 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNudge Attacks on Point-Cloud DNNs
Nov 22, 2020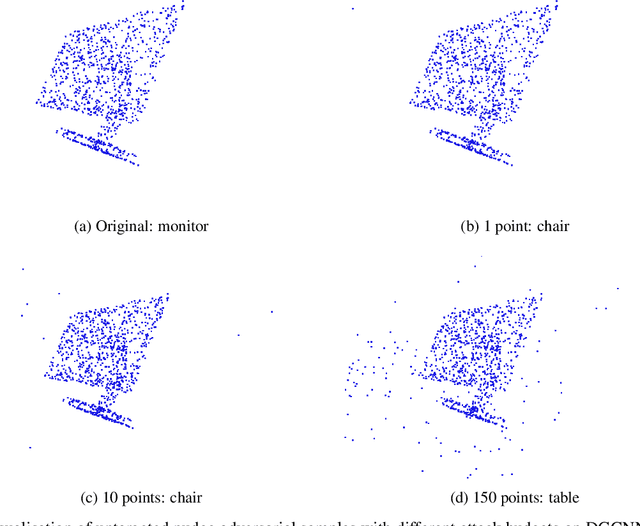
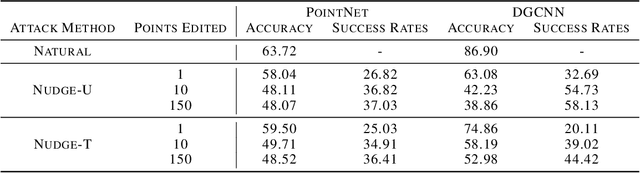
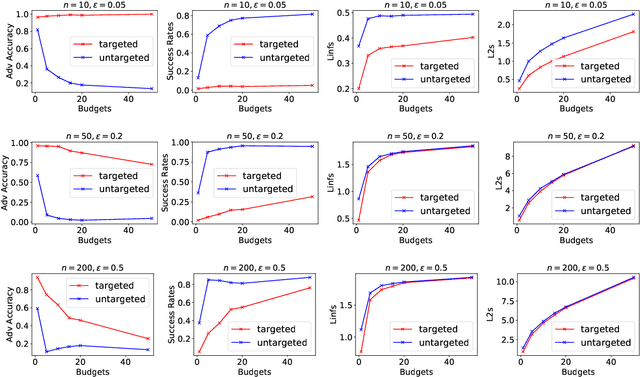
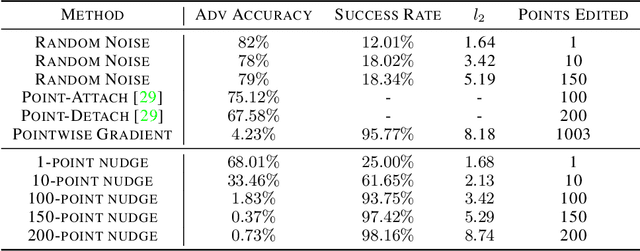
The wide adaption of 3D point-cloud data in safety-critical applications such as autonomous driving makes adversarial samples a real threat. Existing adversarial attacks on point clouds achieve high success rates but modify a large number of points, which is usually difficult to do in real-life scenarios. In this paper, we explore a family of attacks that only perturb a few points of an input point cloud, and name them nudge attacks. We demonstrate that nudge attacks can successfully flip the results of modern point-cloud DNNs. We present two variants, gradient-based and decision-based, showing their effectiveness in white-box and grey-box scenarios. Our extensive experiments show nudge attacks are effective at generating both targeted and untargeted adversarial point clouds, by changing a few points or even a single point from the entire point-cloud input. We find that with a single point we can reliably thwart predictions in 12--80% of cases, whereas 10 points allow us to further increase this to 37--95%. Finally, we discuss the possible defenses against such attacks, and explore their limitations.
Reinforcement Learning with Combinatorial Actions: An Application to Vehicle Routing
Oct 22, 2020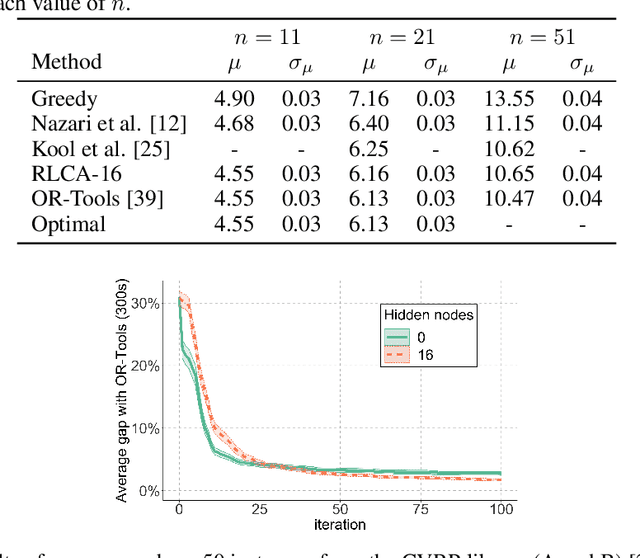
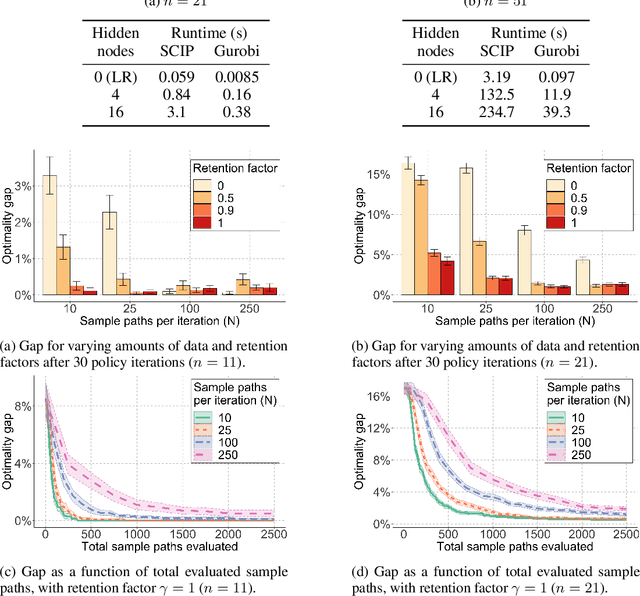
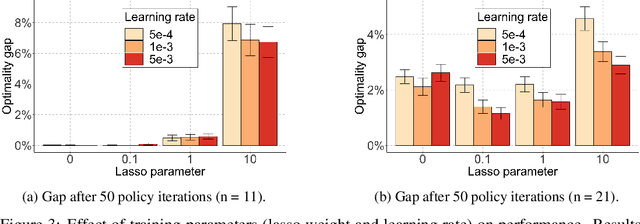
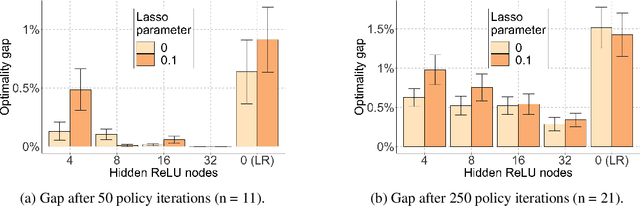
Value-function-based methods have long played an important role in reinforcement learning. However, finding the best next action given a value function of arbitrary complexity is nontrivial when the action space is too large for enumeration. We develop a framework for value-function-based deep reinforcement learning with a combinatorial action space, in which the action selection problem is explicitly formulated as a mixed-integer optimization problem. As a motivating example, we present an application of this framework to the capacitated vehicle routing problem (CVRP), a combinatorial optimization problem in which a set of locations must be covered by a single vehicle with limited capacity. On each instance, we model an action as the construction of a single route, and consider a deterministic policy which is improved through a simple policy iteration algorithm. Our approach is competitive with other reinforcement learning methods and achieves an average gap of 1.7% with state-of-the-art OR methods on standard library instances of medium size.
The Convex Relaxation Barrier, Revisited: Tightened Single-Neuron Relaxations for Neural Network Verification
Jun 24, 2020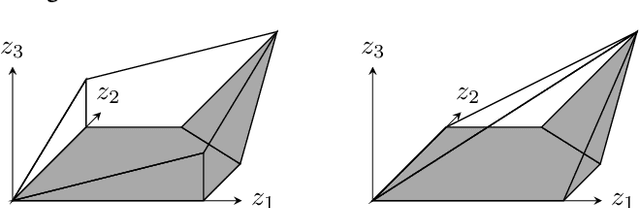
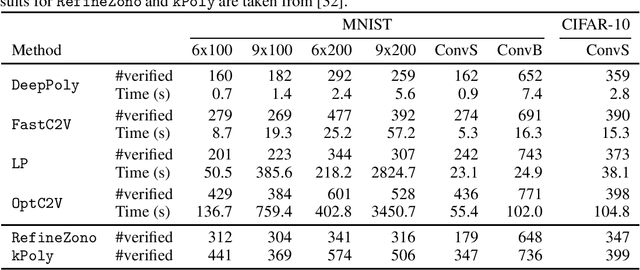
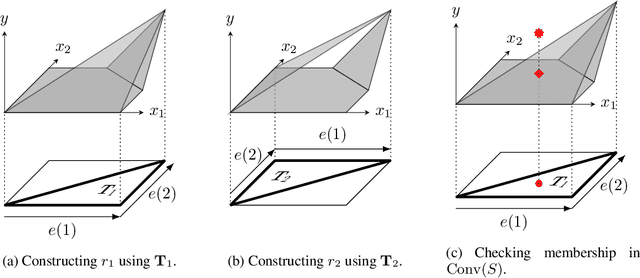
We improve the effectiveness of propagation- and linear-optimization-based neural network verification algorithms with a new tightened convex relaxation for ReLU neurons. Unlike previous single-neuron relaxations which focus only on the univariate input space of the ReLU, our method considers the multivariate input space of the affine pre-activation function preceding the ReLU. Using results from submodularity and convex geometry, we derive an explicit description of the tightest possible convex relaxation when this multivariate input is over a box domain. We show that our convex relaxation is significantly stronger than the commonly used univariate-input relaxation which has been proposed as a natural convex relaxation barrier for verification. While our description of the relaxation may require an exponential number of inequalities, we show that they can be separated in linear time and hence can be efficiently incorporated into optimization algorithms on an as-needed basis. Based on this novel relaxation, we design two polynomial-time algorithms for neural network verification: a linear-programming-based algorithm that leverages the full power of our relaxation, and a fast propagation algorithm that generalizes existing approaches. In both cases, we show that for a modest increase in computational effort, our strengthened relaxation enables us to verify a significantly larger number of instances compared to similar algorithms.
Sponge Examples: Energy-Latency Attacks on Neural Networks
Jun 05, 2020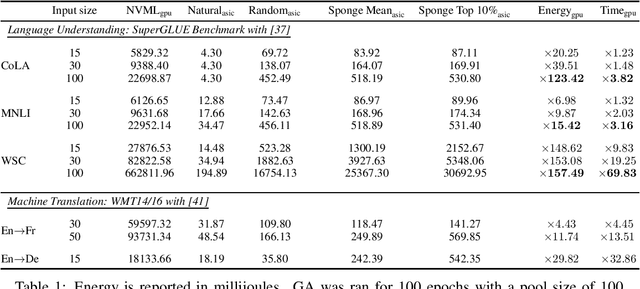
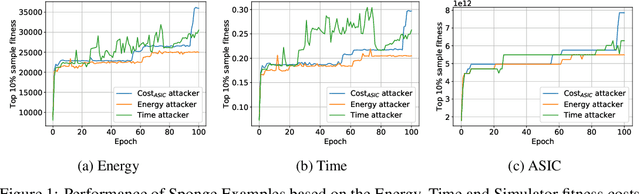
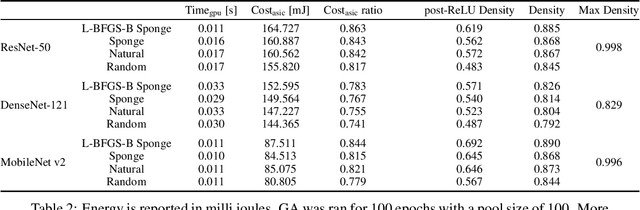
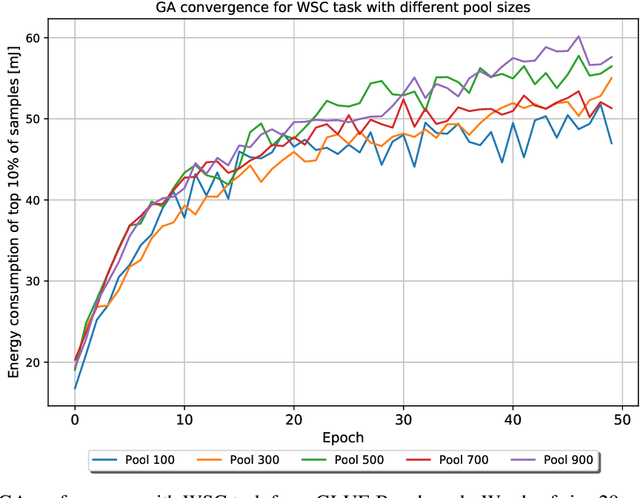
The high energy costs of neural network training and inference led to the use of acceleration hardware such as GPUs and TPUs. While this enabled us to train large-scale neural networks in datacenters and deploy them on edge devices, the focus so far is on average-case performance. In this work, we introduce a novel threat vector against neural networks whose energy consumption or decision latency are critical. We show how adversaries can exploit carefully crafted $\boldsymbol{sponge}~\boldsymbol{examples}$, which are inputs designed to maximise energy consumption and latency. We mount two variants of this attack on established vision and language models, increasing energy consumption by a factor of 10 to 200. Our attacks can also be used to delay decisions where a network has critical real-time performance, such as in perception for autonomous vehicles. We demonstrate the portability of our malicious inputs across CPUs and a variety of hardware accelerator chips including GPUs, and an ASIC simulator. We conclude by proposing a defense strategy which mitigates our attack by shifting the analysis of energy consumption in hardware from an average-case to a worst-case perspective.
Towards Certifiable Adversarial Sample Detection
Feb 20, 2020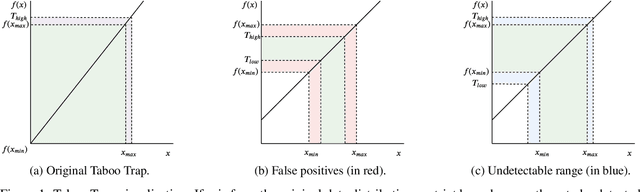
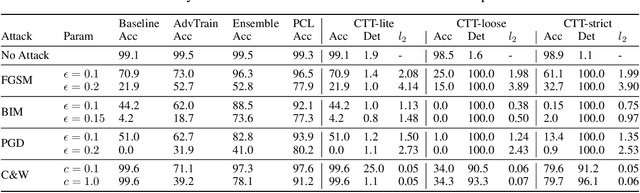
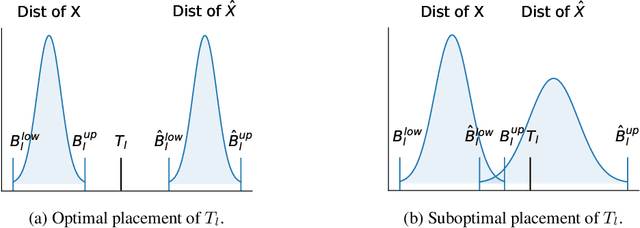
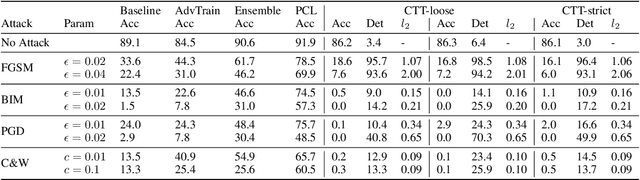
Convolutional Neural Networks (CNNs) are deployed in more and more classification systems, but adversarial samples can be maliciously crafted to trick them, and are becoming a real threat. There have been various proposals to improve CNNs' adversarial robustness but these all suffer performance penalties or other limitations. In this paper, we provide a new approach in the form of a certifiable adversarial detection scheme, the Certifiable Taboo Trap (CTT). The system can provide certifiable guarantees of detection of adversarial inputs for certain $l_{\infty}$ sizes on a reasonable assumption, namely that the training data have the same distribution as the test data. We develop and evaluate several versions of CTT with a range of defense capabilities, training overheads and certifiability on adversarial samples. Against adversaries with various $l_p$ norms, CTT outperforms existing defense methods that focus purely on improving network robustness. We show that CTT has small false positive rates on clean test data, minimal compute overheads when deployed, and can support complex security policies.
CAQL: Continuous Action Q-Learning
Oct 09, 2019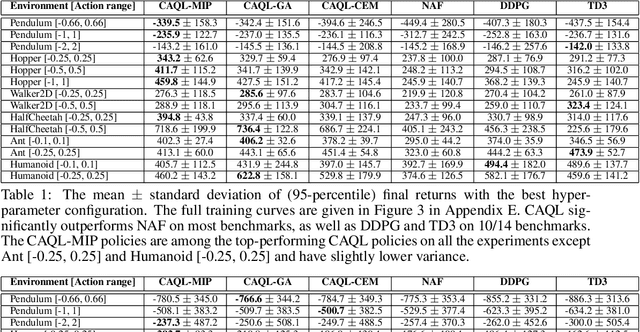
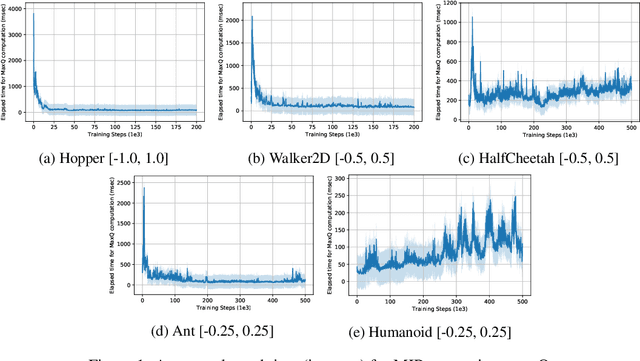
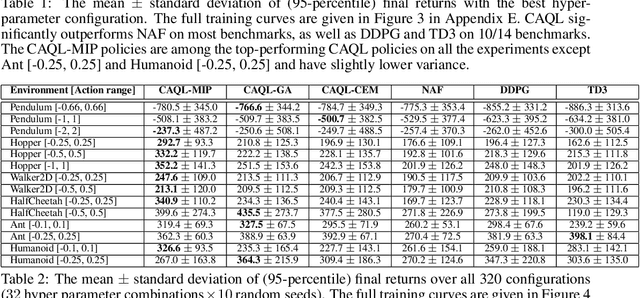
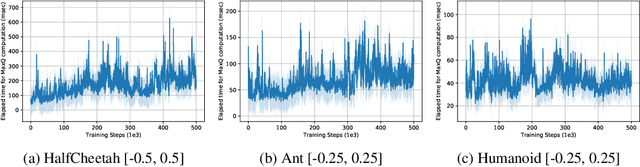
Value-based reinforcement learning (RL) methods like Q-learning have shown success in a variety of domains. One challenge in applying Q-learning to continuous-action RL problems, however, is the continuous action maximization (max-Q) required for optimal Bellman backup. In this work, we develop CAQL, a (class of) algorithm(s) for continuous-action Q-learning that can use several plug-and-play optimizers for the max-Q problem. Leveraging recent optimization results for deep neural networks, we show that max-Q can be solved optimally using mixed-integer programming (MIP). When the Q-function representation has sufficient power, MIP-based optimization gives rise to better policies and is more robust than approximate methods (e.g., gradient ascent, cross-entropy search). We further develop several techniques to accelerate inference in CAQL, which despite their approximate nature, perform well. We compare CAQL with state-of-the-art RL algorithms on benchmark continuous-control problems that have different degrees of action constraints and show that CAQL outperforms policy-based methods in heavily constrained environments, often dramatically.
Blackbox Attacks on Reinforcement Learning Agents Using Approximated Temporal Information
Sep 06, 2019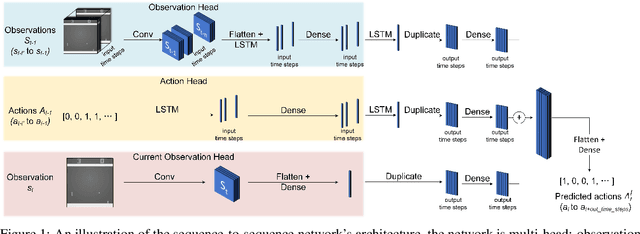


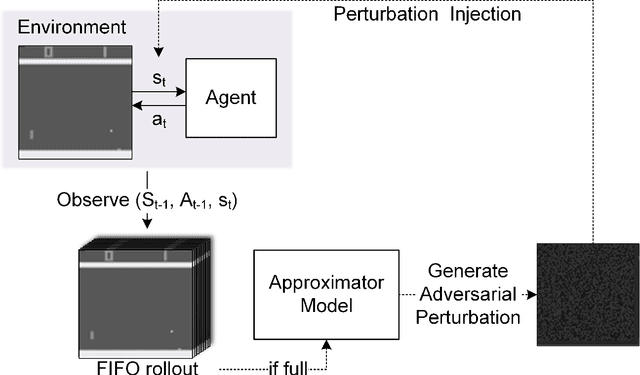
Recent research on reinforcement learning has shown that trained agents are vulnerable to maliciously crafted adversarial samples. In this work, we show how adversarial samples against RL agents can be generalised from White-box and Grey-box attacks to a strong Black-box case, namely where the attacker has no knowledge of the agents and their training methods. We use sequence-to-sequence models to predict a single action or a sequence of future actions that a trained agent will make. Our approximation model, based on time-series information from the agent, successfully predicts agents' future actions with consistently above 80% accuracy on a wide range of games and training methods. Second, we find that although such adversarial samples are transferable, they do not outperform random Gaussian noise as a means of reducing the game scores of trained RL agents. This highlights a serious methodological deficiency in previous work on such agents; random jamming should have been taken as the baseline for evaluation. Third, we do find a novel use for adversarial samples in this context: they can be used to trigger a trained agent to misbehave after a specific delay. This appears to be a genuinely new type of attack; it potentially enables an attacker to use devices controlled by RL agents as time bombs.
Hearing your touch: A new acoustic side channel on smartphones
Mar 26, 2019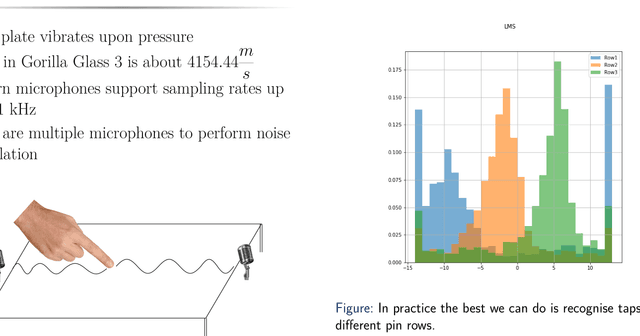
We present the first acoustic side-channel attack that recovers what users type on the virtual keyboard of their touch-screen smartphone or tablet. When a user taps the screen with a finger, the tap generates a sound wave that propagates on the screen surface and in the air. We found the device's microphone(s) can recover this wave and "hear" the finger's touch, and the wave's distortions are characteristic of the tap's location on the screen. Hence, by recording audio through the built-in microphone(s), a malicious app can infer text as the user enters it on their device. We evaluate the effectiveness of the attack with 45 participants in a real-world environment on an Android tablet and an Android smartphone. For the tablet, we recover 61% of 200 4-digit PIN-codes within 20 attempts, even if the model is not trained with the victim's data. For the smartphone, we recover 9 words of size 7--13 letters with 50 attempts in a common side-channel attack benchmark. Our results suggest that it not always sufficient to rely on isolation mechanisms such as TrustZone to protect user input. We propose and discuss hardware, operating-system and application-level mechanisms to block this attack more effectively. Mobile devices may need a richer capability model, a more user-friendly notification system for sensor usage and a more thorough evaluation of the information leaked by the underlying hardware.
Sitatapatra: Blocking the Transfer of Adversarial Samples
Jan 23, 2019
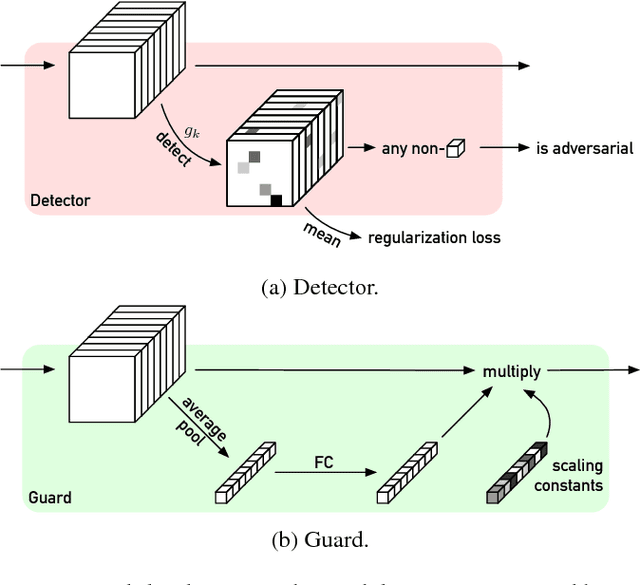
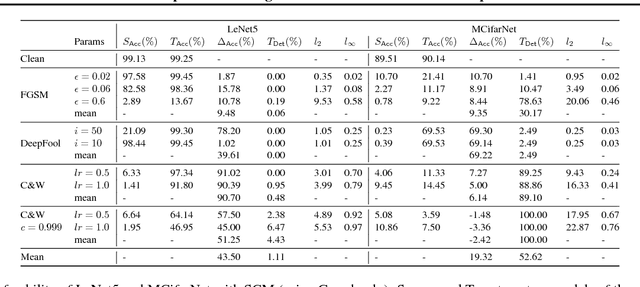
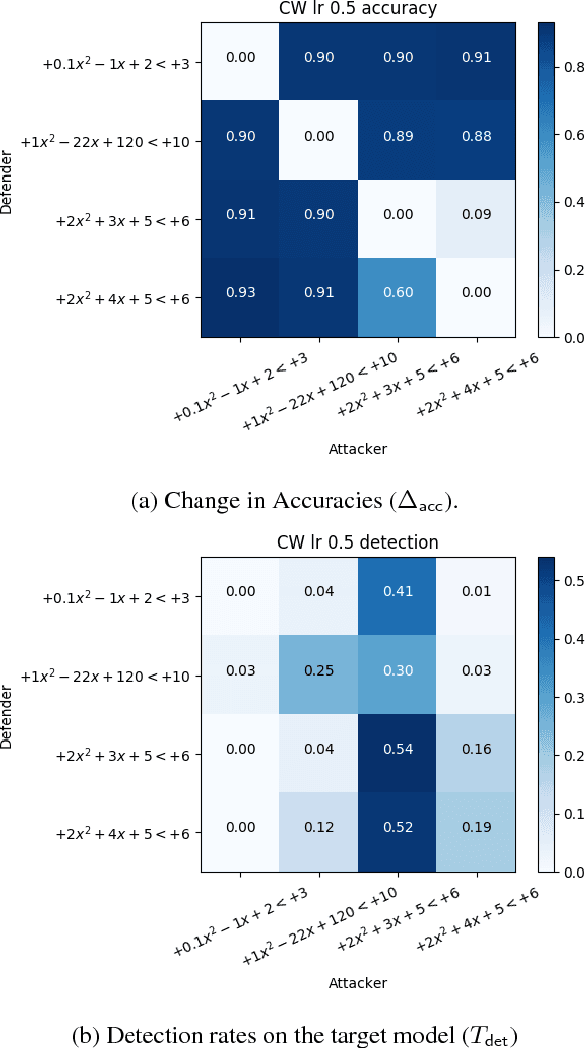
Convolutional Neural Networks (CNNs) are widely used to solve classification tasks in computer vision. However, they can be tricked into misclassifying specially crafted `adversarial' samples -- and samples built to trick one model often work alarmingly well against other models trained on the same task. In this paper we introduce Sitatapatra, a system designed to block the transfer of adversarial samples. It diversifies neural networks using a key, as in cryptography, and provides a mechanism for detecting attacks. What's more, when adversarial samples are detected they can typically be traced back to the individual device that was used to develop them. The run-time overheads are minimal permitting the use of Sitatapatra on constrained systems.
Strong mixed-integer programming formulations for trained neural networks
Nov 20, 2018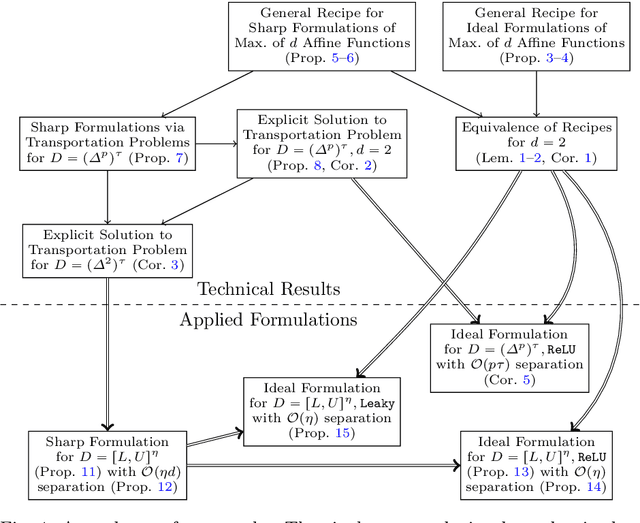

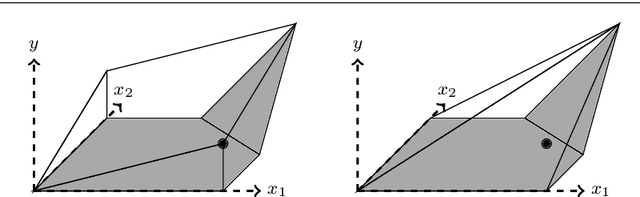

We present an ideal mixed-integer programming (MIP) formulation for a rectified linear unit (ReLU) appearing in a trained neural network. Our formulation requires a single binary variable and no additional continuous variables beyond the input and output variables of the ReLU. We contrast it with an ideal "extended" formulation with a linear number of additional continuous variables, derived through standard techniques. An apparent drawback of our formulation is that it requires an exponential number of inequality constraints, but we provide a routine to separate the inequalities in linear time. We also prove that these exponentially-many constraints are facet-defining under mild conditions. Finally, we present computational results showing that dynamically separating from the exponential inequalities 1) is much more computationally efficient and scalable than the extended formulation, 2) decreases the solve time of a state-of-the-art MIP solver by a factor of 7 on smaller instances, and 3) nearly matches the dual bounds of a state-of-the-art MIP solver on harder instances, after just a few rounds of separation and in orders of magnitude less time.