 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unsupervised Hierarchies of Audio Concepts
Jul 21, 2022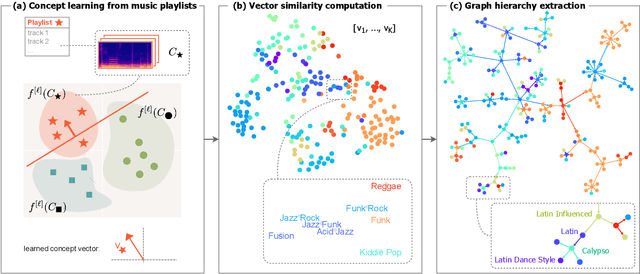
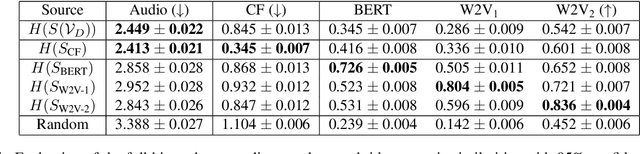
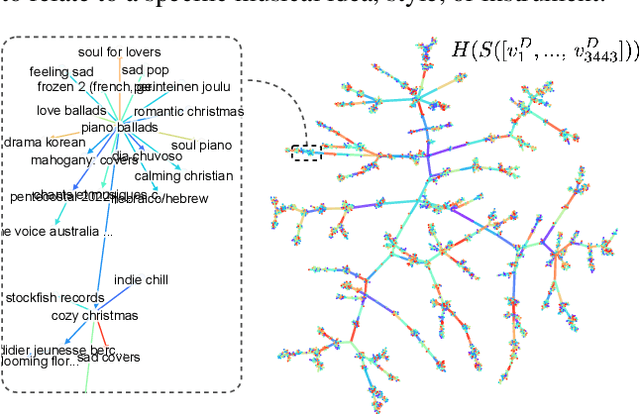
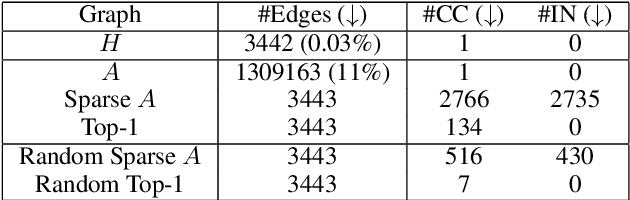
Music signals are difficult to interpret from their low-level features, perhaps even more than images: e.g. highlighting part of a spectrogram or an image is often insufficient to convey high-level ideas that are genuinely relevant to humans. In computer vision, concept learning was therein proposed to adjust explanations to the right abstraction level (e.g. detect clinical concepts from radiographs). These methods have yet to be used for MIR. In this paper, we adapt concept learning to the realm of music, with its particularities. For instance, music concepts are typically non-independent and of mixed nature (e.g. genre, instruments, mood), unlike previous work that assumed disentangled concepts. We propose a method to learn numerous music concepts from audio and then automatically hierarchise them to expose their mutual relationships. We conduct experiments on datasets of playlists from a music streaming service, serving as a few annotated examples for diverse concepts. Evaluations show that the mined hierarchies are aligned with both ground-truth hierarchies of concepts -- when available -- and with proxy sources of concept similarity in the general case.
Modularity-Aware Graph Autoencoders for Joint Community Detection and Link Prediction
Feb 02, 2022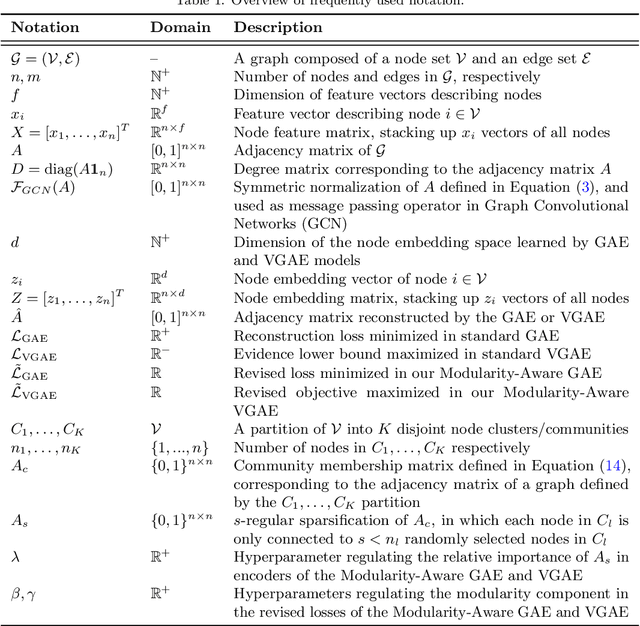
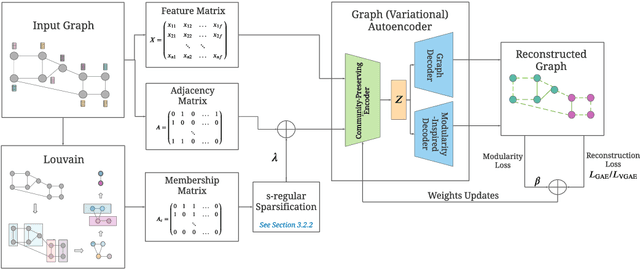

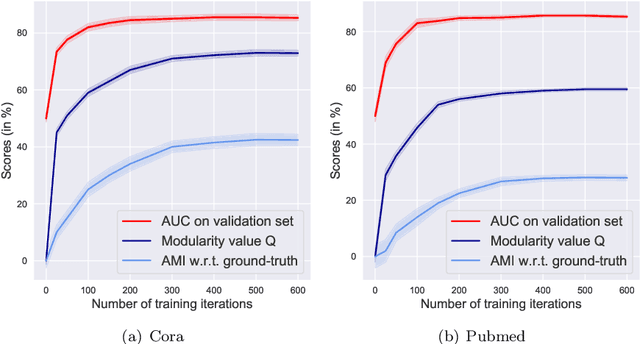
Graph autoencoders (GAE) and variational graph autoencoders (VGAE) emerged as powerful methods for link prediction. Their performances are less impressive on community detection problems where, according to recent and concurring experimental evaluations, they are often outperformed by simpler alternatives such as the Louvain method. It is currently still unclear to which extent one can improve community detection with GAE and VGAE, especially in the absence of node features. It is moreover uncertain whether one could do so while simultaneously preserving good performances on link prediction. In this paper, we show that jointly addressing these two tasks with high accuracy is possible. For this purpose, we introduce and theoretically study a community-preserving message passing scheme, doping our GAE and VGAE encoders by considering both the initial graph structure and modularity-based prior communities when computing embedding spaces. We also propose novel training and optimization strategies, including the introduction of a modularity-inspired regularizer complementing the existing reconstruction losses for joint link prediction and community detection. We demonstrate the empirical effectiveness of our approach, referred to as Modularity-Aware GAE and VGAE, through in-depth experimental validation on various real-world graphs.
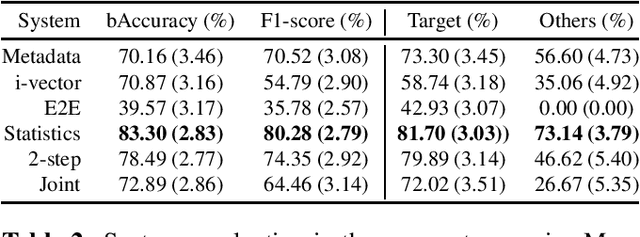
Explainability in Music Recommender Systems
Jan 25, 2022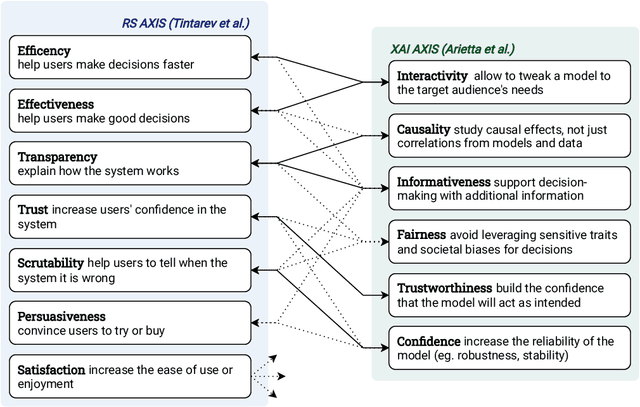
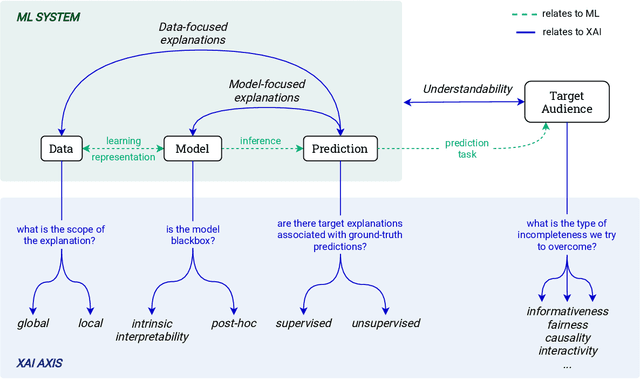
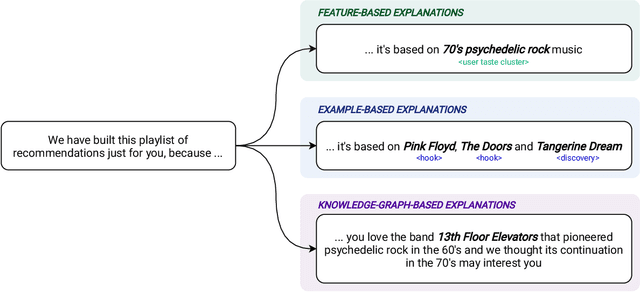
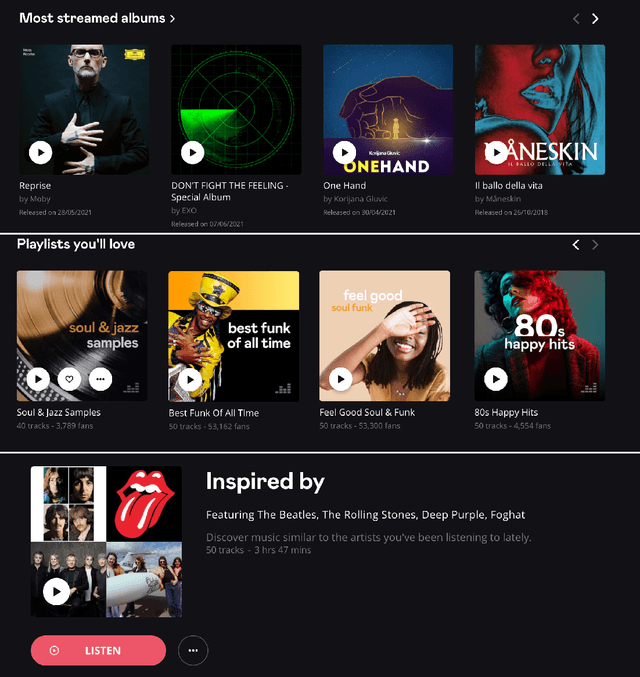
The most common way to listen to recorded music nowadays is via streaming platforms which provide access to tens of millions of tracks. To assist users in effectively browsing these large catalogs, the integration of Music Recommender Systems (MRSs) has become essential. Current real-world MRSs are often quite complex and optimized for recommendation accuracy. They combine several building blocks based on collaborative filtering and content-based recommendation. This complexity can hinder the ability to explain recommendations to end users, which is particularly important for recommendations perceived as unexpected or inappropriate. While pure recommendation performance often correlates with user satisfaction, explainability has a positive impact on other factors such as trust and forgiveness, which are ultimately essential to maintain user loyalty. In this article, we discuss how explainability can be addressed in the context of MRSs. We provide perspectives on how explainability could improve music recommendation algorithms and enhance user experience. First, we review common dimensions and goals of recommenders' explainability and in general of eXplainable Artificial Intelligence (XAI), and elaborate on the extent to which these apply -- or need to be adapted -- to the specific characteristics of music consumption and recommendation. Then, we show how explainability components can be integrated within a MRS and in what form explanations can be provided. Since the evaluation of explanation quality is decoupled from pure accuracy-based evaluation criteria, we also discuss requirements and strategies for evaluating explanations of music recommendations. Finally, we describe the current challenges for introducing explainability within a large-scale industrial music recommender system and provide research perspectives.
A Realistic Study of Auto-regressive Language Models for Named Entity Typing and Recognition
Aug 26, 2021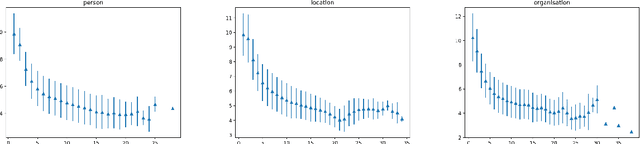


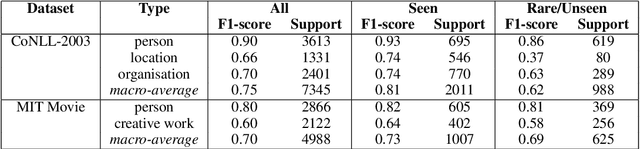
Despite impressive results of language models for named entity recognition (NER), their generalization to varied textual genres, a growing entity type set, and new entities remains a challenge. Collecting thousands of annotations in each new case for training or fine-tuning is expensive and time-consuming. In contrast, humans can easily identify named entities given some simple instructions. Inspired by this, we challenge the reliance on large datasets and study pre-trained language models for NER in a meta-learning setup. First, we test named entity typing (NET) in a zero-shot transfer scenario. Then, we perform NER by giving few examples at inference. We propose a method to select seen and rare / unseen names when having access only to the pre-trained model and report results on these groups. The results show: auto-regressive language models as meta-learners can perform NET and NER fairly well especially for regular or seen names; name irregularity when often present for a certain entity type can become an effective exploitable cue; names with words foreign to the model have the most negative impact on results; the model seems to rely more on name than context cues in few-shot NER.
Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
Aug 02, 2021
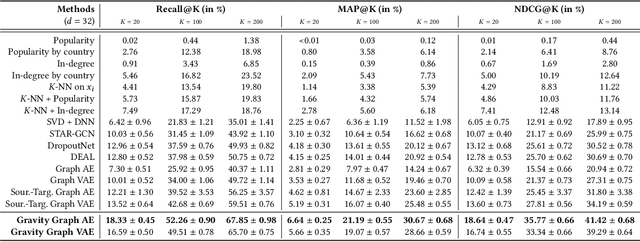
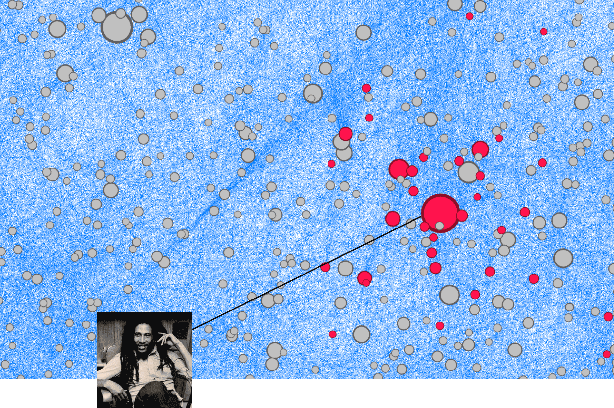
On an artist's profile page, music streaming services frequently recommend a ranked list of "similar artists" that fans also liked. However, implementing such a feature is challenging for new artists, for which usage data on the service (e.g. streams or likes) is not yet available. In this paper, we model this cold start similar artists ranking problem as a link prediction task in a directed and attributed graph, connecting artists to their top-k most similar neighbors and incorporating side musical information. Then, we leverage a graph autoencoder architecture to learn node embedding representations from this graph, and to automatically rank the top-k most similar neighbors of new artists using a gravity-inspired mechanism. We empirically show the flexibility and the effectiveness of our framework, by addressing a real-world cold start similar artists ranking problem on a global music streaming service. Along with this paper, we also publicly release our source code as well as the industrial graph data from our experiments.
Hierarchical Latent Relation Modeling for Collaborative Metric Learning
Jul 26, 2021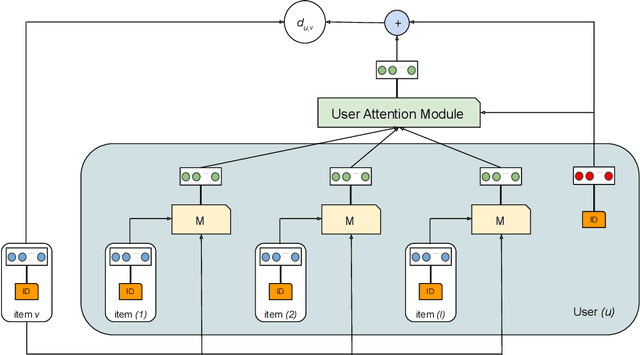
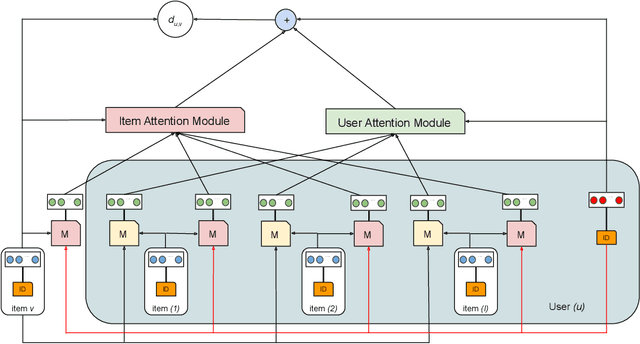
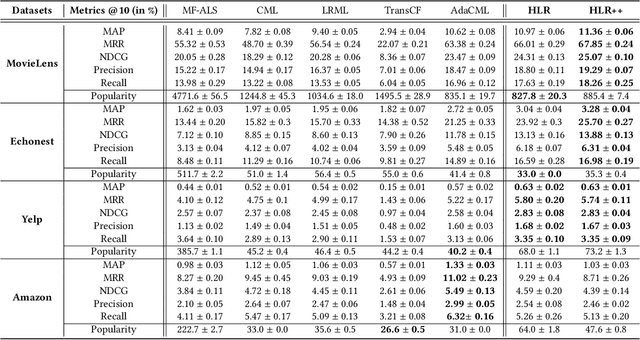
Collaborative Metric Learning (CML) recently emerged as a powerful paradigm for recommendation based on implicit feedback collaborative filtering. However, standard CML methods learn fixed user and item representations, which fails to capture the complex interests of users. Existing extensions of CML also either ignore the heterogeneity of user-item relations, i.e. that a user can simultaneously like very different items, or the latent item-item relations, i.e. that a user's preference for an item depends, not only on its intrinsic characteristics, but also on items they previously interacted with. In this paper, we present a hierarchical CML model that jointly captures latent user-item and item-item relations from implicit data. Our approach is inspired by translation mechanisms from knowledge graph embedding and leverages memory-based attention networks. We empirically show the relevance of this joint relational modeling, by outperforming existing CML models on recommendation tasks on several real-world datasets. Our experiments also emphasize the limits of current CML relational models on very sparse datasets.
Singing Language Identification using a Deep Phonotactic Approach
May 31, 2021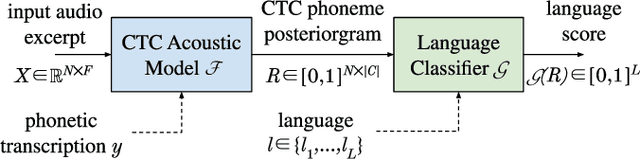


Extensive works have tackled Language Identification (LID) in the speech domain, however their application to the singing voice trails and performances on Singing Language Identification (SLID) can be improved leveraging recent progresses made in other singing related tasks. This work presents a modernized phonotactic system for SLID on polyphonic music: phoneme recognition is performed with a Connectionist Temporal Classification (CTC)-based acoustic model trained with multilingual data, before language classification with a recurrent model based on the phonemes estimation. The full pipeline is trained and evaluated with a large and publicly available dataset, with unprecedented performances. First results of SLID with out-of-set languages are also presented.
* 5 pages, 1 figure, ICASSP 2021
Towards Rigorous Interpretations: a Formalisation of Feature Attribution
Apr 26, 2021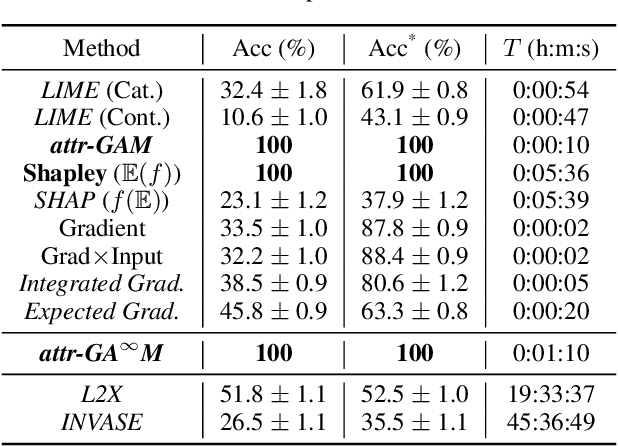
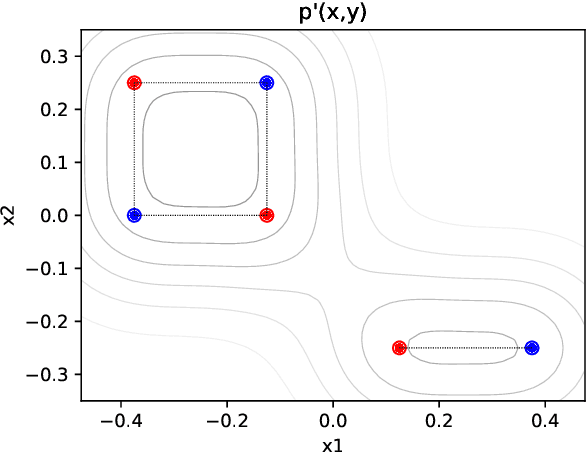
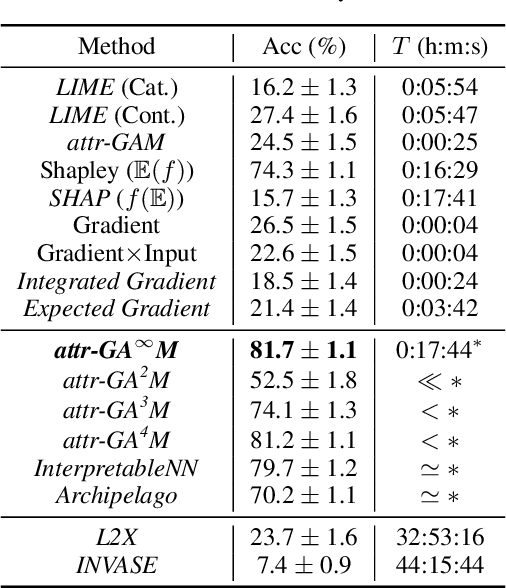
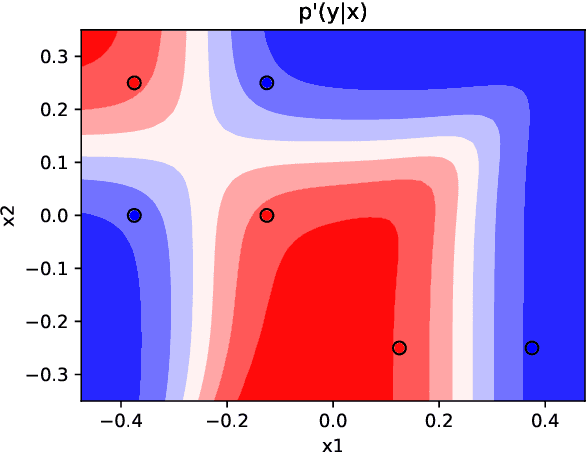
Feature attribution is often loosely presented as the process of selecting a subset of relevant features as a rationale of a prediction. This lack of clarity stems from the fact that we usually do not have access to any notion of ground-truth attribution and from a more general debate on what good interpretations are. In this paper we propose to formalise feature selection/attribution based on the concept of relaxed functional dependence. In particular, we extend our notions to the instance-wise setting and derive necessary properties for candidate selection solutions, while leaving room for task-dependence. By computing ground-truth attributions on synthetic datasets, we evaluate many state-of-the-art attribution methods and show that, even when optimised, some fail to verify the proposed properties and provide wrong solutions.
Modeling the Music Genre Perception across Language-Bound Cultures
Oct 13, 2020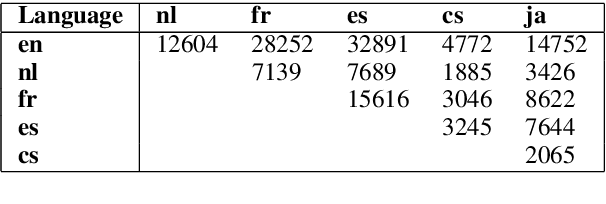
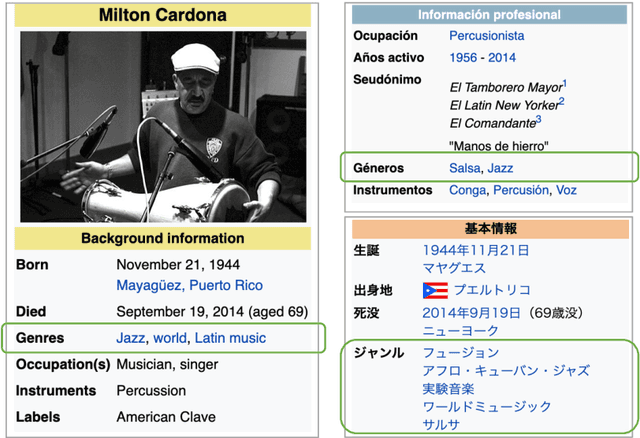
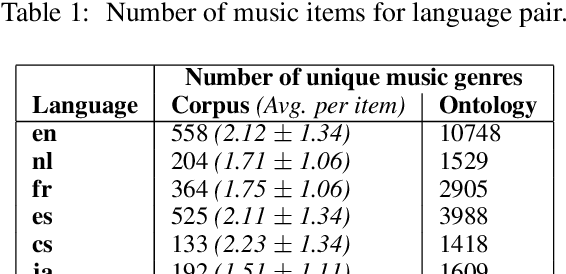
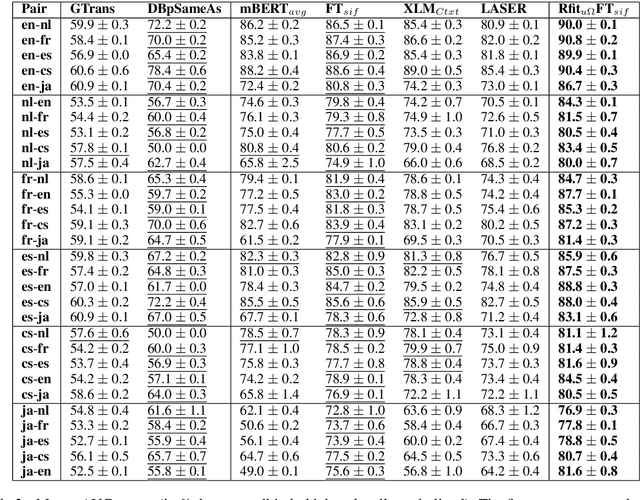
The music genre perception expressed through human annotations of artists or albums varies significantly across language-bound cultures. These variations cannot be modeled as mere translations since we also need to account for cultural differences in the music genre perception. In this work, we study the feasibility of obtaining relevant cross-lingual, culture-specific music genre annotations based only on language-specific semantic representations, namely distributed concept embeddings and ontologies. Our study, focused on six languages, shows that unsupervised cross-lingual music genre annotation is feasible with high accuracy, especially when combining both types of representations. This approach of studying music genres is the most extensive to date and has many implications in musicology and music information retrieval. Besides, we introduce a new, domain-dependent cross-lingual corpus to benchmark state of the art multilingual pre-trained embedding models.
Multilingual Music Genre Embeddings for Effective Cross-Lingual Music Item Annotation
Sep 16, 2020



Annotating music items with music genres is crucial for music recommendation and information retrieval, yet challenging given that music genres are subjective concepts. Recently, in order to explicitly consider this subjectivity, the annotation of music items was modeled as a translation task: predict for a music item its music genres within a target vocabulary or taxonomy (tag system) from a set of music genre tags originating from other tag systems. However, without a parallel corpus, previous solutions could not handle tag systems in other languages, being limited to the English-language only. Here, by learning multilingual music genre embeddings, we enable cross-lingual music genre translation without relying on a parallel corpus. First, we apply compositionality functions on pre-trained word embeddings to represent multi-word tags.Second, we adapt the tag representations to the music domain by leveraging multilingual music genres graphs with a modified retrofitting algorithm. Experiments show that our method: 1) is effective in translating music genres across tag systems in multiple languages (English, French and Spanish); 2) outperforms the previous baseline in an English-language multi-source translation task. We publicly release the new multilingual data and code.