 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisconde: Multi-document QA with GPT-3 and Neural Reranking
Dec 19, 2022This paper proposes a question-answering system that can answer questions whose supporting evidence is spread over multiple (potentially long) documents. The system, called Visconde, uses a three-step pipeline to perform the task: decompose, retrieve, and aggregate. The first step decomposes the question into simpler questions using a few-shot large language model (LLM). Then, a state-of-the-art search engine is used to retrieve candidate passages from a large collection for each decomposed question. In the final step, we use the LLM in a few-shot setting to aggregate the contents of the passages into the final answer. The system is evaluated on three datasets: IIRC, Qasper, and StrategyQA. Results suggest that current retrievers are the main bottleneck and that readers are already performing at the human level as long as relevant passages are provided. The system is also shown to be more effective when the model is induced to give explanations before answering a question. Code is available at \url{https://github.com/neuralmind-ai/visconde}.
In Defense of Cross-Encoders for Zero-Shot Retrieval
Dec 12, 2022Bi-encoders and cross-encoders are widely used in many state-of-the-art retrieval pipelines. In this work we study the generalization ability of these two types of architectures on a wide range of parameter count on both in-domain and out-of-domain scenarios. We find that the number of parameters and early query-document interactions of cross-encoders play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that cross-encoders largely outperform bi-encoders of similar size in several tasks. In the BEIR benchmark, our largest cross-encoder surpasses a state-of-the-art bi-encoder by more than 4 average points. Finally, we show that using bi-encoders as first-stage retrievers provides no gains in comparison to a simpler retriever such as BM25 on out-of-domain tasks. The code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
NeuralSearchX: Serving a Multi-billion-parameter Reranker for Multilingual Metasearch at a Low Cost
Oct 26, 2022



The widespread availability of search API's (both free and commercial) brings the promise of increased coverage and quality of search results for metasearch engines, while decreasing the maintenance costs of the crawling and indexing infrastructures. However, merging strategies frequently comprise complex pipelines that require careful tuning, which is often overlooked in the literature. In this work, we describe NeuralSearchX, a metasearch engine based on a multi-purpose large reranking model to merge results and highlight sentences. Due to the homogeneity of our architecture, we could focus our optimization efforts on a single component. We compare our system with Microsoft's Biomedical Search and show that our design choices led to a much cost-effective system with competitive QPS while having close to state-of-the-art results on a wide range of public benchmarks. Human evaluation on two domain-specific tasks shows that our retrieval system outperformed Google API by a large margin in terms of nDCG@10 scores. By describing our architecture and implementation in detail, we hope that the community will build on our design choices. The system is available at https://neuralsearchx.nsx.ai.
* published as a full paper at the DESIRES 2022 Conference. 13 pages
mRobust04: A Multilingual Version of the TREC Robust 2004 Benchmark
Sep 27, 2022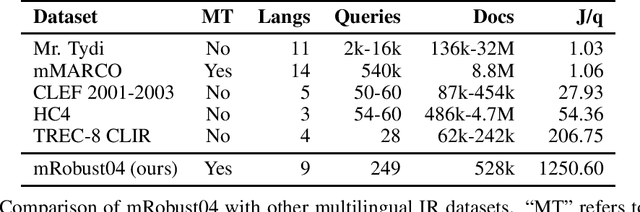
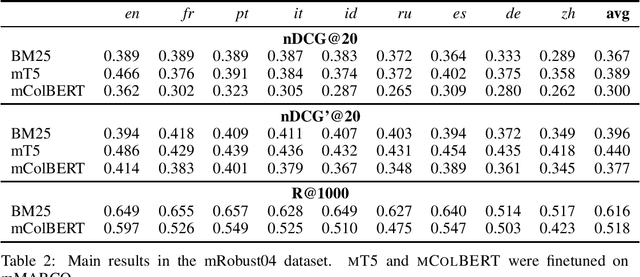
Robust 2004 is an information retrieval benchmark whose large number of judgments per query make it a reliable evaluation dataset. In this paper, we present mRobust04, a multilingual version of Robust04 that was translated to 8 languages using Google Translate. We also provide results of three different multilingual retrievers on this dataset. The dataset is available at https://huggingface.co/datasets/unicamp-dl/mrobust
MonoByte: A Pool of Monolingual Byte-level Language Models
Sep 27, 2022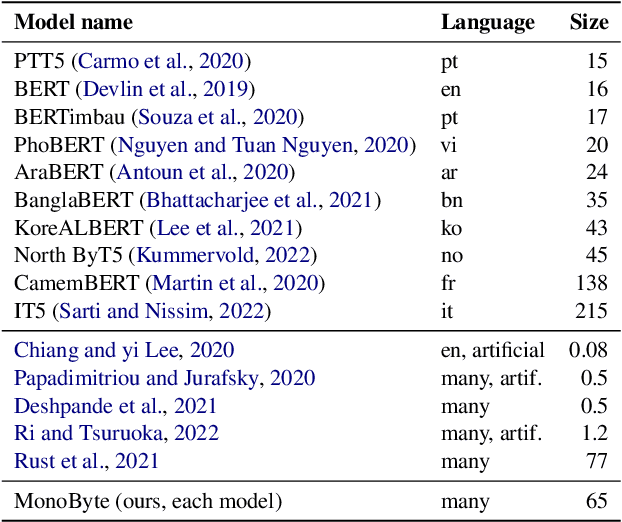
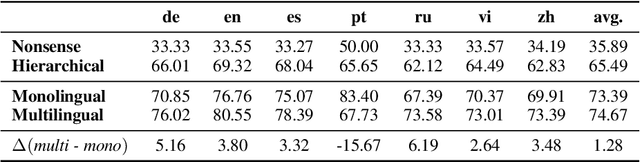
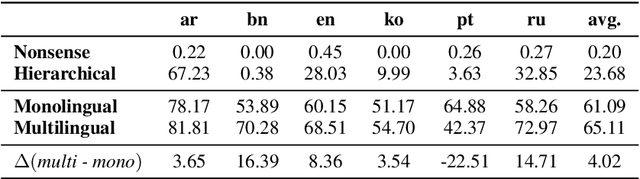
The zero-shot cross-lingual ability of models pretrained on multilingual and even monolingual corpora has spurred many hypotheses to explain this intriguing empirical result. However, due to the costs of pretraining, most research uses public models whose pretraining methodology, such as the choice of tokenization, corpus size, and computational budget, might differ drastically. When researchers pretrain their own models, they often do so under a constrained budget, and the resulting models might underperform significantly compared to SOTA models. These experimental differences led to various inconsistent conclusions about the nature of the cross-lingual ability of these models. To help further research on the topic, we released 10 monolingual byte-level models rigorously pretrained under the same configuration with a large compute budget (equivalent to 420 days on a V100) and corpora that are 4 times larger than the original BERT's. Because they are tokenizer-free, the problem of unseen token embeddings is eliminated, thus allowing researchers to try a wider range of cross-lingual experiments in languages with different scripts. Additionally, we release two models pretrained on non-natural language texts that can be used in sanity-check experiments. Experiments on QA and NLI tasks show that our monolingual models achieve competitive performance to the multilingual one, and hence can be served to strengthen our understanding of cross-lingual transferability in language models.
Induced Natural Language Rationales and Interleaved Markup Tokens Enable Extrapolation in Large Language Models
Aug 24, 2022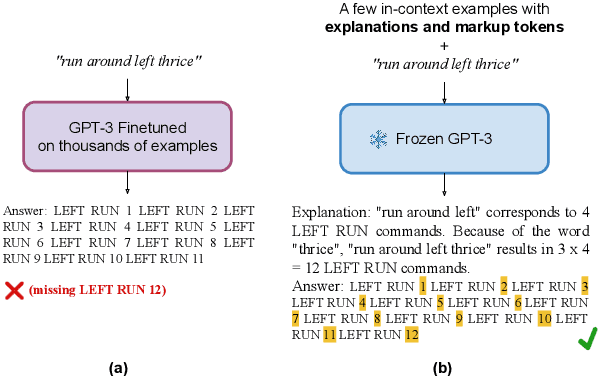
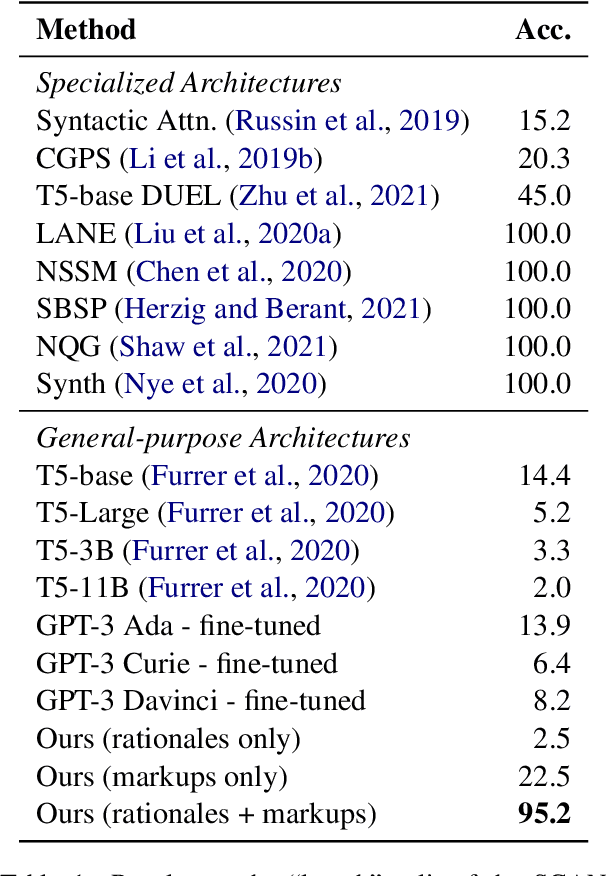
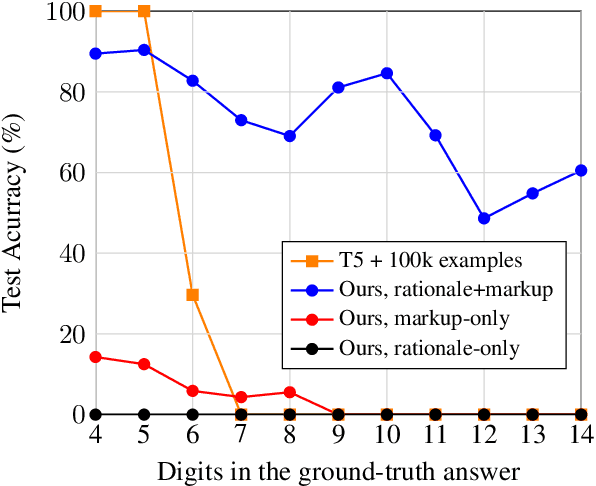

The ability to extrapolate, i.e., to make predictions on sequences that are longer than those presented as training examples, is a challenging problem for current deep learning models. Recent work shows that this limitation persists in state-of-the-art Transformer-based models. Most solutions to this problem use specific architectures or training methods that do not generalize to other tasks. We demonstrate that large language models can succeed in extrapolation without modifying their architecture or training procedure. Experimental results show that generating step-by-step rationales and introducing marker tokens are both required for effective extrapolation. First, we induce it to produce step-by-step rationales before outputting the answer to effectively communicate the task to the model. However, as sequences become longer, we find that current models struggle to keep track of token positions. To address this issue, we interleave output tokens with markup tokens that act as explicit positional and counting symbols. Our findings show how these two complementary approaches enable remarkable sequence extrapolation and highlight a limitation of current architectures to effectively generalize without explicit surface form guidance. Code available at https://github.com/MirelleB/induced-rationales-markup-tokens
A Boring-yet-effective Approach for the Product Ranking Task of the Amazon KDD Cup 2022
Aug 09, 2022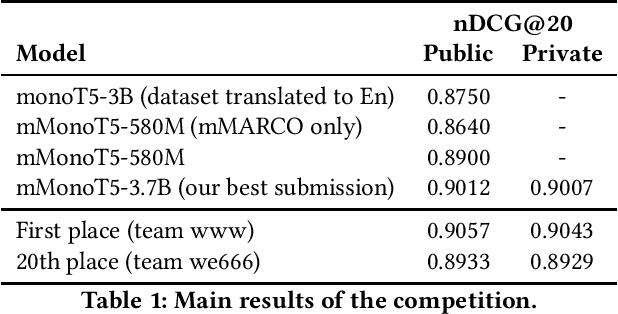
In this work we describe our submission to the product ranking task of the Amazon KDD Cup 2022. We rely on a receipt that showed to be effective in previous competitions: we focus our efforts towards efficiently training and deploying large language odels, such as mT5, while reducing to a minimum the number of task-specific adaptations. Despite the simplicity of our approach, our best model was less than 0.004 nDCG@20 below the top submission. As the top 20 teams achieved an nDCG@20 close to .90, we argue that we need more difficult e-Commerce evaluation datasets to discriminate retrieval methods.
No Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot Retrieval
Jun 06, 2022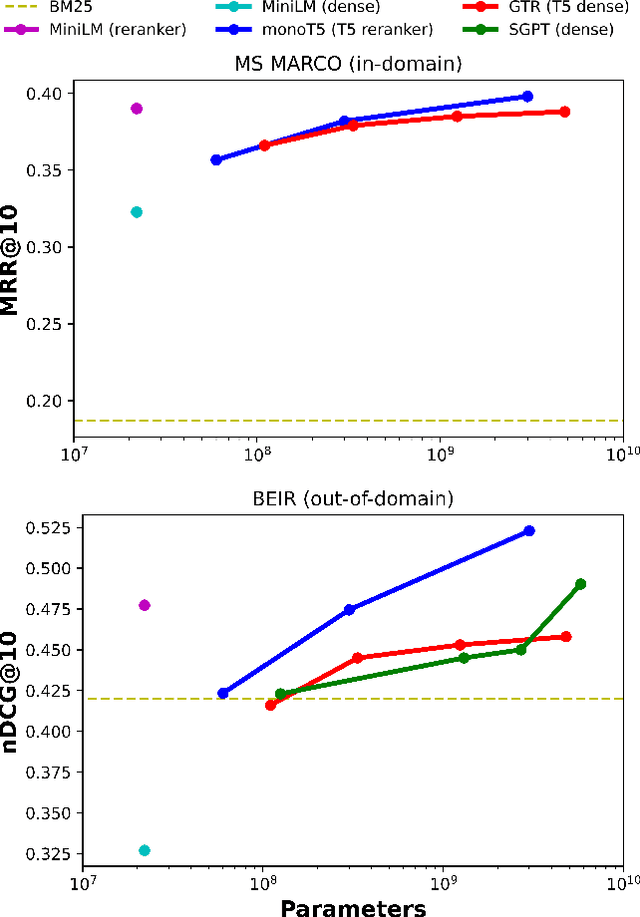
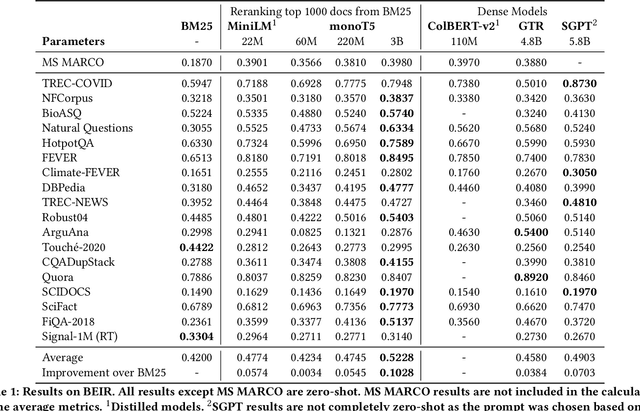
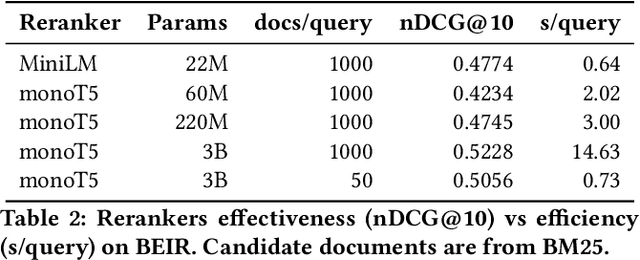
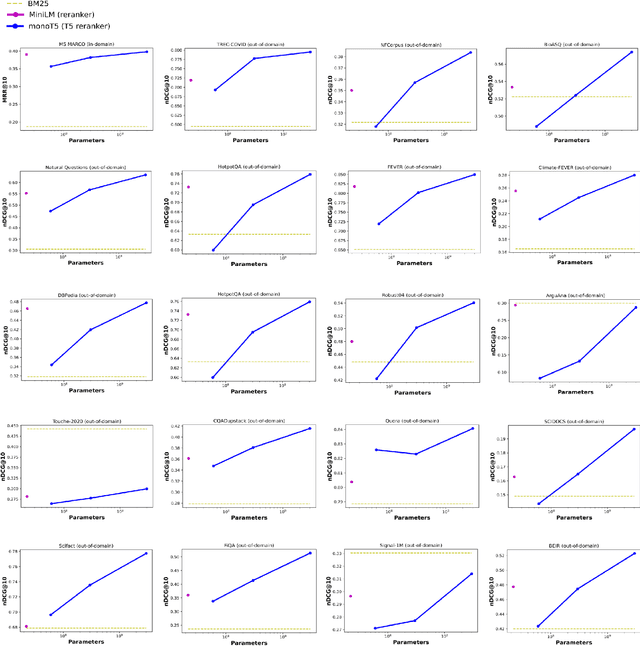
Recent work has shown that small distilled language models are strong competitors to models that are orders of magnitude larger and slower in a wide range of information retrieval tasks. This has made distilled and dense models, due to latency constraints, the go-to choice for deployment in real-world retrieval applications. In this work, we question this practice by showing that the number of parameters and early query-document interaction play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that rerankers largely outperform dense ones of similar size in several tasks. Our largest reranker reaches the state of the art in 12 of the 18 datasets of the Benchmark-IR (BEIR) and surpasses the previous state of the art by 3 average points. Finally, we confirm that in-domain effectiveness is not a good indicator of zero-shot effectiveness. Code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
Billions of Parameters Are Worth More Than In-domain Training Data: A case study in the Legal Case Entailment Task
May 30, 2022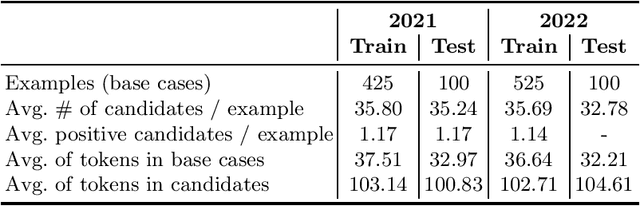
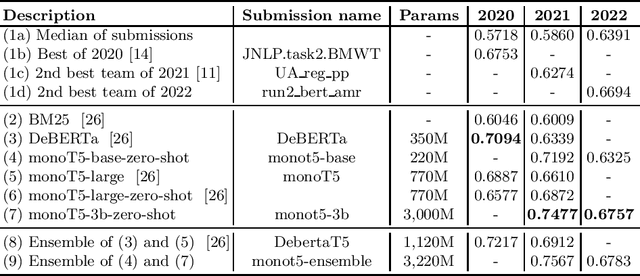
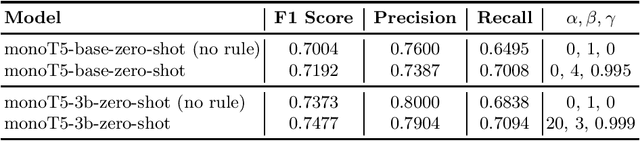
Recent work has shown that language models scaled to billions of parameters, such as GPT-3, perform remarkably well in zero-shot and few-shot scenarios. In this work, we experiment with zero-shot models in the legal case entailment task of the COLIEE 2022 competition. Our experiments show that scaling the number of parameters in a language model improves the F1 score of our previous zero-shot result by more than 6 points, suggesting that stronger zero-shot capability may be a characteristic of larger models, at least for this task. Our 3B-parameter zero-shot model outperforms all models, including ensembles, in the COLIEE 2021 test set and also achieves the best performance of a single model in the COLIEE 2022 competition, second only to the ensemble composed of the 3B model itself and a smaller version of the same model. Despite the challenges posed by large language models, mainly due to latency constraints in real-time applications, we provide a demonstration of our zero-shot monoT5-3b model being used in production as a search engine, including for legal documents. The code for our submission and the demo of our system are available at https://github.com/neuralmind-ai/coliee and https://neuralsearchx.neuralmind.ai, respectively.
InPars: Data Augmentation for Information Retrieval using Large Language Models
Feb 10, 2022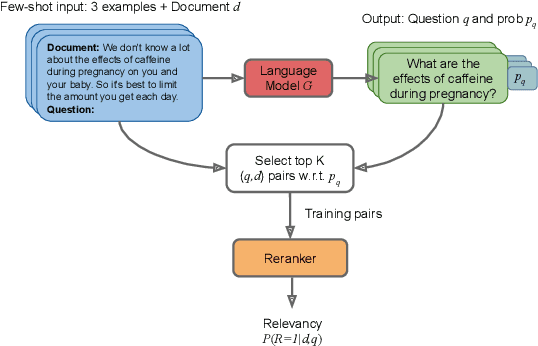
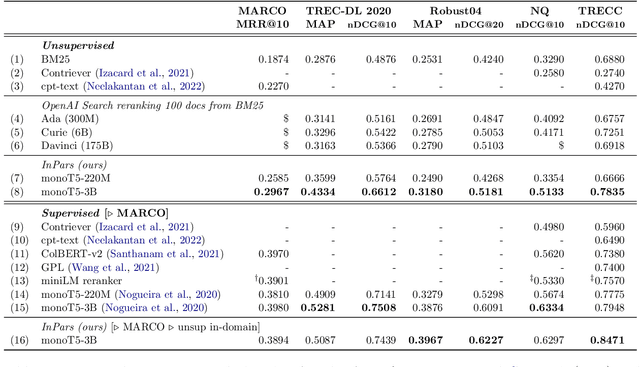


The information retrieval community has recently witnessed a revolution due to large pretrained transformer models. Another key ingredient for this revolution was the MS MARCO dataset, whose scale and diversity has enabled zero-shot transfer learning to various tasks. However, not all IR tasks and domains can benefit from one single dataset equally. Extensive research in various NLP tasks has shown that using domain-specific training data, as opposed to a general-purpose one, improves the performance of neural models. In this work, we harness the few-shot capabilities of large pretrained language models as synthetic data generators for IR tasks. We show that models finetuned solely on our unsupervised dataset outperform strong baselines such as BM25 as well as recently proposed self-supervised dense retrieval methods. Furthermore, retrievers finetuned on both supervised and our synthetic data achieve better zero-shot transfer than models finetuned only on supervised data. Code, models, and data are available at https://github.com/zetaalphavector/inpars .