 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Similarity-Preserving Unsupervised Learning using Modular Sparse Distributed Codes and Novelty-Contingent Noise
Oct 19, 2020There is increasing realization in neuroscience that information is represented in the brain, e.g., neocortex, hippocampus, in the form sparse distributed codes (SDCs), a kind of cell assembly. Two essential questions are: a) how are such codes formed on the basis of single trials, and how is similarity preserved during learning, i.e., how do more similar inputs get mapped to more similar SDCs. I describe a novel Modular Sparse Distributed Code (MSDC) that provides simple, neurally plausible answers to both questions. An MSDC coding field (CF) consists of Q WTA competitive modules (CMs), each comprised of K binary units (analogs of principal cells). The modular nature of the CF makes possible a single-trial, unsupervised learning algorithm that approximately preserves similarity and crucially, runs in fixed time, i.e., the number of steps needed to store an item remains constant as the number of stored items grows. Further, once items are stored as MSDCs in superposition and such that their intersection structure reflects input similarity, both fixed time best-match retrieval and fixed time belief update (updating the probabilities of all stored items) also become possible. The algorithm's core principle is simply to add noise into the process of choosing a code, i.e., choosing a winner in each CM, which is proportional to the novelty of the input. This causes the expected intersection of the code for an input, X, with the code of each previously stored input, Y, to be proportional to the similarity of X and Y. Results demonstrating these capabilities for spatial patterns are given in the appendix.
Superposed Episodic and Semantic Memory via Sparse Distributed Representation
Oct 21, 2017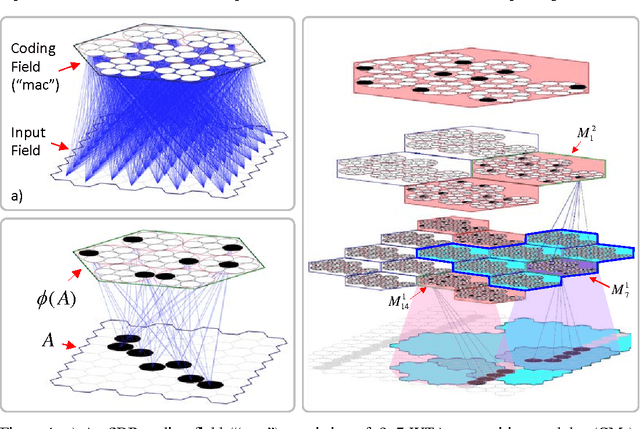



The abilities to perceive, learn, and use generalities, similarities, classes, i.e., semantic memory (SM), is central to cognition. Machine learning (ML), neural network, and AI research has been primarily driven by tasks requiring such abilities. However, another central facet of cognition, single-trial formation of permanent memories of experiences, i.e., episodic memory (EM), has had relatively little focus. Only recently has EM-like functionality been added to Deep Learning (DL) models, e.g., Neural Turing Machine, Memory Networks. However, in these cases: a) EM is implemented as a separate module, which entails substantial data movement (and so, time and power) between the DL net itself and EM; and b) individual items are stored localistically within the EM, precluding realizing the exponential representational efficiency of distributed over localist coding. We describe Sparsey, an unsupervised, hierarchical, spatial/spatiotemporal associative memory model differing fundamentally from mainstream ML models, most crucially, in its use of sparse distributed representations (SDRs), or, cell assemblies, which admits an extremely efficient, single-trial learning algorithm that maps input similarity into code space similarity (measured as intersection). SDRs of individual inputs are stored in superposition and because similarity is preserved, the patterns of intersections over the assigned codes reflect the similarity, i.e., statistical, structure, of all orders, not simply pairwise, over the inputs. Thus, SM, i.e., a generative model, is built as a computationally free side effect of the act of storing episodic memory traces of individual inputs, either spatial patterns or sequences. We report initial results on MNIST and on the Weizmann video event recognition benchmarks. While we have not yet attained SOTA class accuracy, learning takes only minutes on a single CPU.