 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Walter Skeat's Forty-Five Parallel Extracts of William Langland's Piers Plowman
Dec 29, 2015


Walter Skeat published his critical edition of William Langland's 14th century alliterative poem, Piers Plowman, in 1886. In preparation for this he located forty-five manuscripts, and to compare dialects, he published excerpts from each of these. This paper does three statistical analyses using these excerpts, each of which mimics a task he did in writing his critical edition. First, he combined multiple versions of a poetic line to create a best line, which is compared to the mean string that is computed by a generalization of the arithmetic mean that uses edit distance. Second, he claims that a certain subset of manuscripts varies little. This is quantified by computing a string variance, which is closely related to the above generalization of the mean. Third, he claims that the manuscripts fall into three groups, which is a clustering problem that is addressed by using edit distance. The overall goal is to develop methodology that would be of use to a literary critic.
Quantifying Prosodic Variability in Middle English Alliterative Poetry
Jan 14, 2015

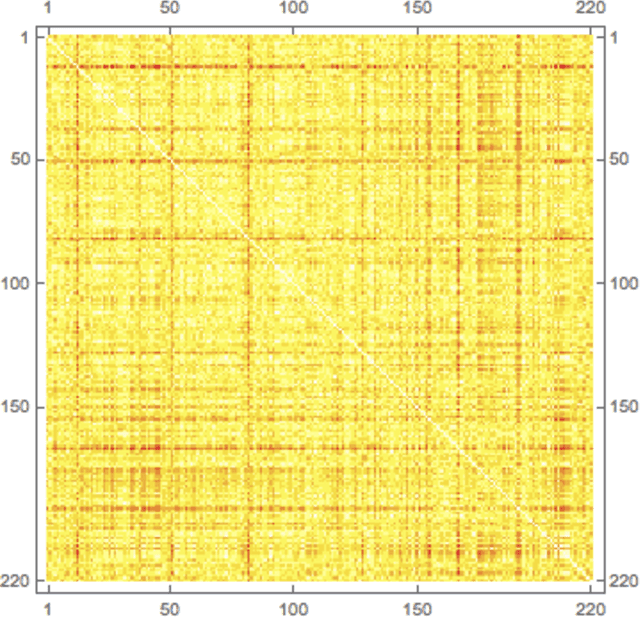

Interest in the mathematical structure of poetry dates back to at least the 19th century: after retiring from his mathematics position, J. J. Sylvester wrote a book on prosody called $\textit{The Laws of Verse}$. Today there is interest in the computer analysis of poems, and this paper discusses how a statistical approach can be applied to this task. Starting with the definition of what Middle English alliteration is, $\textit{Sir Gawain and the Green Knight}$ and William Langland's $\textit{Piers Plowman}$ are used to illustrate the methodology. Theory first developed for analyzing data from a Riemannian manifold turns out to be applicable to strings allowing one to compute a generalized mean and variance for textual data, which is applied to the poems above. The ratio of these two variances produces the analogue of the F test, and resampling allows p-values to be estimated. Consequently, this methodology provides a way to compare prosodic variability between two texts.
Language-based Examples in the Statistics Classroom
Oct 05, 2014



Statistics pedagogy values using a variety of examples. Thanks to text resources on the Web, and since statistical packages have the ability to analyze string data, it is now easy to use language-based examples in a statistics class. Three such examples are discussed here. First, many types of wordplay (e.g., crosswords and hangman) involve finding words with letters that satisfy a certain pattern. Second, linguistics has shown that idiomatic pairs of words often appear together more frequently than chance. For example, in the Brown Corpus, this is true of the phrasal verb to throw up (p-value=7.92E-10.) Third, a pangram contains all the letters of the alphabet at least once. These are searched for in Charles Dickens' A Christmas Carol, and their lengths are compared to the expected value given by the unequal probability coupon collector's problem as well as simulations.