 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolutionary algorithms driven by neuron coverage metrics for semi-supervised classification
Mar 05, 2023



In some machine learning applications the availability of labeled instances for supervised classification is limited while unlabeled instances are abundant. Semi-supervised learning algorithms deal with these scenarios and attempt to exploit the information contained in the unlabeled examples. In this paper, we address the question of how to evolve neural networks for semi-supervised problems. We introduce neuroevolutionary approaches that exploit unlabeled instances by using neuron coverage metrics computed on the neural network architecture encoded by each candidate solution. Neuron coverage metrics resemble code coverage metrics used to test software, but are oriented to quantify how the different neural network components are covered by test instances. In our neuroevolutionary approach, we define fitness functions that combine classification accuracy computed on labeled examples and neuron coverage metrics evaluated using unlabeled examples. We assess the impact of these functions on semi-supervised problems with a varying amount of labeled instances. Our results show that the use of neuron coverage metrics helps neuroevolution to become less sensitive to the scarcity of labeled data, and can lead in some cases to a more robust generalization of the learned classifiers.
On the Hyperparameters influencing a PINN's generalization beyond the training domain
Feb 15, 2023Physics-Informed Neural Networks (PINNs) are Neural Network architectures trained to emulate solutions of differential equations without the necessity of solution data. They are currently ubiquitous in the scientific literature due to their flexible and promising settings. However, very little of the available research provides practical studies that aim for a better quantitative understanding of such architecture and its functioning. In this paper, we analyze the performance of PINNs for various architectural hyperparameters and algorithmic settings based on a novel error metric and other factors such as training time. The proposed metric and approach are tailored to evaluate how well a PINN generalizes to points outside its training domain. Besides, we investigate the effect of the algorithmic setup on the outcome prediction of a PINN, inside and outside its training domain, to explore the effect of each hyperparameter. Through our study, we assess how the algorithmic setup of PINNs influences their potential for generalization and deduce the settings which maximize the potential of a PINN for accurate generalization. The study that we present returns insightful and at times counterintuitive results on PINNs. These results can be useful in PINN applications when defining the model and evaluating it.
When and How to Fool Explainable Models with Adversarial Examples
Jul 05, 2021
Reliable deployment of machine learning models such as neural networks continues to be challenging due to several limitations. Some of the main shortcomings are the lack of interpretability and the lack of robustness against adversarial examples or out-of-distribution inputs. In this paper, we explore the possibilities and limits of adversarial attacks for explainable machine learning models. First, we extend the notion of adversarial examples to fit in explainable machine learning scenarios, in which the inputs, the output classifications and the explanations of the model's decisions are assessed by humans. Next, we propose a comprehensive framework to study whether (and how) adversarial examples can be generated for explainable models under human assessment, introducing novel attack paradigms. In particular, our framework considers a wide range of relevant (yet often ignored) factors such as the type of problem, the user expertise or the objective of the explanations in order to identify the attack strategies that should be adopted in each scenario to successfully deceive the model (and the human). These contributions intend to serve as a basis for a more rigorous and realistic study of adversarial examples in the field of explainable machine learning.
Redefining Neural Architecture Search of Heterogeneous Multi-Network Models by Characterizing Variation Operators and Model Components
Jun 16, 2021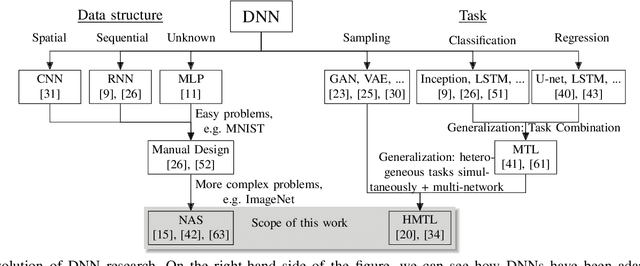
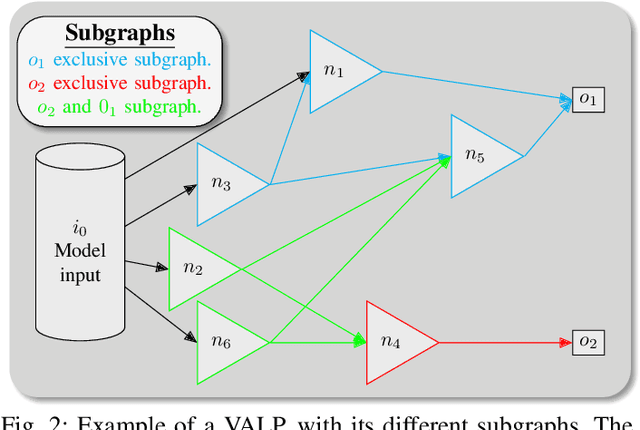
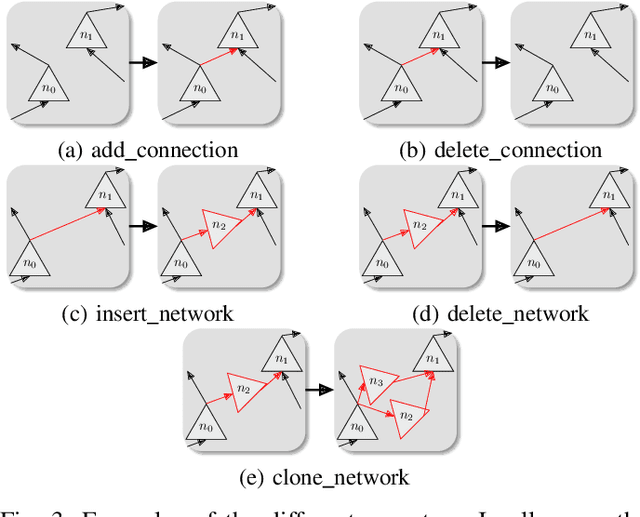
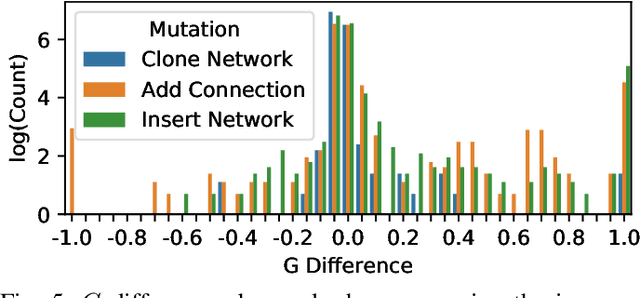
With neural architecture search methods gaining ground on manually designed deep neural networks -even more rapidly as model sophistication escalates-, the research trend shifts towards arranging different and often increasingly complex neural architecture search spaces. In this conjuncture, delineating algorithms which can efficiently explore these search spaces can result in a significant improvement over currently used methods, which, in general, randomly select the structural variation operator, hoping for a performance gain. In this paper, we investigate the effect of different variation operators in a complex domain, that of multi-network heterogeneous neural models. These models have an extensive and complex search space of structures as they require multiple sub-networks within the general model in order to answer to different output types. From that investigation, we extract a set of general guidelines, whose application is not limited to that particular type of model, and are useful to determine the direction in which an architecture optimization method could find the largest improvement. To deduce the set of guidelines, we characterize both the variation operators, according to their effect on the complexity and performance of the model; and the models, relying on diverse metrics which estimate the quality of the different parts composing it.
On the Exploitation of Neuroevolutionary Information: Analyzing the Past for a More Efficient Future
May 26, 2021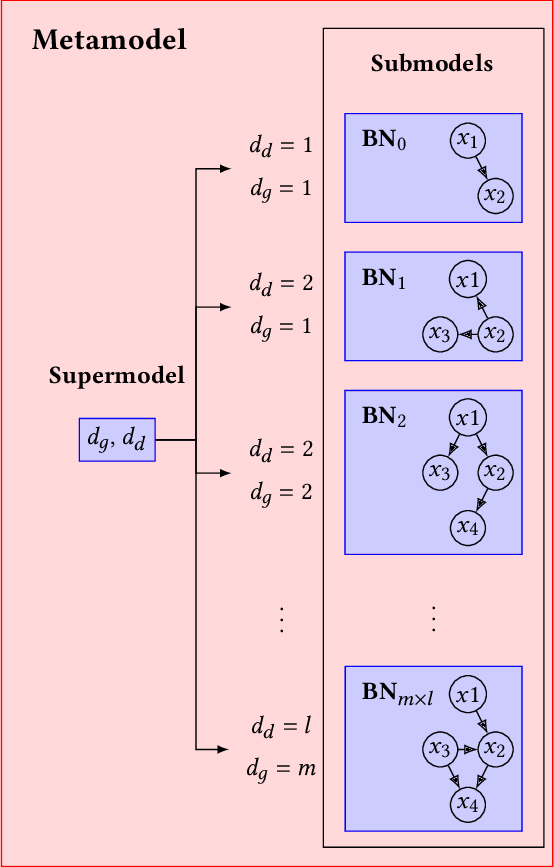
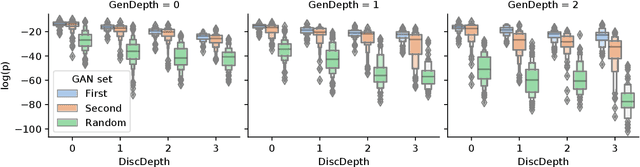
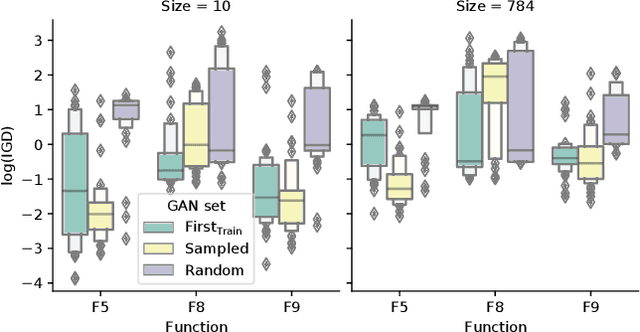
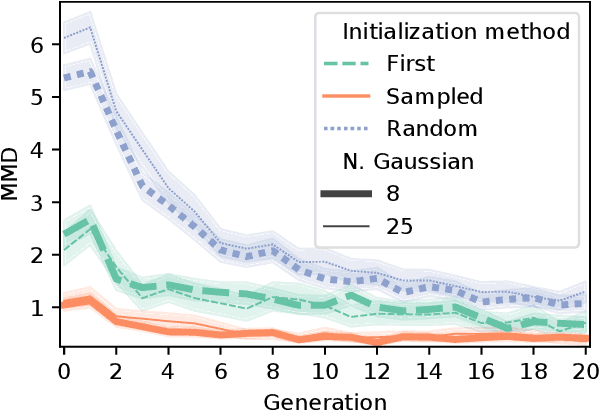
Neuroevolutionary algorithms, automatic searches of neural network structures by means of evolutionary techniques, are computationally costly procedures. In spite of this, due to the great performance provided by the architectures which are found, these methods are widely applied. The final outcome of neuroevolutionary processes is the best structure found during the search, and the rest of the procedure is commonly omitted in the literature. However, a good amount of residual information consisting of valuable knowledge that can be extracted is also produced during these searches. In this paper, we propose an approach that extracts this information from neuroevolutionary runs, and use it to build a metamodel that could positively impact future neural architecture searches. More specifically, by inspecting the best structures found during neuroevolutionary searches of generative adversarial networks with varying characteristics (e.g., based on dense or convolutional layers), we propose a Bayesian network-based model which can be used to either find strong neural structures right away, conveniently initialize different structural searches for different problems, or help future optimization of structures of any type to keep finding increasingly better structures where uninformed methods get stuck into local optima.
Analysis of Dominant Classes in Universal Adversarial Perturbations
Jan 11, 2021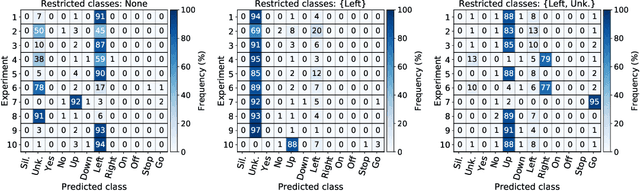
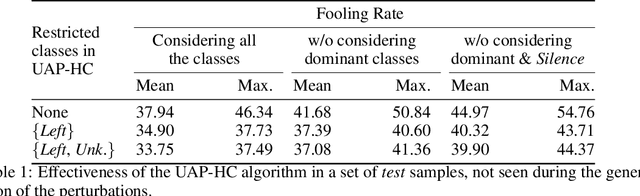
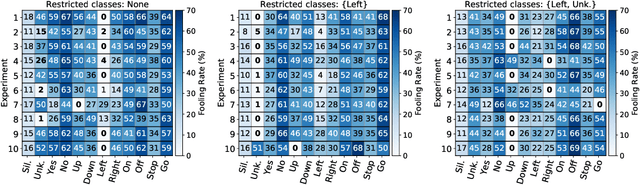
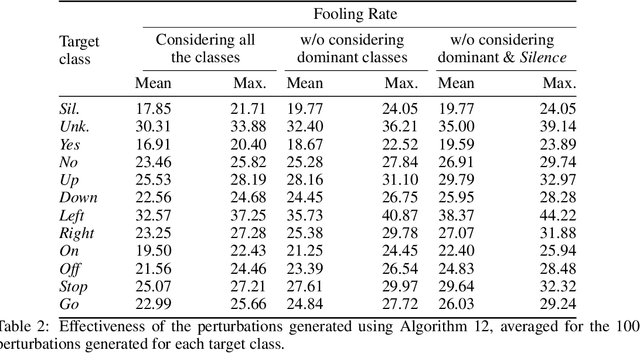
The reasons why Deep Neural Networks are susceptible to being fooled by adversarial examples remains an open discussion. Indeed, many different strategies can be employed to efficiently generate adversarial attacks, some of them relying on different theoretical justifications. Among these strategies, universal (input-agnostic) perturbations are of particular interest, due to their capability to fool a network independently of the input in which the perturbation is applied. In this work, we investigate an intriguing phenomenon of universal perturbations, which has been reported previously in the literature, yet without a proven justification: universal perturbations change the predicted classes for most inputs into one particular (dominant) class, even if this behavior is not specified during the creation of the perturbation. In order to justify the cause of this phenomenon, we propose a number of hypotheses and experimentally test them using a speech command classification problem in the audio domain as a testbed. Our analyses reveal interesting properties of universal perturbations, suggest new methods to generate such attacks and provide an explanation of dominant classes, under both a geometric and a data-feature perspective.
Extending Adversarial Attacks to Produce Adversarial Class Probability Distributions
Apr 14, 2020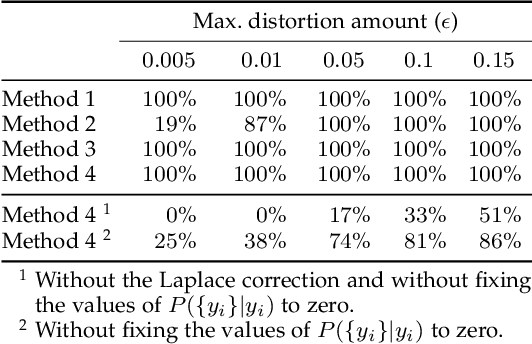
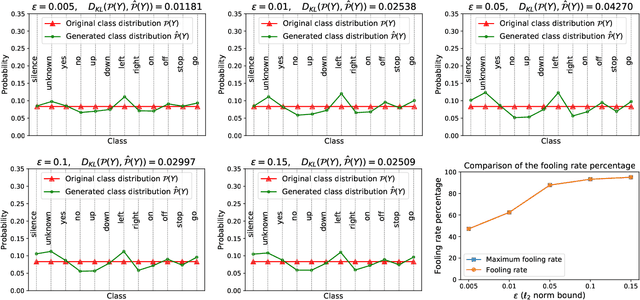
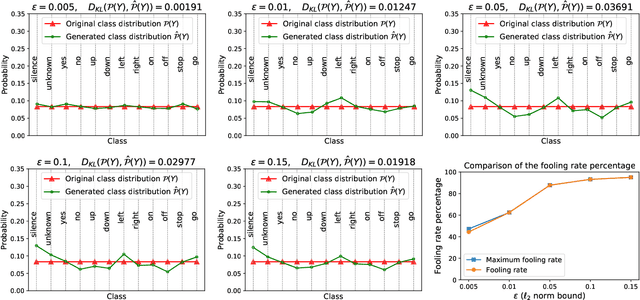
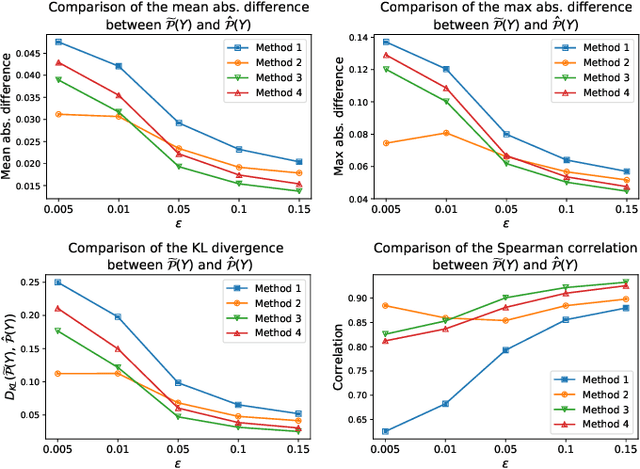
Despite the remarkable performance and generalization levels of deep learning models in a wide range of artificial intelligence tasks, it has been demonstrated that these models can be easily fooled by the addition of imperceptible but malicious perturbations to natural inputs. These altered inputs are known in the literature as adversarial examples. In this paper we propose a novel probabilistic framework to generalize and extend adversarial attacks in order to produce a desired probability distribution for the classes when we apply the attack method to a large number of inputs. This novel attack strategy provides the attacker with greater control over the target model, and increases the complexity of detecting that the model is being attacked. We introduce three different strategies to efficiently generate such attacks, and illustrate our approach extending DeepFool, a state-of-the-art attack algorithm to generate adversarial examples. We also experimentally validate our approach for the spoken command classification task, an exemplary machine learning problem in the audio domain. Our results demonstrate that we can closely approximate any probability distribution for the classes while maintaining a high fooling rate and by injecting imperceptible perturbations to the inputs.
On the human evaluation of audio adversarial examples
Jan 23, 2020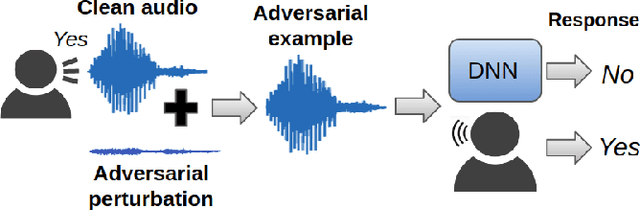
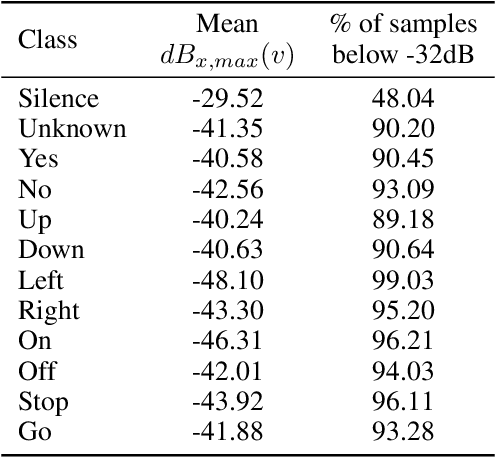
Human-machine interaction is increasingly dependent on speech communication. Machine Learning models are usually applied to interpret human speech commands. However, these models can be fooled by adversarial examples, which are inputs intentionally perturbed to produce a wrong prediction without being noticed. While much research has been focused on developing new techniques to generate adversarial perturbations, less attention has been given to aspects that determine whether and how the perturbations are noticed by humans. This question is relevant since high fooling rates of proposed adversarial perturbation strategies are only valuable if the perturbations are not detectable. In this paper we investigate to which extent the distortion metrics proposed in the literature for audio adversarial examples, and which are commonly applied to evaluate the effectiveness of methods for generating these attacks, are a reliable measure of the human perception of the perturbations. Using an analytical framework, and an experiment in which 18 subjects evaluate audio adversarial examples, we demonstrate that the metrics employed by convention are not a reliable measure of the perceptual similarity of adversarial examples in the audio domain.
Universal adversarial examples in speech command classification
Nov 26, 2019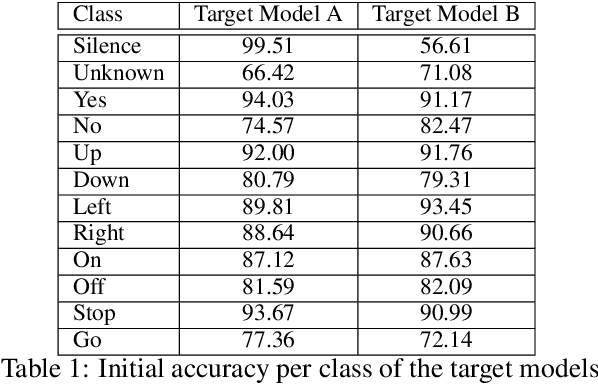
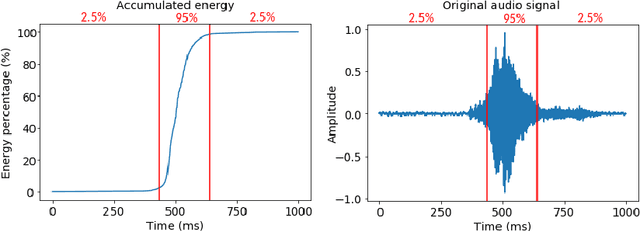
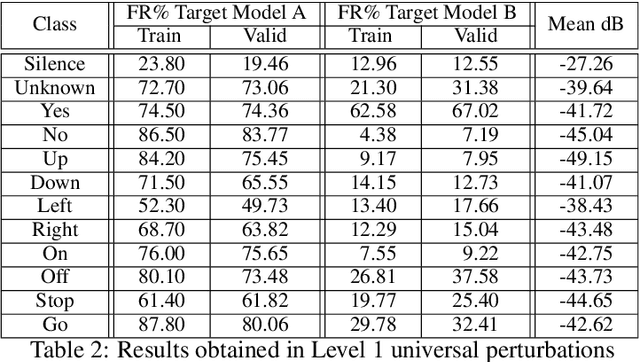
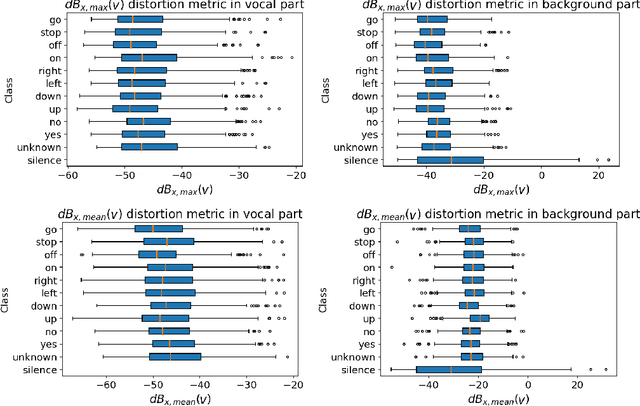
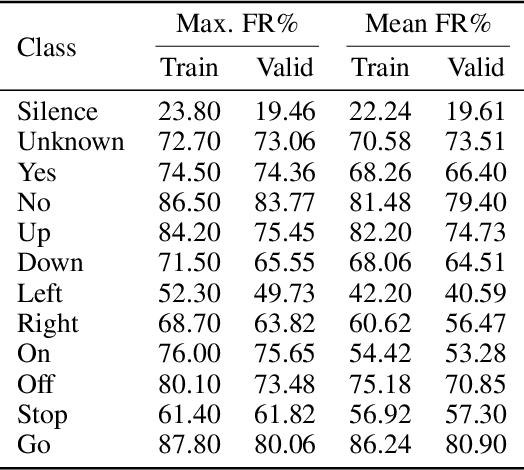
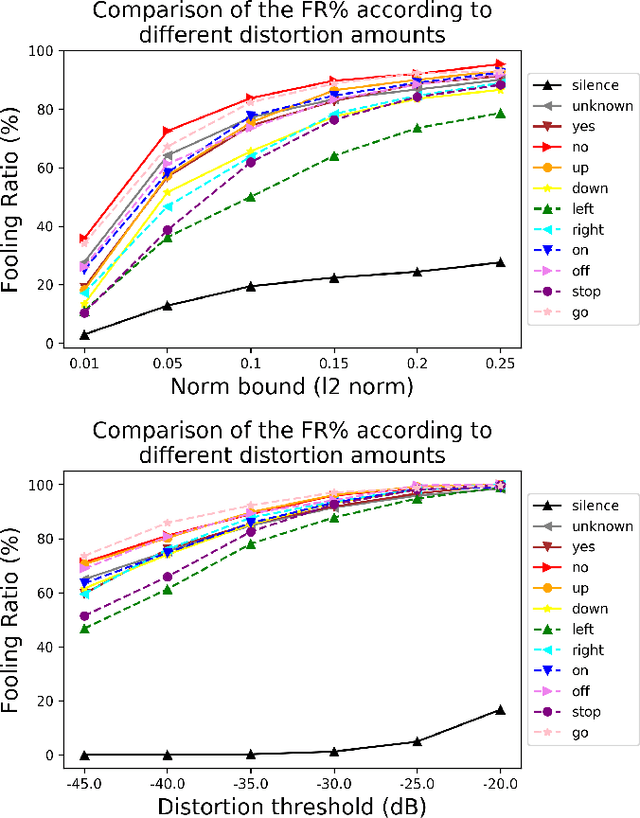
Adversarial examples are inputs intentionally perturbed with the aim of forcing a machine learning model to produce a wrong prediction, while the changes are not easily detectable by a human. Although this topic has been intensively studied in the image domain, classification tasks in the audio domain have received less attention. In this paper we address the existence of universal perturbations for speech command classification. We provide evidence that universal attacks can be generated for speech command classification tasks, which are able to generalize across different models to a significant extent. Additionally, a novel analytical framework is proposed for the evaluation of universal perturbations under different levels of universality, demonstrating that the feasibility of generating effective perturbations decreases as the universality level increases. Finally, we propose a more detailed and rigorous framework to measure the amount of distortion introduced by the perturbations, demonstrating that the methods employed by convention are not realistic in audio-based problems.
Evolving Gaussian Process kernels from elementary mathematical expressions
Oct 14, 2019
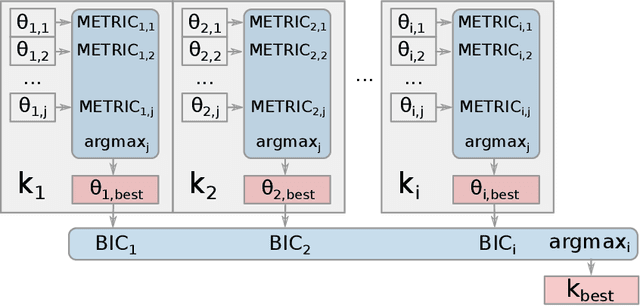
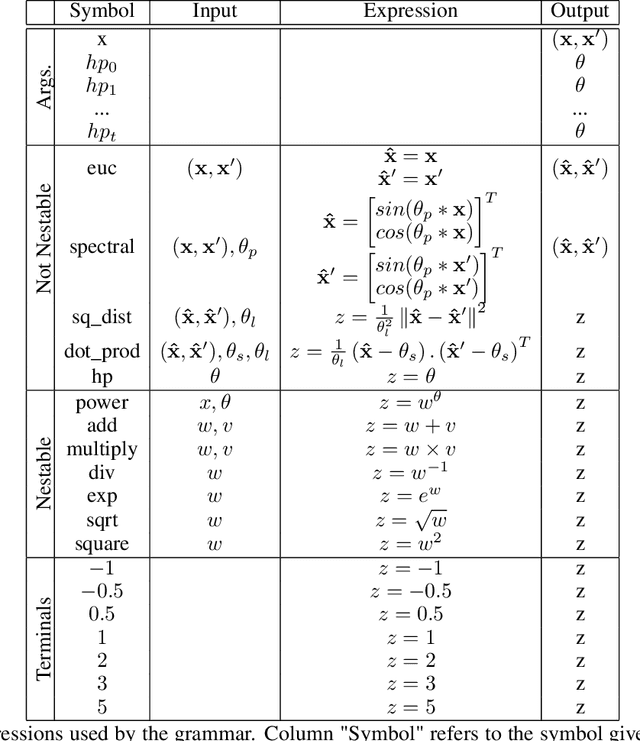
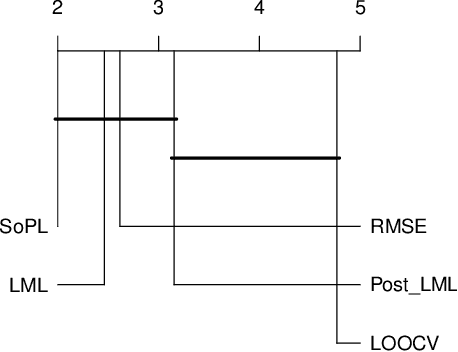
Choosing the most adequate kernel is crucial in many Machine Learning applications. Gaussian Process is a state-of-the-art technique for regression and classification that heavily relies on a kernel function. However, in the Gaussian Process literature, kernels have usually been either ad hoc designed, selected from a predefined set, or searched for in a space of compositions of kernels which have been defined a priori. In this paper, we propose a Genetic-Programming algorithm that represents a kernel function as a tree of elementary mathematical expressions. By means of this representation, a wider set of kernels can be modeled, where potentially better solutions can be found, although new challenges also arise. The proposed algorithm is able to overcome these difficulties and find kernels that accurately model the characteristics of the data. This method has been tested in several real-world time-series extrapolation problems, improving the state-of-the-art results while reducing the complexity of the kernels.