 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of graph models to achieve individual and group fairness
Jan 13, 2026Machine Learning algorithms are ubiquitous in key decision-making contexts such as justice, healthcare and finance, which has spawned a great demand for fairness in these procedures. However, the theoretical properties of such models in relation with fairness are still poorly understood, and the intuition behind the relationship between group and individual fairness is still lacking. In this paper, we provide a theoretical framework based on Sheaf Diffusion to leverage tools based on dynamical systems and homology to model fairness. Concretely, the proposed method projects input data into a bias-free space that encodes fairness constrains, resulting in fair solutions. Furthermore, we present a collection of network topologies handling different fairness metrics, leading to a unified method capable of dealing with both individual and group bias. The resulting models have a layer of interpretability in the form of closed-form expressions for their SHAP values, consolidating their place in the responsible Artificial Intelligence landscape. Finally, these intuitions are tested on a simulation study and standard fairness benchmarks, where the proposed methods achieve satisfactory results. More concretely, the paper showcases the performance of the proposed models in terms of accuracy and fairness, studying available trade-offs on the Pareto frontier, checking the effects of changing the different hyper-parameters, and delving into the interpretation of its outputs.
The more the merrier: logical and multistage processors in credit scoring
Mar 31, 2025Machine Learning algorithms are ubiquitous in key decision-making contexts such as organizational justice or healthcare, which has spawned a great demand for fairness in these procedures. In this paper we focus on the application of fair ML in finance, more concretely on the use of fairness techniques on credit scoring. This paper makes two contributions. On the one hand, it addresses the existent gap concerning the application of established methods in the literature to the case of multiple sensitive variables through the use of a new technique called logical processors (LP). On the other hand, it also explores the novel method of multistage processors (MP) to investigate whether the combination of fairness methods can work synergistically to produce solutions with improved fairness or accuracy. Furthermore, we examine the intersection of these two lines of research by exploring the integration of fairness methods in the multivariate case. The results are very promising and suggest that logical processors are an appropriate way of handling multiple sensitive variables. Furthermore, multistage processors are capable of improving the performance of existing methods.
nn2poly: An R Package for Converting Neural Networks into Interpretable Polynomials
Jun 03, 2024



The nn2poly package provides the implementation in R of the NN2Poly method to explain and interpret feed-forward neural networks by means of polynomial representations that predict in an equivalent manner as the original network.Through the obtained polynomial coefficients, the effect and importance of each variable and their interactions on the output can be represented. This capabiltiy of capturing interactions is a key aspect usually missing from most Explainable Artificial Intelligence (XAI) methods, specially if they rely on expensive computations that can be amplified when used on large neural networks. The package provides integration with the main deep learning framework packages in R (tensorflow and torch), allowing an user-friendly application of the NN2Poly algorithm. Furthermore, nn2poly provides implementation of the required weight constraints to be used during the network training in those same frameworks. Other neural networks packages can also be used by including their weights in list format. Polynomials obtained with nn2poly can also be used to predict with new data or be visualized through its own plot method. Simulations are provided exemplifying the usage of the package alongside with a comparison with other approaches available in R to interpret neural networks.
NN2Poly: A polynomial representation for deep feed-forward artificial neural networks
Dec 21, 2021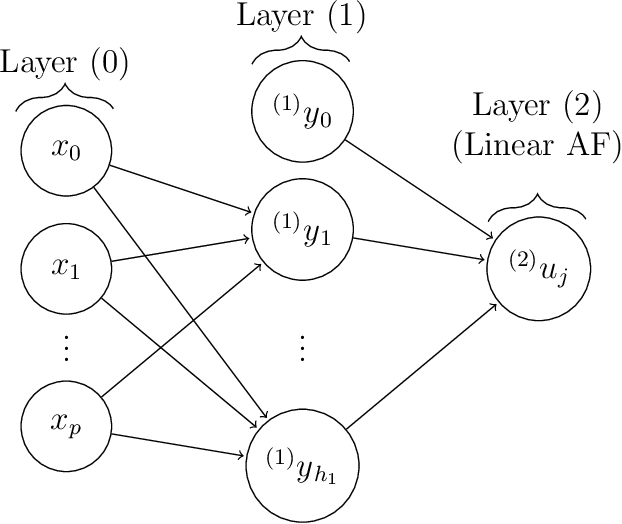

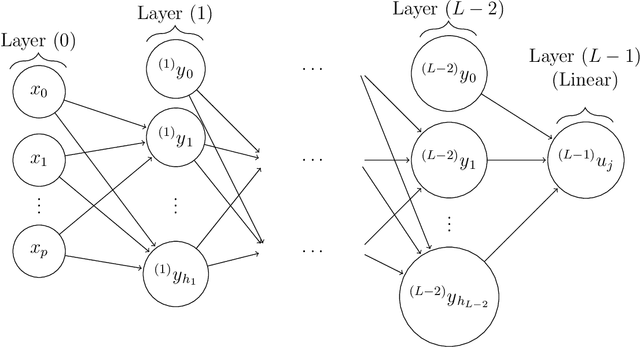
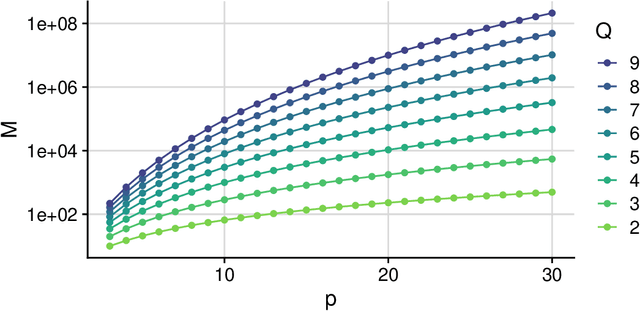
Interpretability of neural networks and their underlying theoretical behaviour remain being an open field of study, even after the great success of their practical applications, particularly with the emergence of deep learning. In this work, NN2Poly is proposed: a theoretical approach that allows to obtain polynomials that provide an alternative representation of an already trained deep neural network. This extends the previous idea proposed in arXiv:2102.03865, which was limited to single hidden layer neural networks, to work with arbitrarily deep feed-forward neural networks in both regression and classification tasks. The objective of this paper is achieved by using a Taylor expansion on the activation function, at each layer, and then using several combinatorial properties that allow to identify the coefficients of the desired polynomials. The main computational limitations when implementing this theoretical method are discussed and it is presented an example of the constraints on the neural network weights that are necessary for NN2Poly to work. Finally, some simulations are presented were it is concluded that using NN2Poly it is possible to obtain a representation for the given neural network with low error between the obtained predictions.
Towards a mathematical framework to inform Neural Network modelling via Polynomial Regression
Feb 07, 2021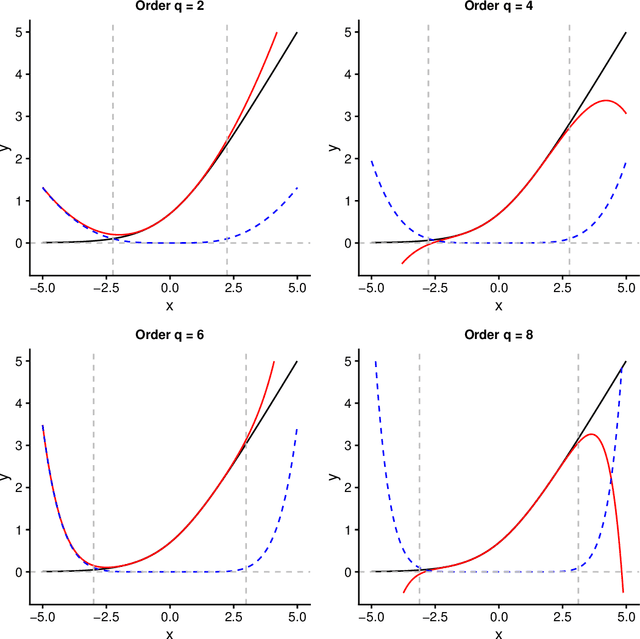
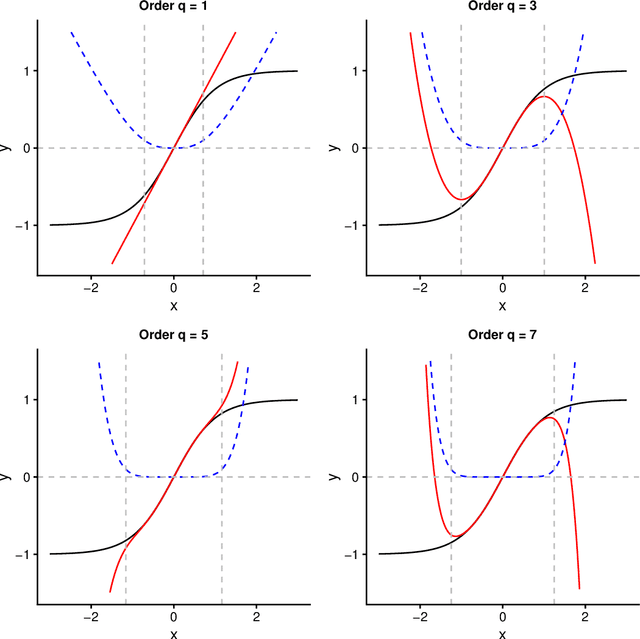
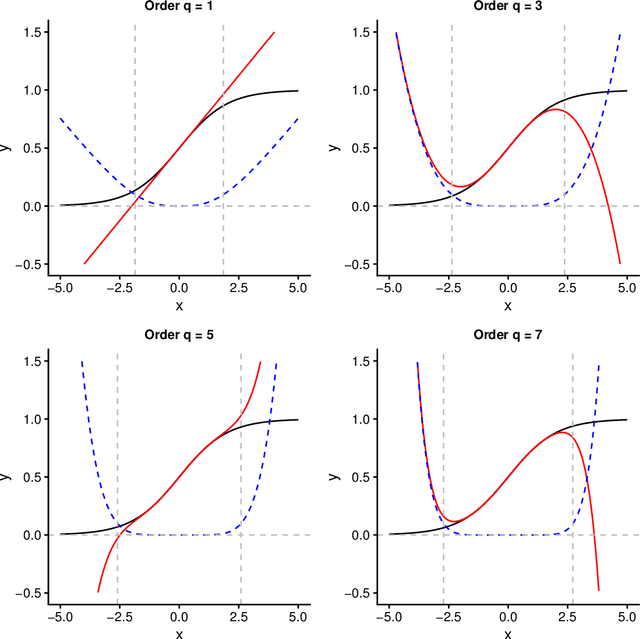
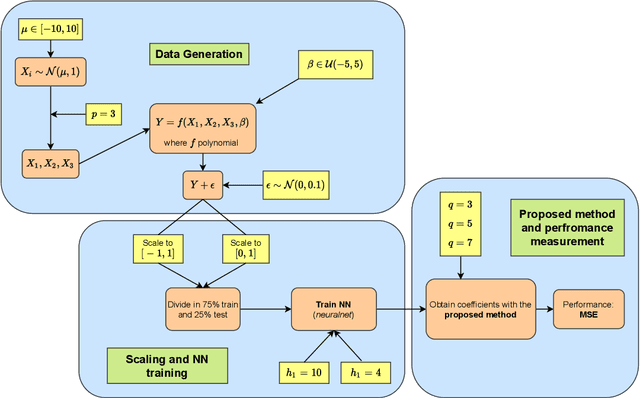
Even when neural networks are widely used in a large number of applications, they are still considered as black boxes and present some difficulties for dimensioning or evaluating their prediction error. This has led to an increasing interest in the overlapping area between neural networks and more traditional statistical methods, which can help overcome those problems. In this article, a mathematical framework relating neural networks and polynomial regression is explored by building an explicit expression for the coefficients of a polynomial regression from the weights of a given neural network, using a Taylor expansion approach. This is achieved for single hidden layer neural networks in regression problems. The validity of the proposed method depends on different factors like the distribution of the synaptic potentials or the chosen activation function. The performance of this method is empirically tested via simulation of synthetic data generated from polynomials to train neural networks with different structures and hyperparameters, showing that almost identical predictions can be obtained when certain conditions are met. Lastly, when learning from polynomial generated data, the proposed method produces polynomials that approximate correctly the data locally.
Automatic elimination of the pectoral muscle in mammograms based on anatomical features
Aug 17, 2020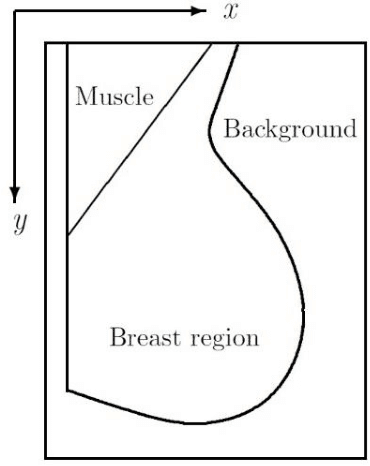
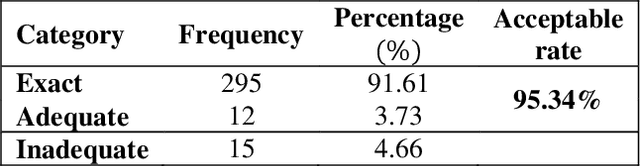
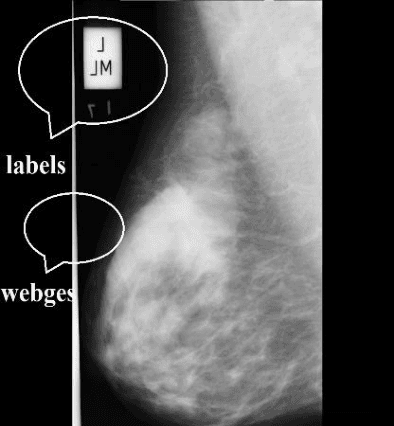
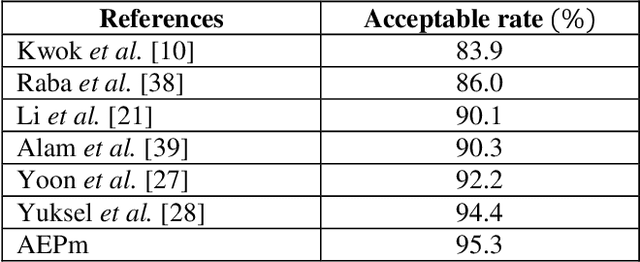
Digital mammogram inspection is the most popular technique for early detection of abnormalities in human breast tissue. When mammograms are analyzed through a computational method, the presence of the pectoral muscle might affect the results of breast lesions detection. This problem is particularly evident in the mediolateral oblique view (MLO), where pectoral muscle occupies a large part of the mammography. Therefore, identifying and eliminating the pectoral muscle are essential steps for improving the automatic discrimination of breast tissue. In this paper, we propose an approach based on anatomical features to tackle this problem. Our method consists of two steps: (1) a process to remove the noisy elements such as labels, markers, scratches and wedges, and (2) application of an intensity transformation based on the Beta distribution. The novel methodology is tested with 322 digital mammograms from the Mammographic Image Analysis Society (mini-MIAS) database and with a set of 84 mammograms for which the area normalized error was previously calculated. The results show a very good performance of the method.
The Mahalanobis distance for functional data with applications to classification
Apr 17, 2013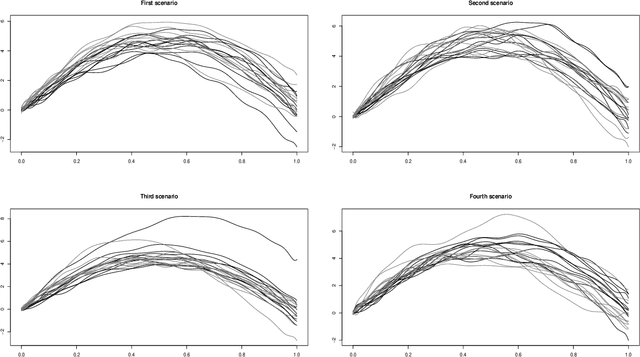
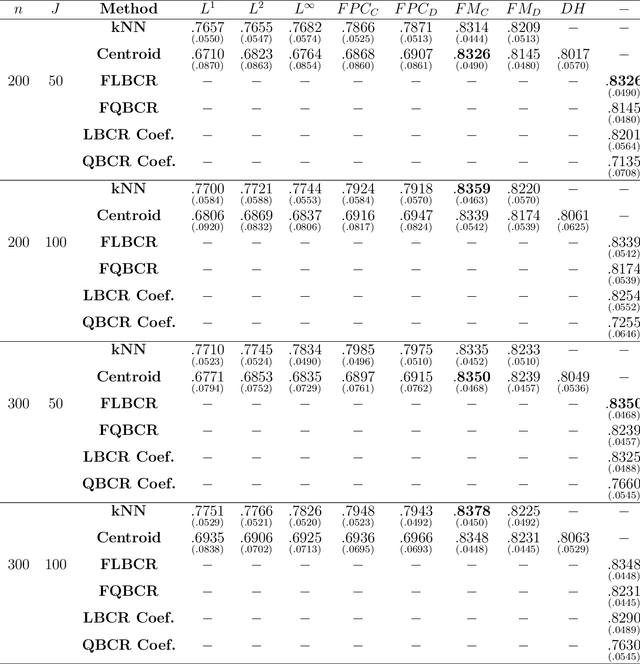
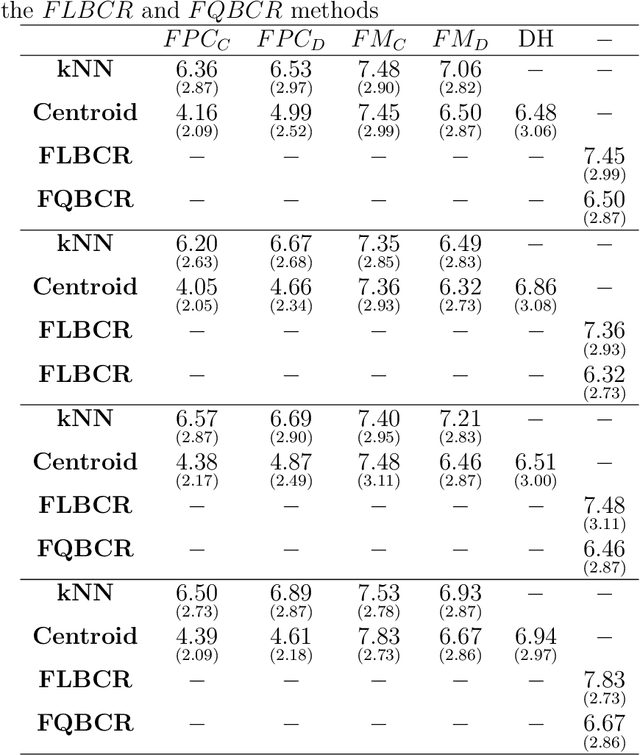
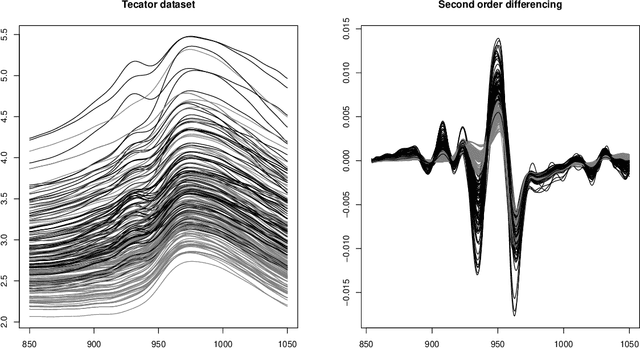
This paper presents a general notion of Mahalanobis distance for functional data that extends the classical multivariate concept to situations where the observed data are points belonging to curves generated by a stochastic process. More precisely, a new semi-distance for functional observations that generalize the usual Mahalanobis distance for multivariate datasets is introduced. For that, the development uses a regularized square root inverse operator in Hilbert spaces. Some of the main characteristics of the functional Mahalanobis semi-distance are shown. Afterwards, new versions of several well known functional classification procedures are developed using the Mahalanobis distance for functional data as a measure of proximity between functional observations. The performance of several well known functional classification procedures are compared with those methods used in conjunction with the Mahalanobis distance for functional data, with positive results, through a Monte Carlo study and the analysis of two real data examples.