 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and robust calibration of the Heston option pricing model for American options using an improved Cuckoo Search Algorithm
Jul 31, 2015
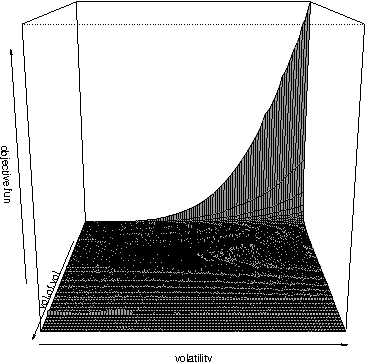

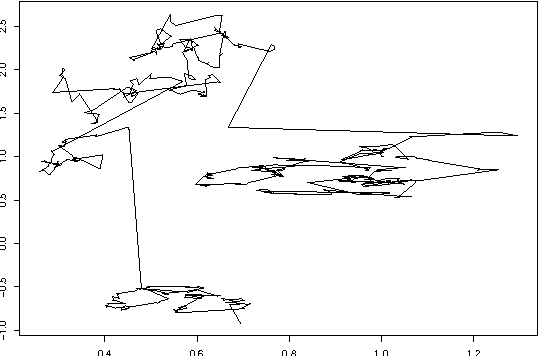
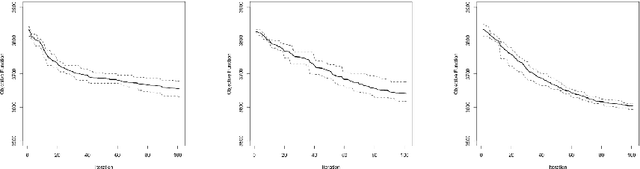
In this paper an improved Cuckoo Search Algorithm is developed to allow for an efficient and robust calibration of the Heston option pricing model for American options. Calibration of stochastic volatility models like the Heston is significantly harder than classical option pricing models as more parameters have to be estimated. The difficult task of calibrating one of these models to American Put options data is the main objective of this paper. Numerical results are shown to substantiate the suitability of the chosen method to tackle this problem.
Computing trading strategies based on financial sentiment data using evolutionary optimization
Apr 12, 2015
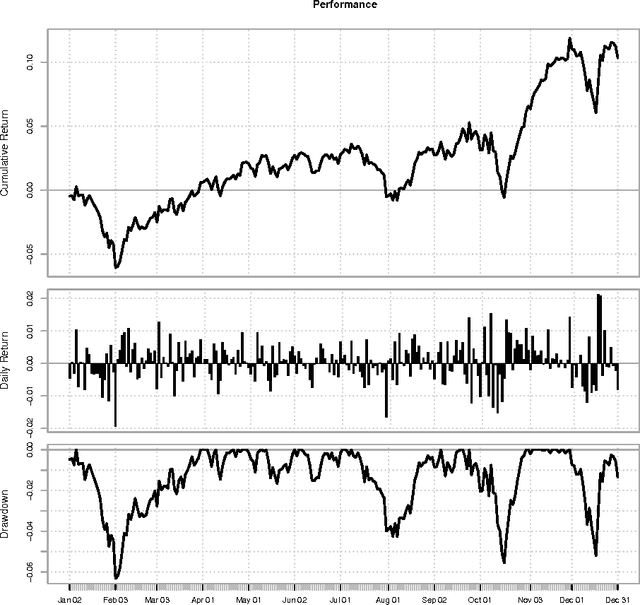

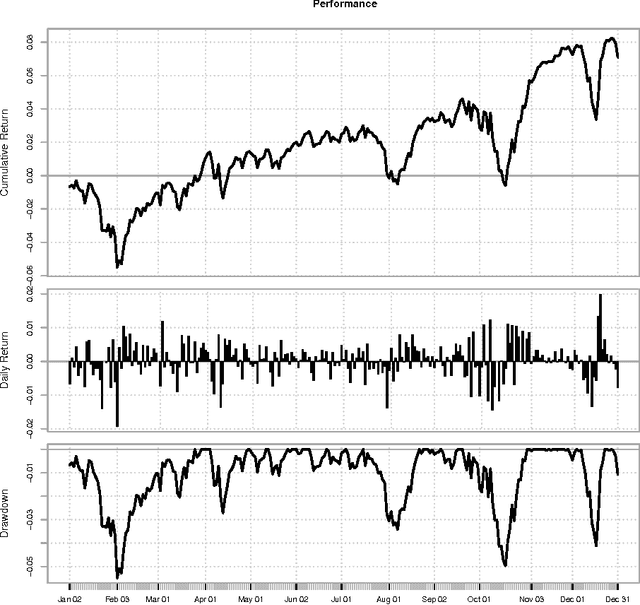
In this paper we apply evolutionary optimization techniques to compute optimal rule-based trading strategies based on financial sentiment data. The sentiment data was extracted from the social media service StockTwits to accommodate the level of bullishness or bearishness of the online trading community towards certain stocks. Numerical results for all stocks from the Dow Jones Industrial Average (DJIA) index are presented and a comparison to classical risk-return portfolio selection is provided.
An Evolutionary Optimization Approach to Risk Parity Portfolio Selection
Jan 19, 2015
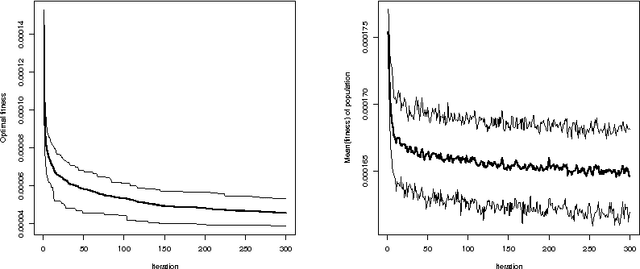
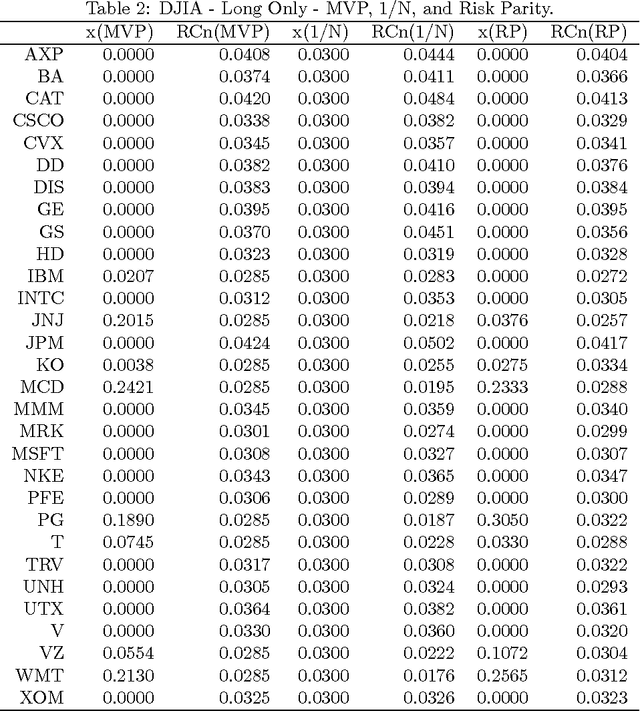
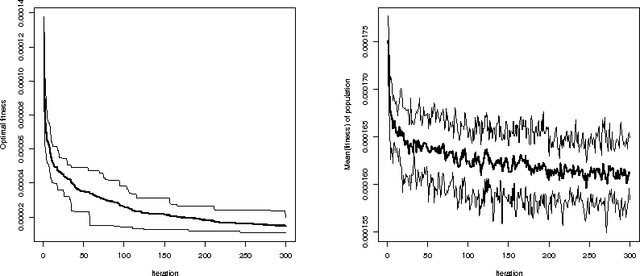
In this paper we present an evolutionary optimization approach to solve the risk parity portfolio selection problem. While there exist convex optimization approaches to solve this problem when long-only portfolios are considered, the optimization problem becomes non-trivial in the long-short case. To solve this problem, we propose a genetic algorithm as well as a local search heuristic. This algorithmic framework is able to compute solutions successfully. Numerical results using real-world data substantiate the practicability of the approach presented in this paper.
The Role of Emotions in Propagating Brands in Social Networks
Sep 16, 2014
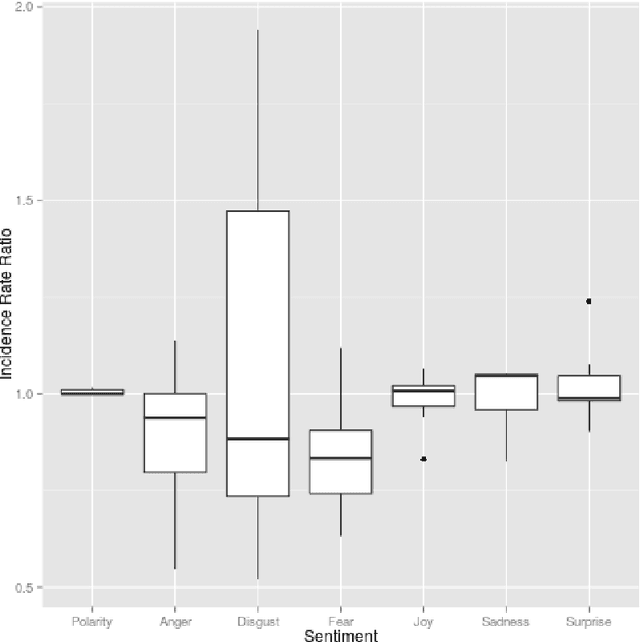
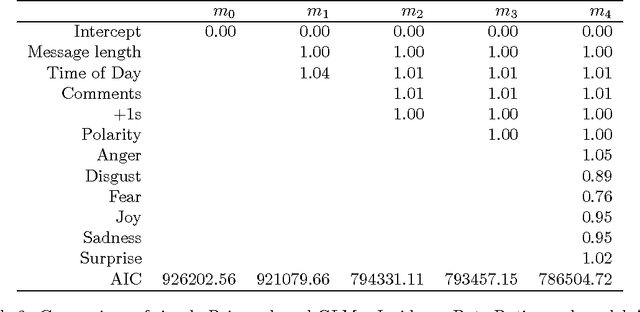
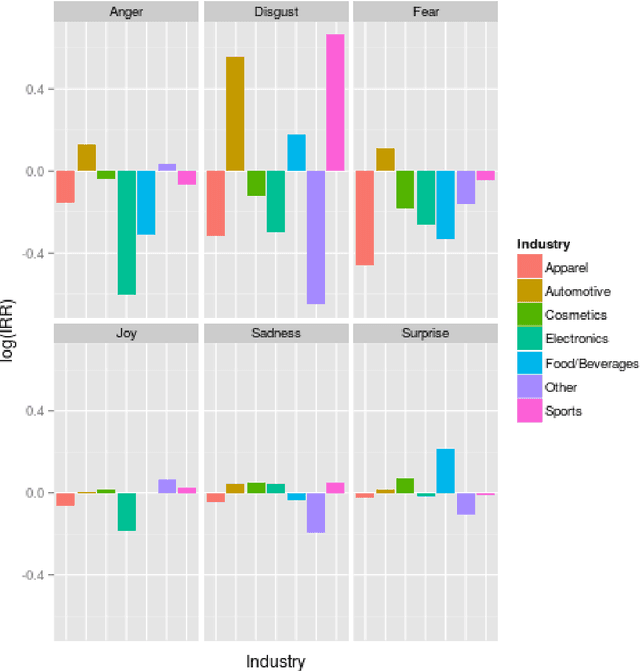
A key aspect of word of mouth marketing are emotions. Emotions in texts help propagating messages in conventional advertising. In word of mouth scenarios, emotions help to engage consumers and incite to propagate the message further. While the function of emotions in offline marketing in general and word of mouth marketing in particular is rather well understood, online marketing can only offer a limited view on the function of emotions. In this contribution we seek to close this gap. We therefore investigate how emotions function in social media. To do so, we collected more than 30,000 brand marketing messages from the Google+ social networking site. Using state of the art computational linguistics classifiers, we compute the sentiment of these messages. Starting out with Poisson regression-based baseline models, we seek to replicate earlier findings using this large data set. We extend upon earlier research by computing multi-level mixed effects models that compare the function of emotions across different industries. We find that while the well known notion of activating emotions propagating messages holds in general for our data as well. But there are significant differences between the observed industries.
Effects of Sampling Methods on Prediction Quality. The Case of Classifying Land Cover Using Decision Trees
May 13, 2014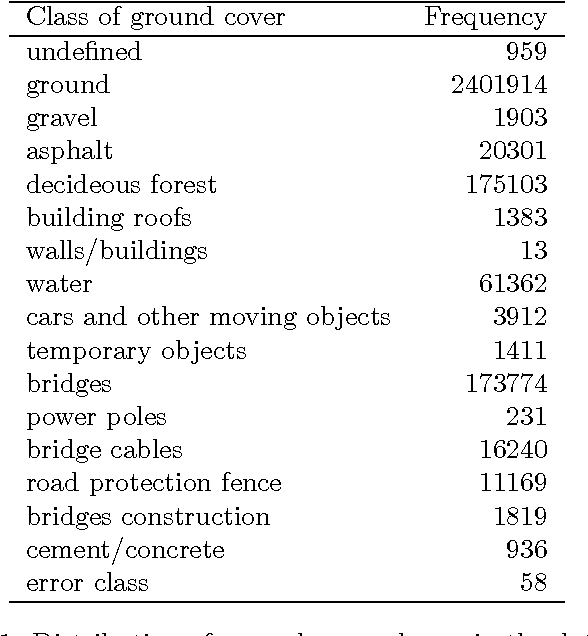
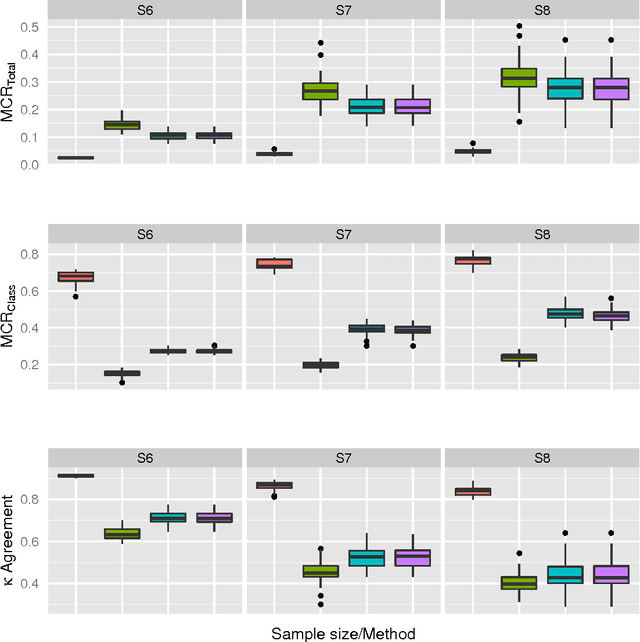
Clever sampling methods can be used to improve the handling of big data and increase its usefulness. The subject of this study is remote sensing, specifically airborne laser scanning point clouds representing different classes of ground cover. The aim is to derive a supervised learning model for the classification using CARTs. In order to measure the effect of different sampling methods on the classification accuracy, various experiments with varying types of sampling methods, sample sizes, and accuracy metrics have been designed. Numerical results for a subset of a large surveying project covering the lower Rhine area in Germany are shown. General conclusions regarding sampling design are drawn and presented.
Modeling multi-stage decision optimization problems
Apr 23, 2014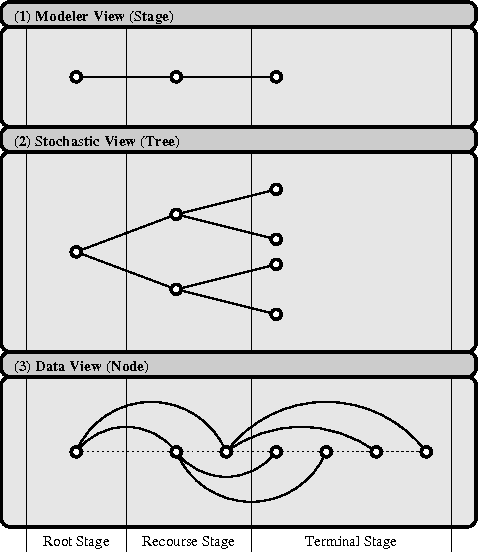
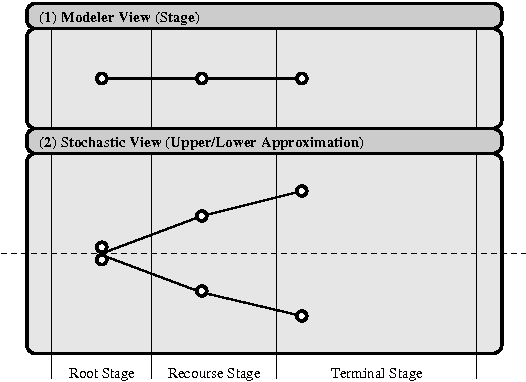
Multi-stage optimization under uncertainty techniques can be used to solve long-term management problems. Although many optimization modeling language extensions as well as computational environments have been proposed, the acceptance of this technique is generally low, due to the inherent complexity of the modeling and solution process. In this paper a simplification to annotate multi-stage decision problems under uncertainty is presented - this simplification contrasts with the common approach to create an extension on top of an existing optimization modeling language. This leads to the definition of meta models, which can be instanced in various programming languages. An example using the statistical computing language R is shown.
Automated Classification of Airborne Laser Scanning Point Clouds
Apr 16, 2014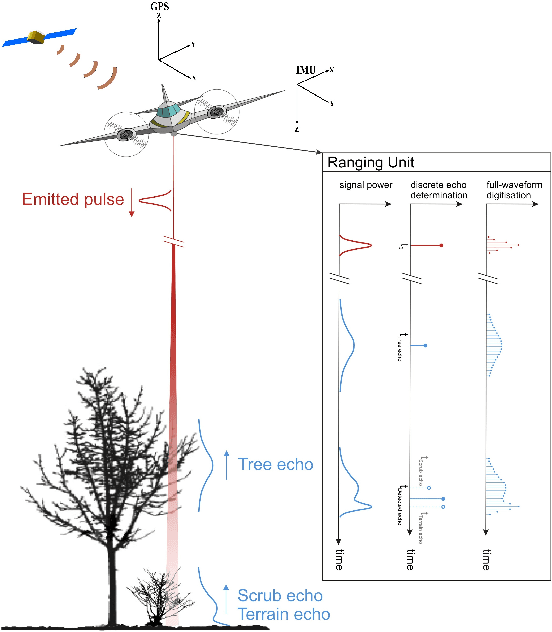
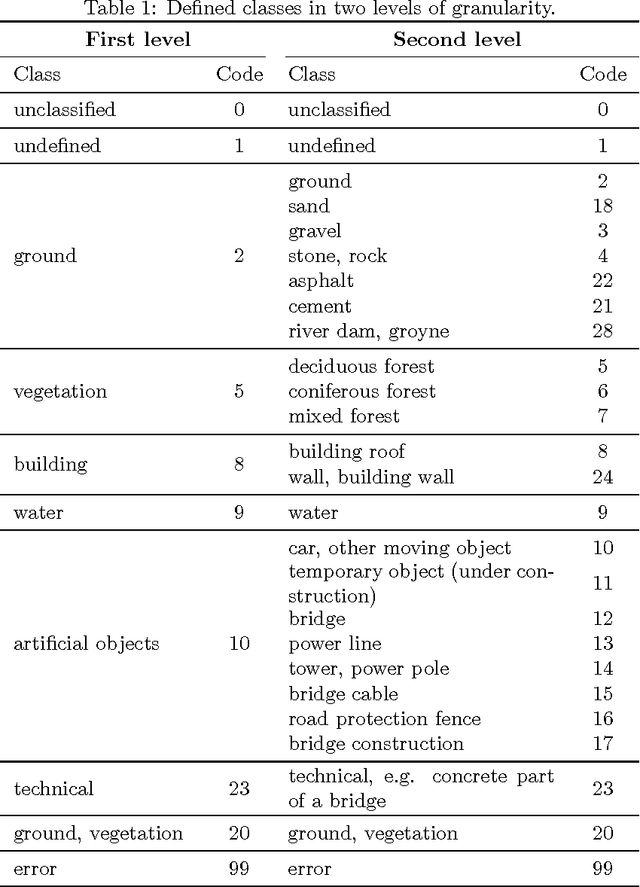
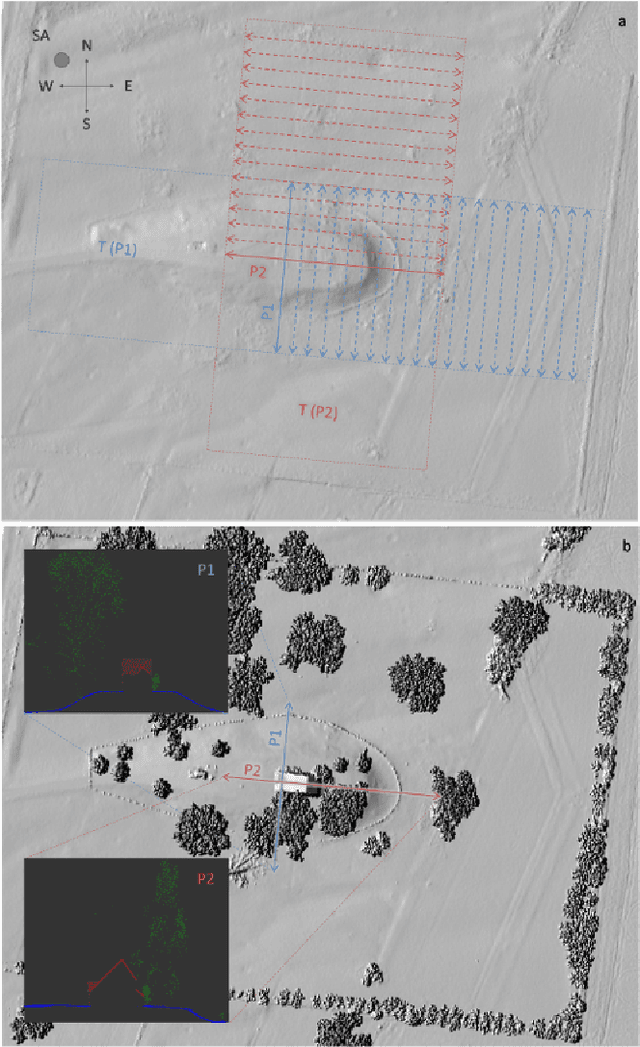
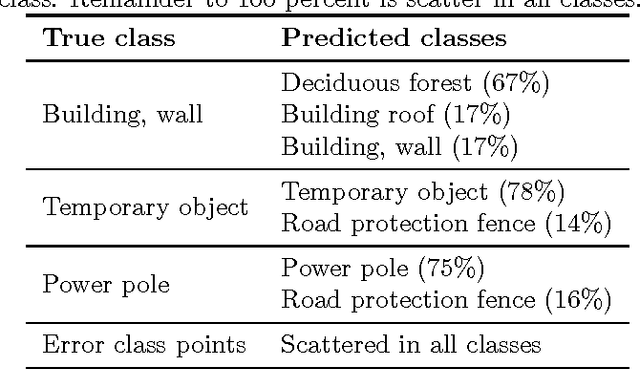
Making sense of the physical world has always been at the core of mapping. Up until recently, this has always dependent on using the human eye. Using airborne lasers, it has become possible to quickly "see" more of the world in many more dimensions. The resulting enormous point clouds serve as data sources for applications far beyond the original mapping purposes ranging from flooding protection and forestry to threat mitigation. In order to process these large quantities of data, novel methods are required. In this contribution, we develop models to automatically classify ground cover and soil types. Using the logic of machine learning, we critically review the advantages of supervised and unsupervised methods. Focusing on decision trees, we improve accuracy by including beam vector components and using a genetic algorithm. We find that our approach delivers consistently high quality classifications, surpassing classical methods.
A Genetic Algorithm to Optimize a Tweet for Retweetability
Jan 20, 2014
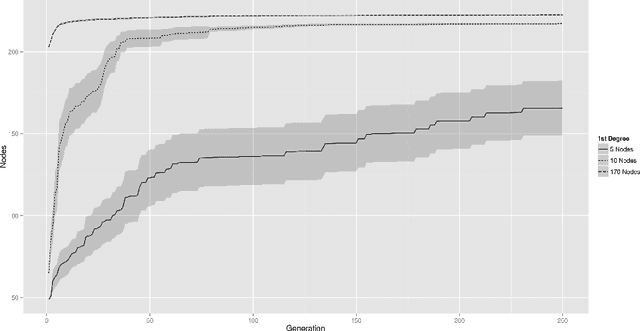
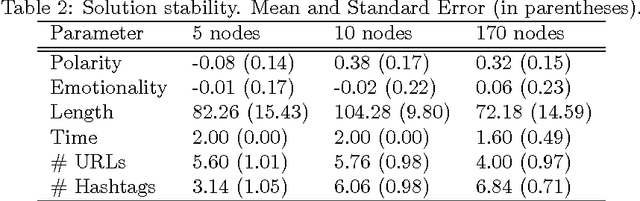
Twitter is a popular microblogging platform. When users send out messages, other users have the ability to forward these messages to their own subgraph. Most research focuses on increasing retweetability from a node's perspective. Here, we center on improving message style to increase the chance of a message being forwarded. To this end, we simulate an artificial Twitter-like network with nodes deciding deterministically on retweeting a message or not. A genetic algorithm is used to optimize message composition, so that the reach of a message is increased. When analyzing the algorithm's runtime behavior across a set of different node types, we find that the algorithm consistently succeeds in significantly improving the retweetability of a message.
An Evolutionary Approach towards Clustering Airborne Laser Scanning Data
Jan 20, 2014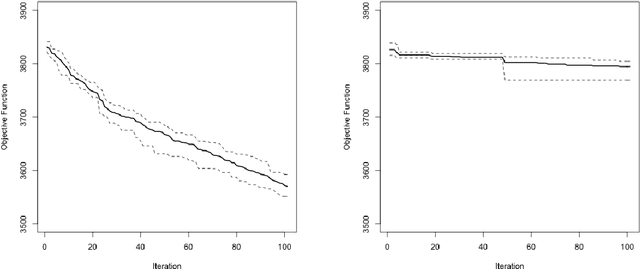
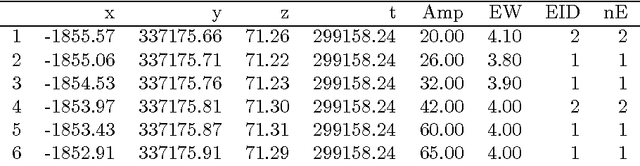

In land surveying, the generation of maps was greatly simplified with the introduction of orthophotos and at a later stage with airborne LiDAR laser scanning systems. While the original purpose of LiDAR systems was to determine the altitude of ground elevations, newer full wave systems provide additional information that can be used on classifying the type of ground cover and the generation of maps. The LiDAR resulting point clouds are huge, multidimensional data sets that need to be grouped in classes of ground cover. We propose a genetic algorithm that aids in classifying these data sets and thus make them usable for map generation. A key feature are tailor-made genetic operators and fitness functions for the subject. The algorithm is compared to a traditional k-means clustering.
Revolutionary Algorithms
Jan 19, 2014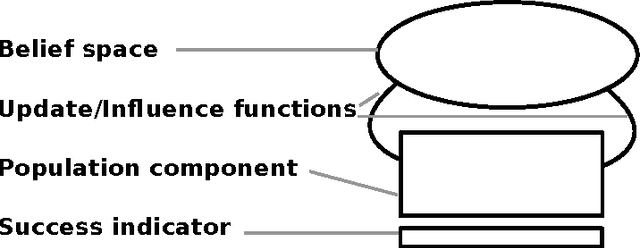
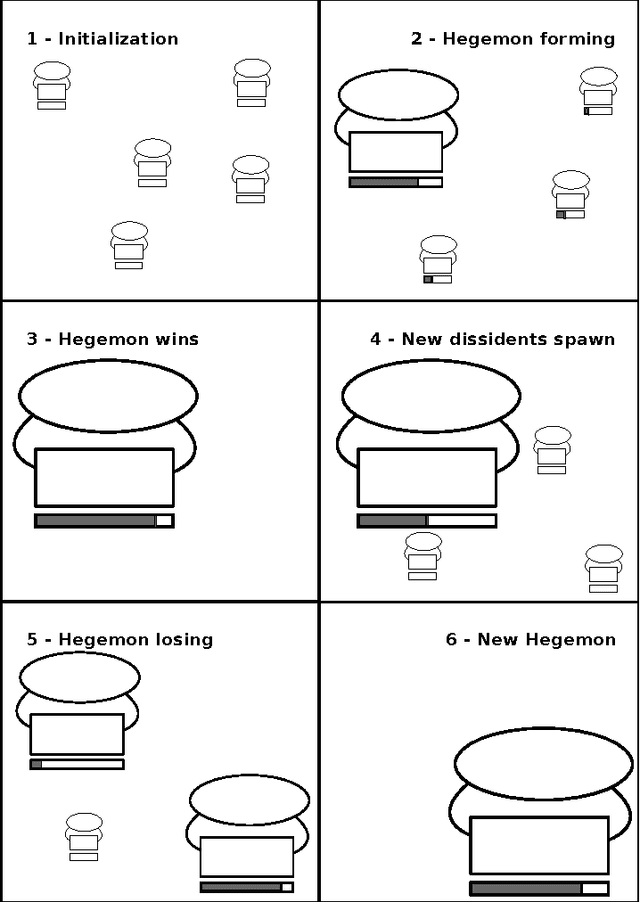
The optimization of dynamic problems is both widespread and difficult. When conducting dynamic optimization, a balance between reinitialization and computational expense has to be found. There are multiple approaches to this. In parallel genetic algorithms, multiple sub-populations concurrently try to optimize a potentially dynamic problem. But as the number of sub-population increases, their efficiency decreases. Cultural algorithms provide a framework that has the potential to make optimizations more efficient. But they adapt slowly to changing environments. We thus suggest a confluence of these approaches: revolutionary algorithms. These algorithms seek to extend the evolutionary and cultural aspects of the former to approaches with a notion of the political. By modeling how belief systems are changed by means of revolution, these algorithms provide a framework to model and optimize dynamic problems in an efficient fashion.