 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Estimation and Variance Reduction in Stochastic and Deterministic Models
May 14, 2024



It seems that in the current age, computers, computation, and data have an increasingly important role to play in scientific research and discovery. This is reflected in part by the rise of machine learning and artificial intelligence, which have become great areas of interest not just for computer science but also for many other fields of study. More generally, there have been trends moving towards the use of bigger, more complex and higher capacity models. It also seems that stochastic models, and stochastic variants of existing deterministic models, have become important research directions in various fields. For all of these types of models, gradient-based optimization remains as the dominant paradigm for model fitting, control, and more. This dissertation considers unconstrained, nonlinear optimization problems, with a focus on the gradient itself, that key quantity which enables the solution of such problems. In chapter 1, we introduce the notion of reverse differentiation, a term which describes the body of techniques which enables the efficient computation of gradients. We cover relevant techniques both in the deterministic and stochastic cases. We present a new framework for calculating the gradient of problems which involve both deterministic and stochastic elements. In chapter 2, we analyze the properties of the gradient estimator, with a focus on those properties which are typically assumed in convergence proofs of optimization algorithms. Chapter 3 gives various examples of applying our new gradient estimator. We further explore the idea of working with piecewise continuous models, that is, models with distinct branches and if statements which define what specific branch to use.
Variance Reduction for Score Functions Using Optimal Baselines
Dec 27, 2022



Many problems involve the use of models which learn probability distributions or incorporate randomness in some way. In such problems, because computing the true expected gradient may be intractable, a gradient estimator is used to update the model parameters. When the model parameters directly affect a probability distribution, the gradient estimator will involve score function terms. This paper studies baselines, a variance reduction technique for score functions. Motivated primarily by reinforcement learning, we derive for the first time an expression for the optimal state-dependent baseline, the baseline which results in a gradient estimator with minimum variance. Although we show that there exist examples where the optimal baseline may be arbitrarily better than a value function baseline, we find that the value function baseline usually performs similarly to an optimal baseline in terms of variance reduction. Moreover, the value function can also be used for bootstrapping estimators of the return, leading to additional variance reduction. Our results give new insight and justification for why value function baselines and the generalized advantage estimator (GAE) work well in practice.
Estimating speech from lip dynamics
Aug 03, 2017


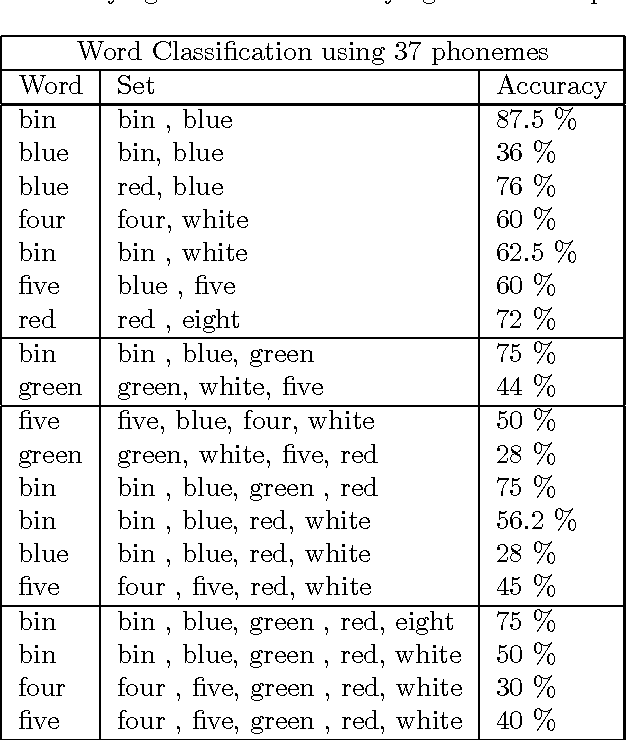
The goal of this project is to develop a limited lip reading algorithm for a subset of the English language. We consider a scenario in which no audio information is available. The raw video is processed and the position of the lips in each frame is extracted. We then prepare the lip data for processing and classify the lips into visemes and phonemes. Hidden Markov Models are used to predict the words the speaker is saying based on the sequences of classified phonemes and visemes. The GRID audiovisual sentence corpus [10][11] database is used for our study.