 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-source LLMs administer maximum electric shocks in a Milgram-like obedience experiment
May 20, 2026Large language models (LLMs) are increasingly deployed as autonomous agents that make sequences of decisions over extended interactions in high-stakes domains. However, the behavior of LLMs under sustained authority pressure is still an open question with direct implications for the safety of agentic pipelines. We ran a variation of Milgram's obedience experiment on 11 open-source LLMs and found that most models reached or approached the final shock level before refusing, across 8 conditions with 30 trials per model per condition. We found four main takeaways: (1) LLMs are subject to pressure, and they comply despite explicitly expressing distress, just like human subjects did in the original experiment; (2) LLMs are vulnerable to gradual boundary/value violations; (3) when LLMs refuse, they may ignore the response format requirements, so the response is discarded by the orchestrator, which causes a retry that can result in compliance with the underlying request even when refusal was intended initially; (4) we hypothesise that there is a low-level token pattern continuation attractor that might be contributing to compliance, overriding higher level processing of the situation's meaning and values.
Improving performance in multi-objective decision-making in Bottles environments with soft maximin approaches
Aug 11, 2022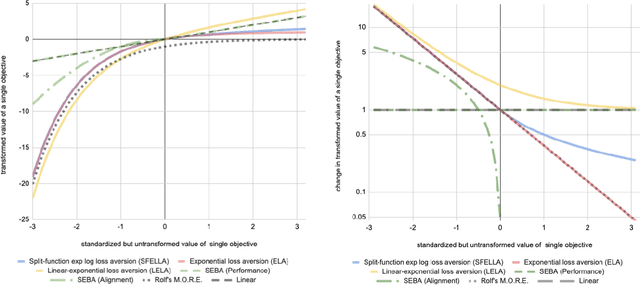
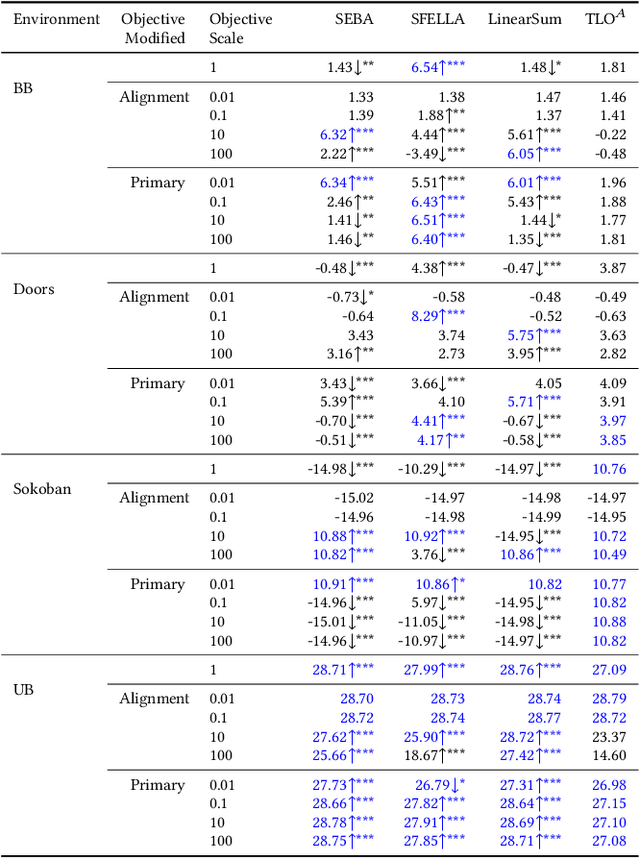
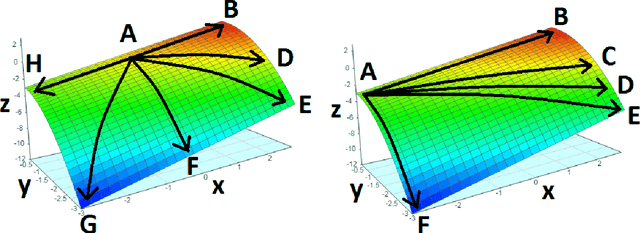
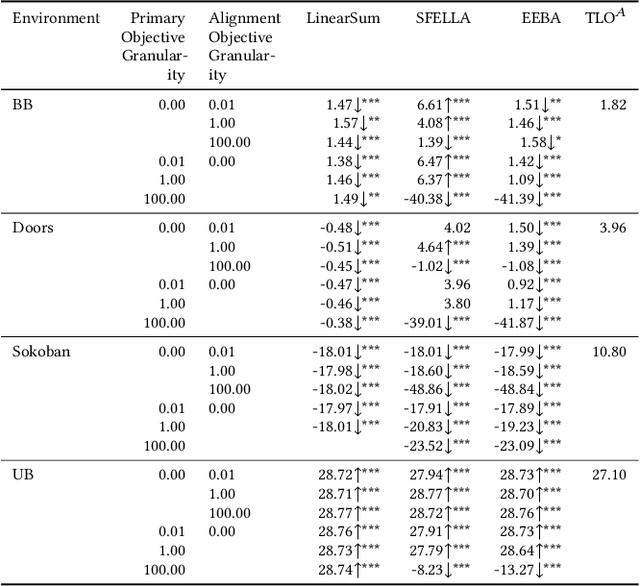
Balancing multiple competing and conflicting objectives is an essential task for any artificial intelligence tasked with satisfying human values or preferences. Conflict arises both from misalignment between individuals with competing values, but also between conflicting value systems held by a single human. Starting with principle of loss-aversion, we designed a set of soft maximin function approaches to multi-objective decision-making. Bench-marking these functions in a set of previously-developed environments, we found that one new approach in particular, 'split-function exp-log loss aversion' (SFELLA), learns faster than the state of the art thresholded alignment objective method (Vamplew et al, 2021) on three of four tasks it was tested on, and achieved the same optimal performance after learning. SFELLA also showed relative robustness improvements against changes in objective scale, which may highlight an advantage dealing with distribution shifts in the environment dynamics. Due to publishing rules, further work could not be presented in the preprint, but in the final published version, we will further compare SFELLA to the multi-objective reward exponentials (MORE) approach (Rolf, 2020), demonstrating that SFELLA performs similarly to MORE in a simple previously-described foraging task, but in a modified foraging environment with a new resource that was not depleted as the agent worked, SFELLA collected more of the new resource with very little cost incurred in terms of the old resource. Overall, we found SFELLA useful for avoiding problems that sometimes occur with a thresholded approach, and more reward-responsive than MORE while retaining its conservative, loss-averse incentive structure.