 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Unlearning via Depth-Aware Removal of Forget-Specific Directions
Apr 16, 2026Machine unlearning aims to remove targeted knowledge from a trained model without the cost of retraining from scratch. In class unlearning, however, reducing accuracy on forget classes does not necessarily imply true forgetting: forgotten information can remain encoded in internal representations, and apparent forgetting may arise from classifier-head suppression rather than representational removal. We show that existing class-unlearning methods often exhibit weak or negative selectivity, preserve forget-class structure in deep representations, or rely heavily on final-layer bias shifts. We then introduce DAMP (Depth-Aware Modulation by Projection), a one-shot, closed-form weight-surgery method that removes forget-specific directions from a pretrained network without gradient-based optimization. At each stage, DAMP computes class prototypes in the input space of the next learnable operator, extracts forget directions as residuals relative to retain-class prototypes, and applies a projection-based update to reduce downstream sensitivity to those directions. To preserve utility, DAMP uses a parameter-free depth-aware scaling rule derived from probe separability, applying smaller edits in early layers and larger edits in deeper layers. The method naturally extends to multi-class forgetting through low-rank subspace removal. Across MNIST, CIFAR-10, CIFAR-100, and Tiny ImageNet, and across convolutional and transformer architectures, DAMP more closely resembles the retraining gold standard than some of the prior methods, improving selective forgetting while better preserving retain-class performance and reducing residual forget-class structure in deep layers.
MedMambaLite: Hardware-Aware Mamba for Medical Image Classification
Aug 07, 2025AI-powered medical devices have driven the need for real-time, on-device inference such as biomedical image classification. Deployment of deep learning models at the edge is now used for applications such as anomaly detection and classification in medical images. However, achieving this level of performance on edge devices remains challenging due to limitations in model size and computational capacity. To address this, we present MedMambaLite, a hardware-aware Mamba-based model optimized through knowledge distillation for medical image classification. We start with a powerful MedMamba model, integrating a Mamba structure for efficient feature extraction in medical imaging. We make the model lighter and faster in training and inference by modifying and reducing the redundancies in the architecture. We then distill its knowledge into a smaller student model by reducing the embedding dimensions. The optimized model achieves 94.5% overall accuracy on 10 MedMNIST datasets. It also reduces parameters 22.8x compared to MedMamba. Deployment on an NVIDIA Jetson Orin Nano achieves 35.6 GOPS/J energy per inference. This outperforms MedMamba by 63% improvement in energy per inference.
MambaLiteSR: Image Super-Resolution with Low-Rank Mamba using Knowledge Distillation
Feb 19, 2025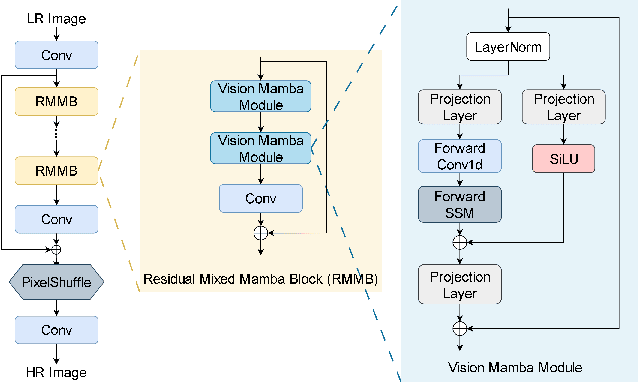
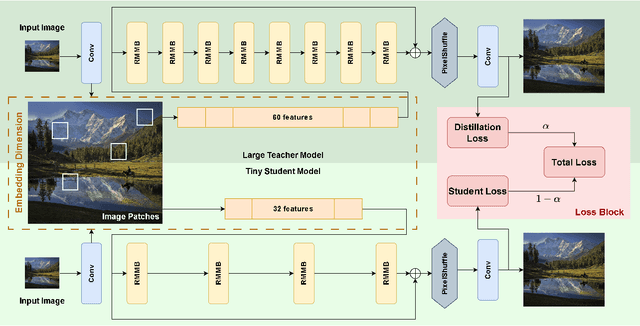
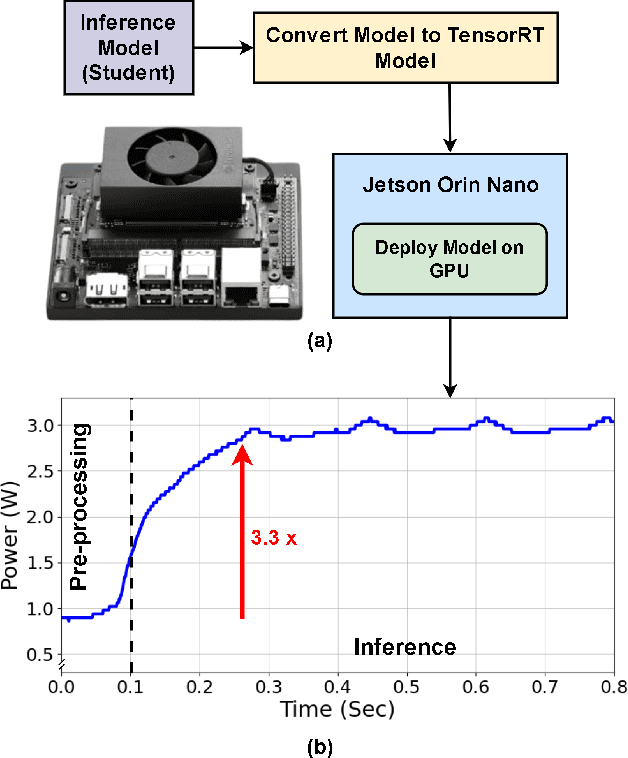
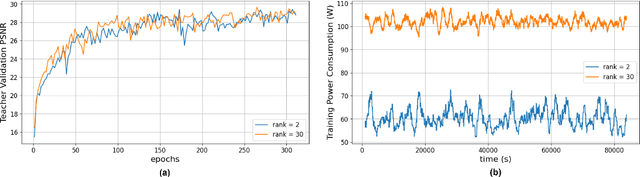
Generative Artificial Intelligence (AI) has gained significant attention in recent years, revolutionizing various applications across industries. Among these, advanced vision models for image super-resolution are in high demand, particularly for deployment on edge devices where real-time processing is crucial. However, deploying such models on edge devices is challenging due to limited computing power and memory. In this paper, we present MambaLiteSR, a novel lightweight image Super-Resolution (SR) model that utilizes the architecture of Vision Mamba. It integrates State Space Blocks and a reconstruction module for efficient feature extraction. To optimize efficiency without affecting performance, MambaLiteSR employs knowledge distillation to transfer key insights from a larger Mamba-based teacher model to a smaller student model via hyperparameter tuning. Through mathematical analysis of model parameters and their impact on PSNR, we identify key factors and adjust them accordingly. Our comprehensive evaluation shows that MambaLiteSR outperforms state-of-the-art edge SR methods by reducing power consumption while maintaining competitive PSNR and SSIM scores across benchmark datasets. It also reduces power usage during training via low-rank approximation. Moreover, MambaLiteSR reduces parameters with minimal performance loss, enabling efficient deployment of generative AI models on resource-constrained devices. Deployment on the embedded NVIDIA Jetson Orin Nano confirms the superior balance of MambaLiteSR size, latency, and efficiency. Experiments show that MambaLiteSR achieves performance comparable to both the baseline and other edge models while using 15% fewer parameters. It also improves power consumption by up to 58% compared to state-of-the-art SR edge models, all while maintaining low energy use during training.