on the sphere, tori, and the orthogonal group.
Magnetic Manifold Hamiltonian Monte Carlo
Oct 15, 2020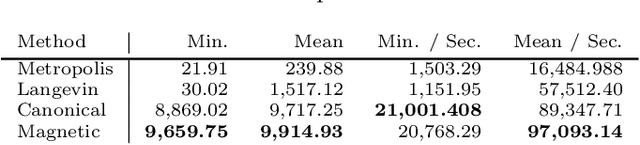
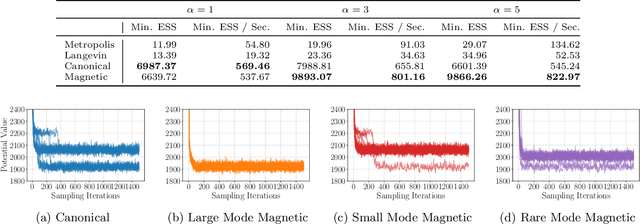
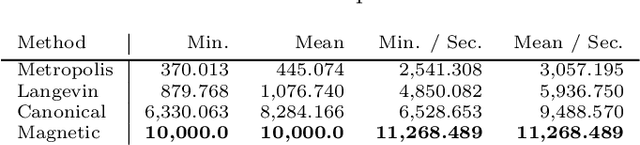
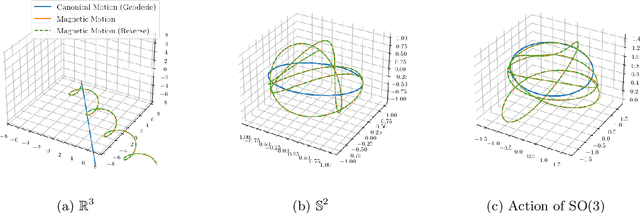
Markov chain Monte Carlo (MCMC) algorithms offer various strategies for sampling; the Hamiltonian Monte Carlo (HMC) family of samplers are MCMC algorithms which often exhibit improved mixing properties. The recently introduced magnetic HMC, a generalization of HMC motivated by the physics of particles influenced by magnetic field forces, has been demonstrated to improve the performance of HMC. In many applications, one wishes to sample from a distribution restricted to a constrained set, often manifested as an embedded manifold (for example, the surface of a sphere). We introduce magnetic manifold HMC, an HMC algorithm on embedded manifolds motivated by the physics of particles constrained to a manifold and moving under magnetic field forces. We discuss the theoretical properties of magnetic Hamiltonian dynamics on manifolds, and introduce a reversible and symplectic integrator for the HMC updates. We demonstrate that magnetic manifold HMC produces favorable sampling behaviors relative to the canonical variant of manifold-constrained HMC.
Spectral Flow on the Manifold of SPD Matrices for Multimodal Data Processing
Sep 17, 2020
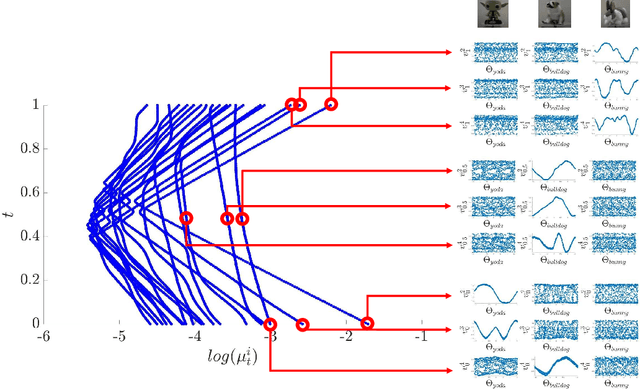
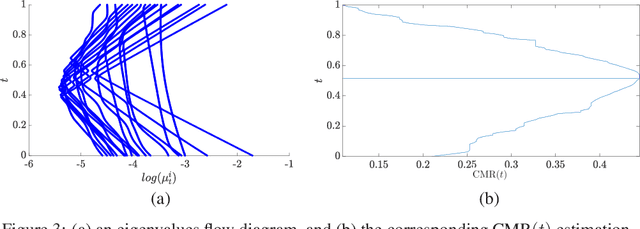
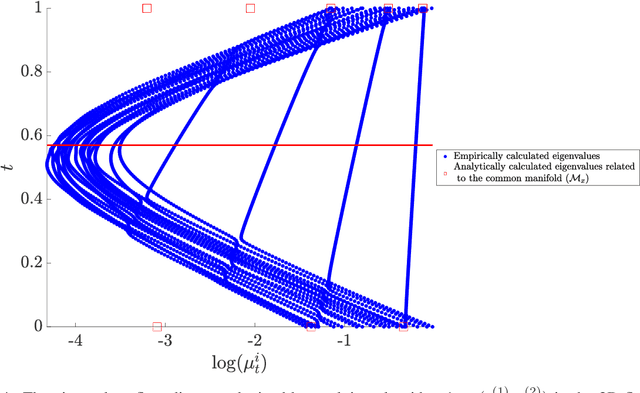
In this paper, we consider data acquired by multimodal sensors capturing complementary aspects and features of a measured phenomenon. We focus on a scenario in which the measurements share mutual sources of variability but might also be contaminated by other measurement-specific sources such as interferences or noise. Our approach combines manifold learning, which is a class of nonlinear data-driven dimension reduction methods, with the well-known Riemannian geometry of symmetric and positive-definite (SPD) matrices. Manifold learning typically includes the spectral analysis of a kernel built from the measurements. Here, we take a different approach, utilizing the Riemannian geometry of the kernels. In particular, we study the way the spectrum of the kernels changes along geodesic paths on the manifold of SPD matrices. We show that this change enables us, in a purely unsupervised manner, to derive a compact, yet informative, description of the relations between the measurements, in terms of their underlying components. Based on this result, we present new algorithms for extracting the common latent components and for identifying common and measurement-specific components.
Non-Canonical Hamiltonian Monte Carlo
Aug 18, 2020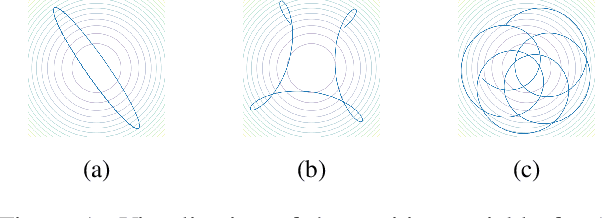
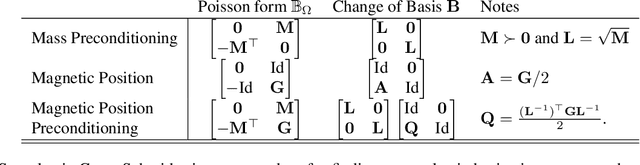
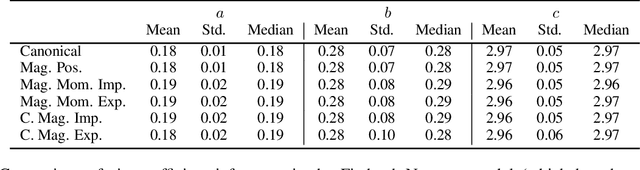
Hamiltonian Monte Carlo is typically based on the assumption of an underlying canonical symplectic structure. Numerical integrators designed for the canonical structure are incompatible with motion generated by non-canonical dynamics. These non-canonical dynamics, motivated by examples in physics and symplectic geometry, correspond to techniques such as preconditioning which are routinely used to improve algorithmic performance. Indeed, recently, a special case of non-canonical structure, magnetic Hamiltonian Monte Carlo, was demonstrated to provide advantageous sampling properties. We present a framework for Hamiltonian Monte Carlo using non-canonical symplectic structures. Our experimental results demonstrate sampling advantages associated to Hamiltonian Monte Carlo with non-canonical structure. To summarize our contributions: (i) we develop non-canonical HMC from foundations in symplectic geomtry; (ii) we construct an HMC procedure using implicit integration that satisfies the detailed balance; (iii) we propose to accelerate the sampling using an {\em approximate} explicit methodology; (iv) we study two novel, randomly-generated non-canonical structures: magnetic momentum and the coupled magnet structure, with implicit and explicit integration.