 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadrature-TreeSHAP: Depth-Independent TreeSHAP and Shapley Interactions
May 06, 2026Shapley values are a standard tool for explaining predictions of tree ensembles, with Path-Dependent SHAP being the most widely used variant. Despite substantial progress, existing methods still exhibit trade-offs between depth-dependent runtime, numerical stability, and support for higher-order interactions. To address these challenges, we introduce Quadrature-TreeSHAP, a quadrature-based reformulation of Path-Dependent TreeSHAP that is numerically stable, naturally extends to any-order Shapley interaction values and is practically insensitive to tree depth. Our implementation supports both CPU and GPU and is integrated into XGBoost. Our method is based on a weighted-Banzhaf interaction polynomial, which expresses Banzhaf interaction values as expectations under a feature participation probability $p$. Shapley values and any-order interaction values are then recovered by integrating these polynomials over $p$ from 0 to 1. We evaluate these integrals using Gauss-Legendre quadrature, and show that, in practice, only 8 fixed quadrature points are sufficient to reach machine precision. In fact, Quadrature-TreeSHAP with 8 fixed points achieves greater numerical stability than TreeSHAP. This fixed-point formulation removes depth dependence from the inner computation and enables efficient SIMD execution. We confirm these advantages empirically. On 12 XGBoost benchmarks, Quadrature-TreeSHAP computes Shapley values 1.06x-10.59x faster than TreeSHAP on CPU and 1.84x-6.95x faster than GPUTreeSHAP on GPU. Shapley pairwise interactions are 3.80x-58.11x faster on CPU, with higher-order interactions achieving speedups of up to 1200x compared to TreeSHAP-IQ.
Sampling Permutations for Shapley Value Estimation
Apr 25, 2021

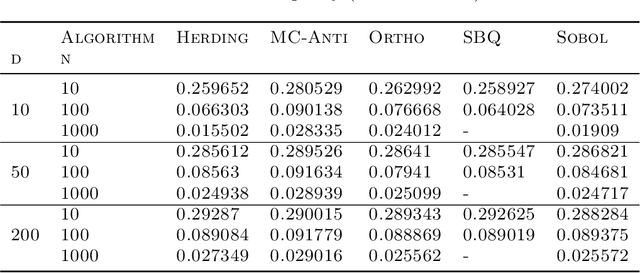
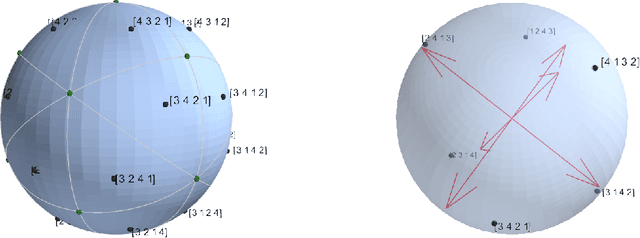
Game-theoretic attribution techniques based on Shapley values are used extensively to interpret black-box machine learning models, but their exact calculation is generally NP-hard, requiring approximation methods for non-trivial models. As the computation of Shapley values can be expressed as a summation over a set of permutations, a common approach is to sample a subset of these permutations for approximation. Unfortunately, standard Monte Carlo sampling methods can exhibit slow convergence, and more sophisticated quasi Monte Carlo methods are not well defined on the space of permutations. To address this, we investigate new approaches based on two classes of approximation methods and compare them empirically. First, we demonstrate quadrature techniques in a RKHS containing functions of permutations, using the Mallows kernel to obtain explicit convergence rates of $O(1/n)$, improving on $O(1/\sqrt{n})$ for plain Monte Carlo. The RKHS perspective also leads to quasi Monte Carlo type error bounds, with a tractable discrepancy measure defined on permutations. Second, we exploit connections between the hypersphere $\mathbb{S}^{d-2}$ and permutations to create practical algorithms for generating permutation samples with good properties. Experiments show the above techniques provide significant improvements for Shapley value estimates over existing methods, converging to a smaller RMSE in the same number of model evaluations.
GPUTreeShap: Fast Parallel Tree Interpretability
Oct 27, 2020
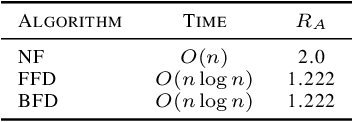

SHAP (SHapley Additive exPlanation) values provide a game theoretic interpretation of the predictions of machine learning models based on Shapley values. While SHAP values are intractable in general, a recursive polynomial time algorithm specialised for decision tree models is available, named TreeShap. Despite its polynomial time complexity, TreeShap can become a significant bottleneck in practical machine learning pipelines when applied to large decision tree ensembles. We present GPUTreeShap, a software package implementing a modified TreeShap algorithm in CUDA for Nvidia GPUs. Our approach first preprocesses the input model to isolate variable sized sub-problems from the original recursive algorithm, then solves a bin packing problem, and finally maps sub-problems to streaming multiprocessors for parallel execution with specialised hardware instructions. With a single GPU, we achieve speedups of up to 19x for SHAP values, and 340x for SHAP interaction values, over a state-of-the-art multi-core CPU implementation. We also experiment with an 8 GPU DGX-1 system, demonstrating throughput of 1.2M rows per second---equivalent CPU-based performance is estimated to require 6850 CPU cores.
Adaptive XGBoost for Evolving Data Streams
May 15, 2020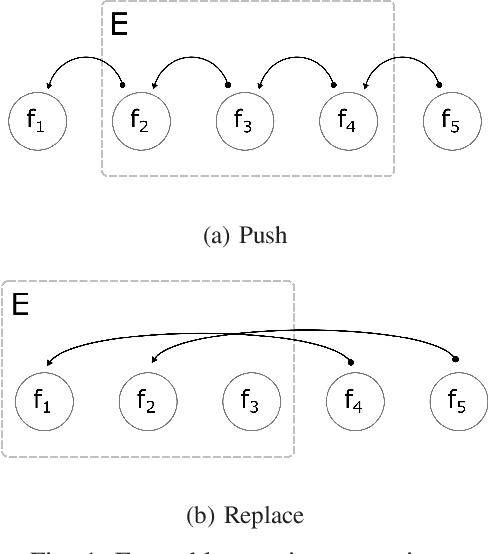
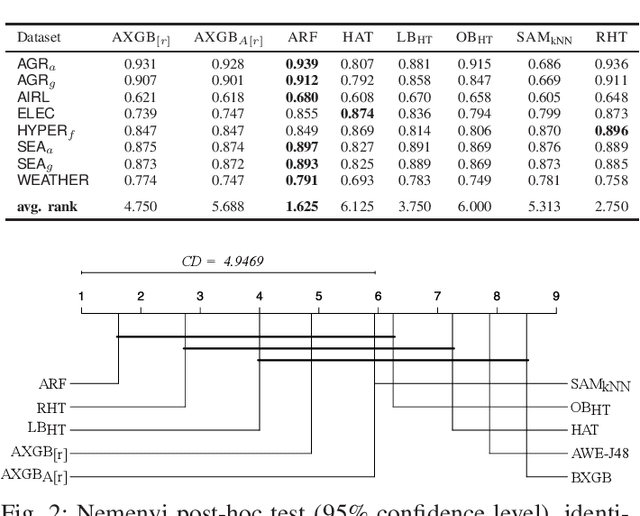
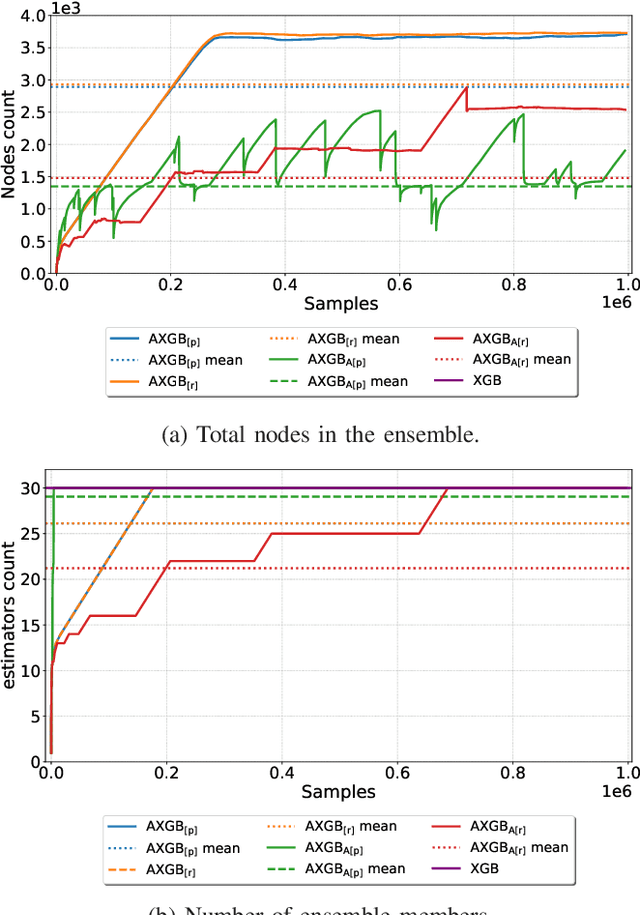
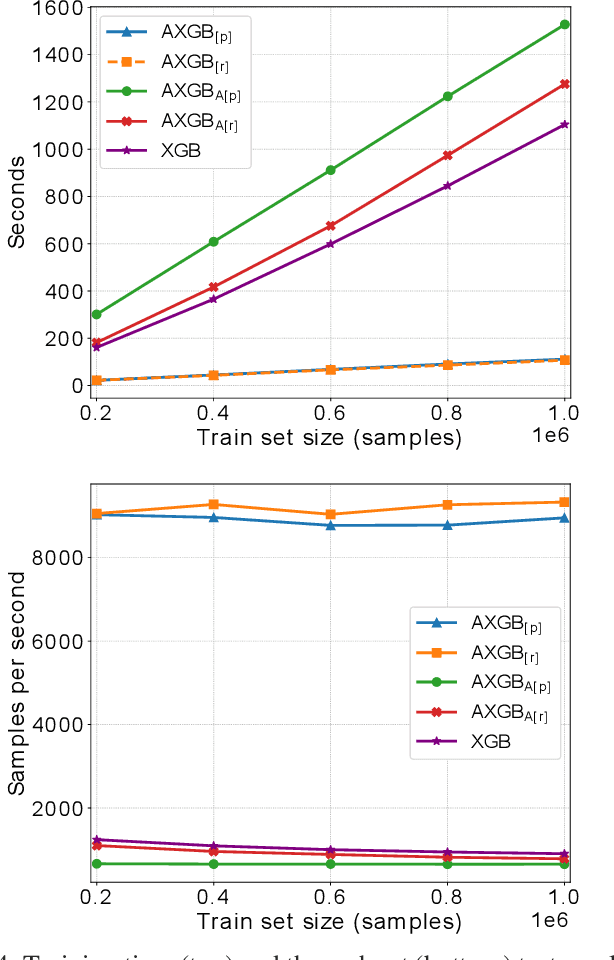
Boosting is an ensemble method that combines base models in a sequential manner to achieve high predictive accuracy. A popular learning algorithm based on this ensemble method is eXtreme Gradient Boosting (XGB). We present an adaptation of XGB for classification of evolving data streams. In this setting, new data arrives over time and the relationship between the class and the features may change in the process, thus exhibiting concept drift. The proposed method creates new members of the ensemble from mini-batches of data as new data becomes available. The maximum ensemble size is fixed, but learning does not stop when this size is reached because the ensemble is updated on new data to ensure consistency with the current concept. We also explore the use of concept drift detection to trigger a mechanism to update the ensemble. We test our method on real and synthetic data with concept drift and compare it against batch-incremental and instance-incremental classification methods for data streams.
XGBoost: Scalable GPU Accelerated Learning
Jun 29, 2018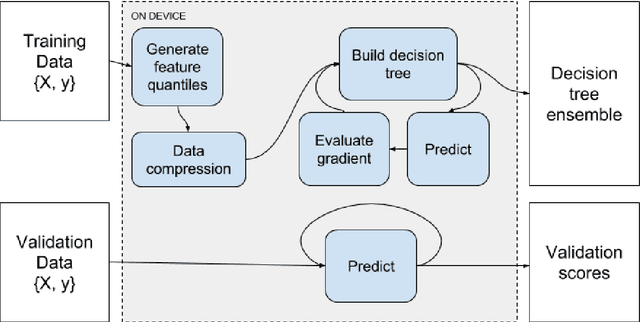
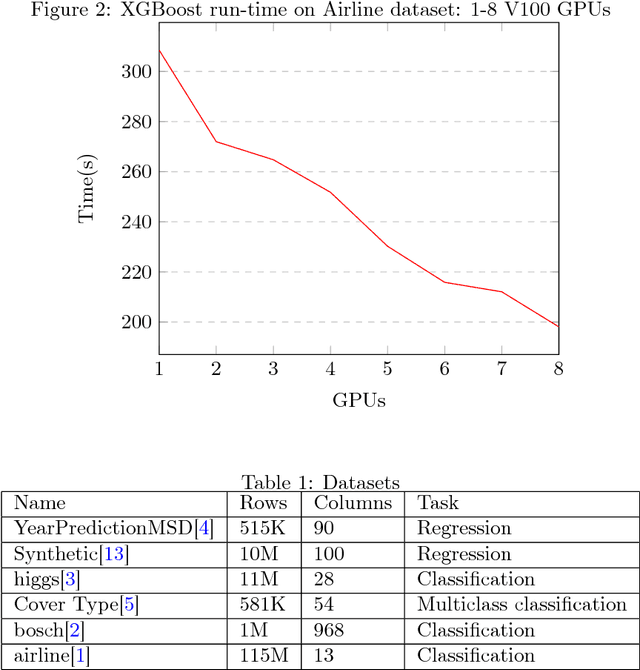
We describe the multi-GPU gradient boosting algorithm implemented in the XGBoost library (https://github.com/dmlc/xgboost). Our algorithm allows fast, scalable training on multi-GPU systems with all of the features of the XGBoost library. We employ data compression techniques to minimise the usage of scarce GPU memory while still allowing highly efficient implementation. Using our algorithm we show that it is possible to process 115 million training instances in under three minutes on a publicly available cloud computing instance. The algorithm is implemented using end-to-end GPU parallelism, with prediction, gradient calculation, feature quantisation, decision tree construction and evaluation phases all computed on device.