 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriTopic: Tri-Modal Graph-Based Topic Modeling with Iterative Refinement and Archetypes
Feb 22, 2026Topic modeling extracts latent themes from large text collections, but leading approaches like BERTopic face critical limitations: stochastic instability, loss of lexical precision ("Embedding Blur"), and reliance on a single data perspective. We present TriTopic, a framework that addresses these weaknesses through a tri-modal graph fusing semantic embeddings, TF-IDF, and metadata. Three core innovations drive its performance: hybrid graph construction via Mutual kNN and Shared Nearest Neighbors to eliminate noise and combat the curse of dimensionality; Consensus Leiden Clustering for reproducible, stable partitions; and Iterative Refinement that sharpens embeddings through dynamic centroid-pulling. TriTopic also replaces the "average document" concept with archetype-based topic representations defined by boundary cases rather than centers alone. In benchmarks across 20 Newsgroups, BBC News, AG News, and Arxiv, TriTopic achieves the highest NMI on every dataset (mean NMI 0.575 vs. 0.513 for BERTopic, 0.416 for NMF, 0.299 for LDA), guarantees 100% corpus coverage with 0% outliers, and is available as an open-source PyPI library.
TourBERT: A pretrained language model for the tourism industry
Jan 19, 2022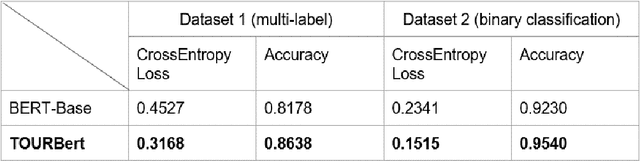



The Bidirectional Encoder Representations from Transformers (BERT) is currently one of the most important and state-of-the-art models for natural language. However, it has also been shown that for domain-specific tasks it is helpful to pretrain BERT on a domain-specific corpus. In this paper, we present TourBERT, a pretrained language model for tourism. We describe how TourBERT was developed and evaluated. The evaluations show that TourBERT is outperforming BERT in all tourism-specific tasks.