 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords ranking and Hirsch index for identifying the core of the hapaxes in political texts
Jun 13, 2020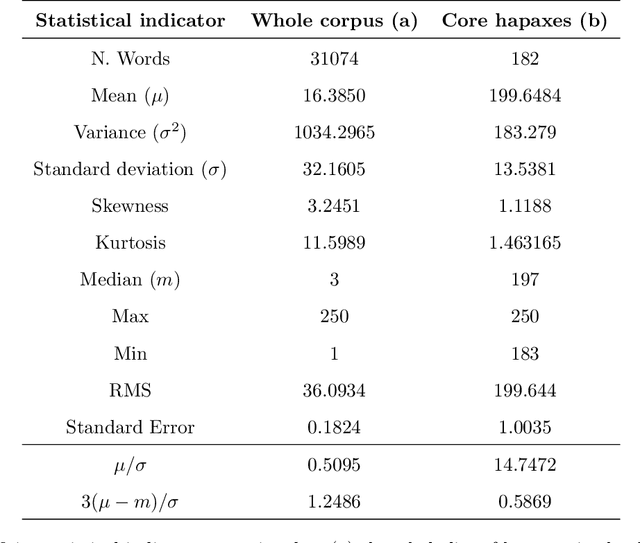

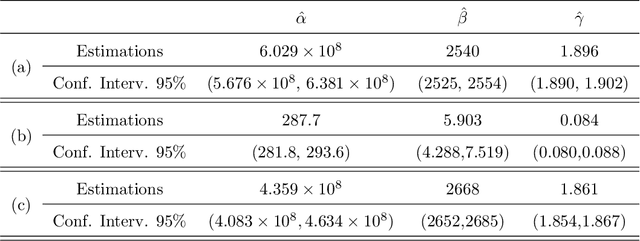
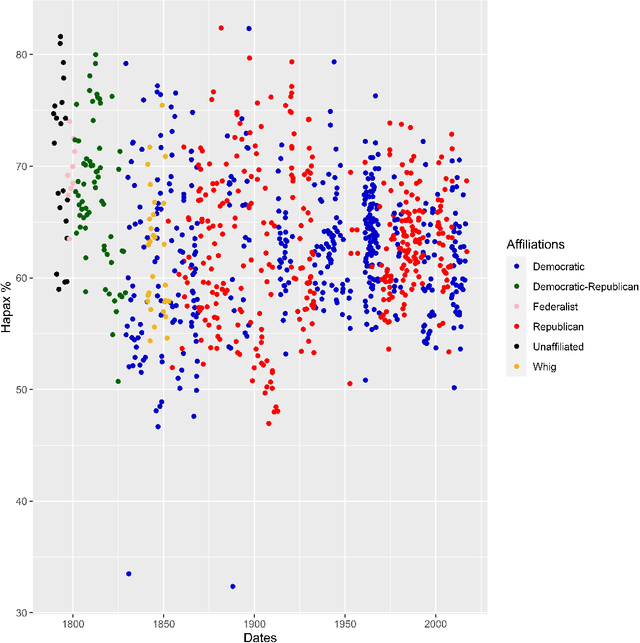
This paper deals with a quantitative analysis of the content of official political speeches. We study a set of about one thousand talks pronounced by the US Presidents, ranging from Washington to Trump. In particular, we search for the relevance of the rare words, i.e. those said only once in each speech -- the so-called hapaxes. We implement a rank-size procedure of Zipf-Mandelbrot type for discussing the hapaxes' frequencies regularity over the overall set of speeches. Starting from the obtained rank-size law, we define and detect the core of the hapaxes set by means of a procedure based on an Hirsch index variant. We discuss the resulting list of words in the light of the overall US Presidents' speeches. We further show that this core of hapaxes itself can be well fitted through a Zipf-Mandelbrot law and that contains elements producing deviations at the low ranks between scatter plots and fitted curve -- the so-called king and vice-roy effect. Some socio-political insights are derived from the obtained findings about the US Presidents messages.
A joint text mining-rank size investigation of the rhetoric structures of the US Presidents' speeches
May 09, 2019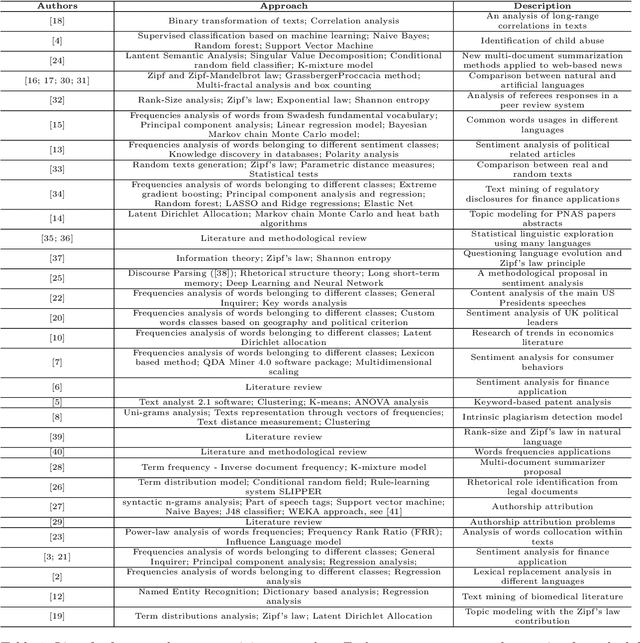
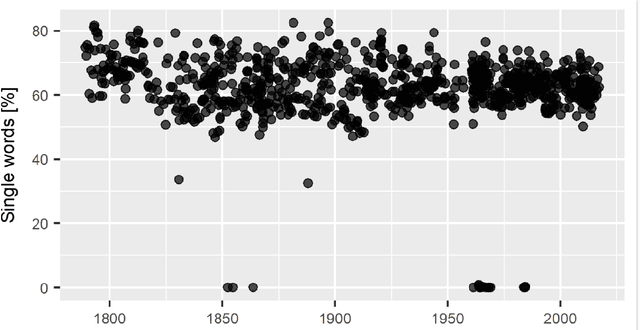
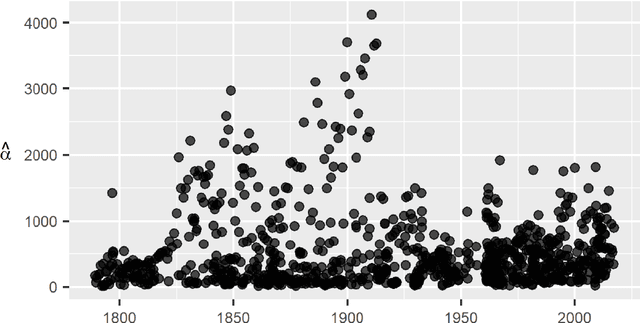
This work presents a text mining context and its use for a deep analysis of the messages delivered by the politicians. Specifically, we deal with an expert systems-based exploration of the rhetoric dynamics of a large collection of US Presidents' speeches, ranging from Washington to Trump. In particular, speeches are viewed as complex expert systems whose structures can be effectively analyzed through rank-size laws. The methodological contribution of the paper is twofold. First, we develop a text mining-based procedure for the construction of the dataset by using a web scraping routine on the Miller Center website -- the repository collecting the speeches. Second, we explore the implicit structure of the discourse data by implementing a rank-size procedure over the individual speeches, being the words of each speech ranked in terms of their frequencies. The scientific significance of the proposed combination of text-mining and rank-size approaches can be found in its flexibility and generality, which let it be reproducible to a wide set of expert systems and text mining contexts. The usefulness of the proposed method and the speech subsequent analysis is demonstrated by the findings themselves. Indeed, in terms of impact, it is worth noting that interesting conclusions of social, political and linguistic nature on how 45 United States Presidents, from April 30, 1789 till February 28, 2017 delivered political messages can be carried out. Indeed, the proposed analysis shows some remarkable regularities, not only inside a given speech, but also among different speeches. Moreover, under a purely methodological perspective, the presented contribution suggests possible ways of generating a linguistic decision-making algorithm.
* prepared for Expert Systems With Applications; 24 figures; 7 tables; 89 references