 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplace, Don't Expand: Mitigating Context Dilution in Multi-Hop RAG via Fixed-Budget Evidence Assembly
Dec 19, 2025



Retrieval-Augmented Generation (RAG) systems often fail on multi-hop queries when the initial retrieval misses a bridge fact. Prior corrective approaches, such as Self-RAG, CRAG, and Adaptive-$k$, typically address this by \textit{adding} more context or pruning existing lists. However, simply expanding the context window often leads to \textbf{context dilution}, where distractors crowd out relevant information. We propose \textbf{SEAL-RAG}, a training-free controller that adopts a \textbf{``replace, don't expand''} strategy to fight context dilution under a fixed retrieval depth $k$. SEAL executes a (\textbf{S}earch $\rightarrow$ \textbf{E}xtract $\rightarrow$ \textbf{A}ssess $\rightarrow$ \textbf{L}oop) cycle: it performs on-the-fly, entity-anchored extraction to build a live \textit{gap specification} (missing entities/relations), triggers targeted micro-queries, and uses \textit{entity-first ranking} to actively swap out distractors for gap-closing evidence. We evaluate SEAL-RAG against faithful re-implementations of Basic RAG, CRAG, Self-RAG, and Adaptive-$k$ in a shared environment on \textbf{HotpotQA} and \textbf{2WikiMultiHopQA}. On HotpotQA ($k=3$), SEAL improves answer correctness by \textbf{+3--13 pp} and evidence precision by \textbf{+12--18 pp} over Self-RAG. On 2WikiMultiHopQA ($k=5$), it outperforms Adaptive-$k$ by \textbf{+8.0 pp} in accuracy and maintains \textbf{96\%} evidence precision compared to 22\% for CRAG. These gains are statistically significant ($p<0.001$). By enforcing fixed-$k$ replacement, SEAL yields a predictable cost profile while ensuring the top-$k$ slots are optimized for precision rather than mere breadth. We release our code and data at https://github.com/mosherino/SEAL-RAG.
Enhancing Neural Spoken Language Recognition: An Exploration with Multilingual Datasets
Jan 19, 2025In this research, we advanced a spoken language recognition system, moving beyond traditional feature vector-based models. Our improvements focused on effectively capturing language characteristics over extended periods using a specialized pooling layer. We utilized a broad dataset range from Common-Voice, targeting ten languages across Indo-European, Semitic, and East Asian families. The major innovation involved optimizing the architecture of Time Delay Neural Networks. We introduced additional layers and restructured these networks into a funnel shape, enhancing their ability to process complex linguistic patterns. A rigorous grid search determined the optimal settings for these networks, significantly boosting their efficiency in language pattern recognition from audio samples. The model underwent extensive training, including a phase with augmented data, to refine its capabilities. The culmination of these efforts is a highly accurate system, achieving a 97\% accuracy rate in language recognition. This advancement represents a notable contribution to artificial intelligence, specifically in improving the accuracy and efficiency of language processing systems, a critical aspect in the engineering of advanced speech recognition technologies.
Whisper Turns Stronger: Augmenting Wav2Vec 2.0 for Superior ASR in Low-Resource Languages
Dec 31, 2024
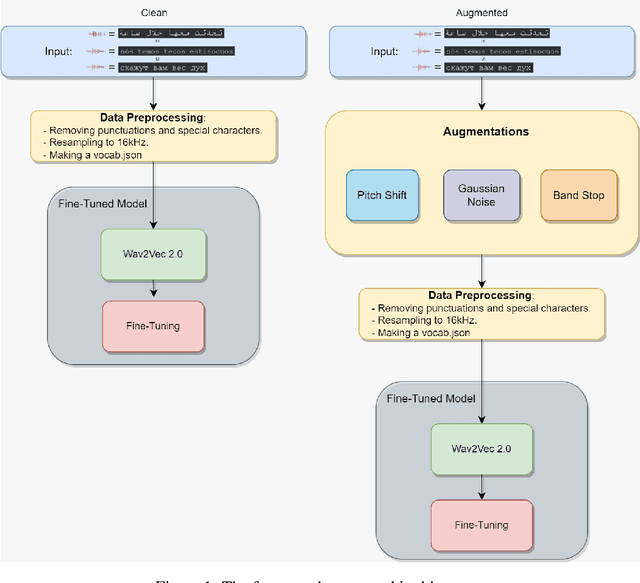
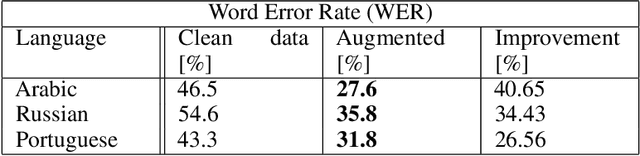
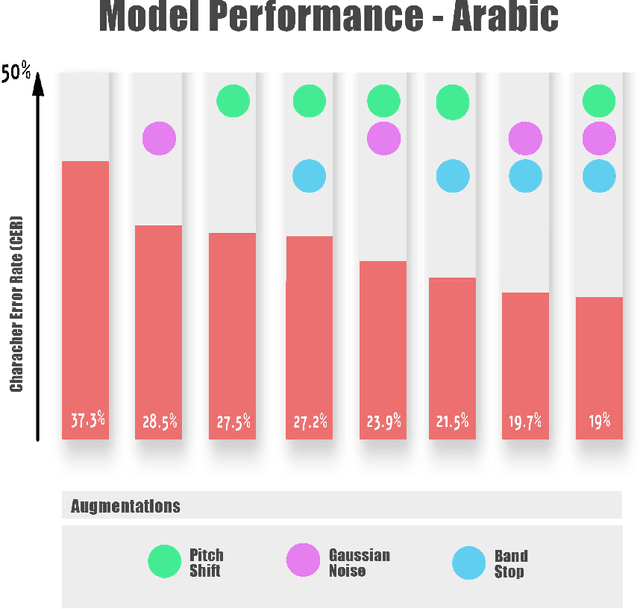
Approaching Speech-to-Text and Automatic Speech Recognition problems in low-resource languages is notoriously challenging due to the scarcity of validated datasets and the diversity of dialects. Arabic, Russian, and Portuguese exemplify these difficulties, being low-resource languages due to the many dialects of these languages across different continents worldwide. Moreover, the variety of accents and pronunciations of such languages complicate ASR models' success. With the increasing popularity of Deep Learning and Transformers, acoustic models like the renowned Wav2Vec2 have achieved superior performance in the Speech Recognition field compared to state-of-the-art approaches. However, despite Wav2Vec2's improved efficiency over traditional methods, its performance significantly declines for under-represented languages, even though it requires significantly less labeled data. This paper introduces an end-to-end framework that enhances ASR systems fine-tuned on Wav2Vec2 through data augmentation techniques. To validate our framework's effectiveness, we conducted a detailed experimental evaluation using three datasets from Mozilla's Common Voice project in Arabic, Russian, and Portuguese. Additionally, the framework presented in this paper demonstrates robustness to different diacritics. Ultimately, our approach outperforms two previous baseline models, which are the pre-trained Wav2Vec2 and the well-known Whisper ASR model, resulting in an average relative improvement of 33.9\% in Word Error Rate and a 53.2\% relative improvement in Character Error Rate.