 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Classification with Deep Generative Forests
Jul 11, 2020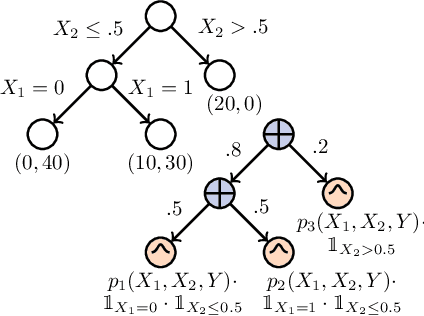
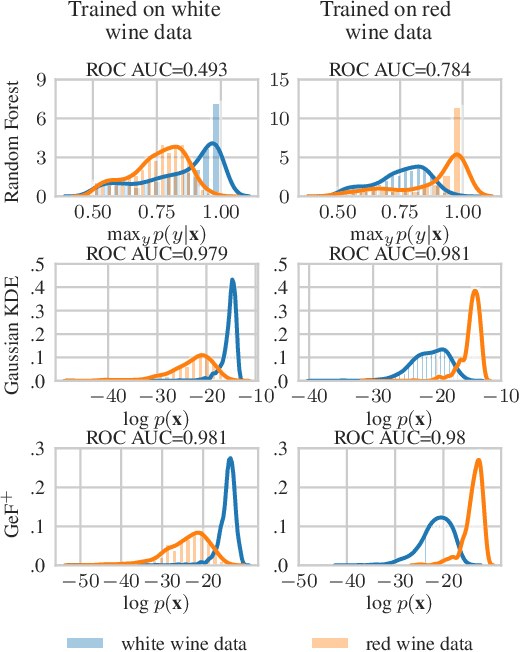
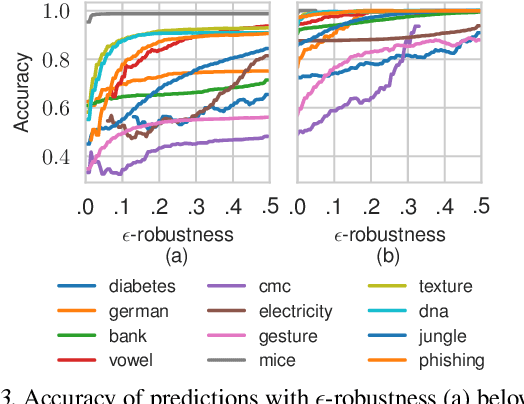

Decision Trees and Random Forests are among the most widely used machine learning models, and often achieve state-of-the-art performance in tabular, domain-agnostic datasets. Nonetheless, being primarily discriminative models they lack principled methods to manipulate the uncertainty of predictions. In this paper, we exploit Generative Forests (GeFs), a recent class of deep probabilistic models that addresses these issues by extending Random Forests to generative models representing the full joint distribution over the feature space. We demonstrate that GeFs are uncertainty-aware classifiers, capable of measuring the robustness of each prediction as well as detecting out-of-distribution samples.
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits
Apr 13, 2020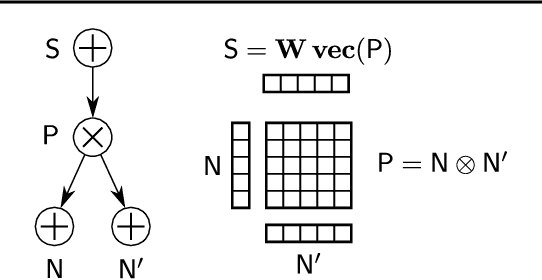

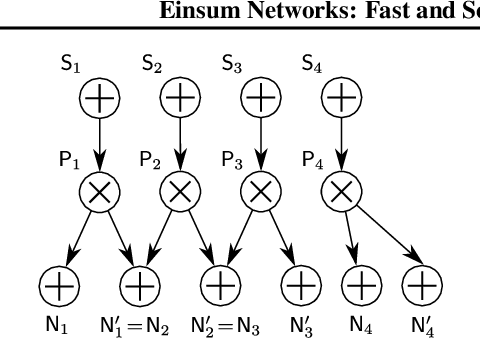
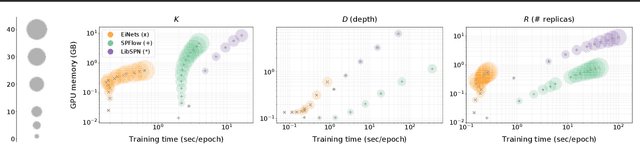
Probabilistic circuits (PCs) are a promising avenue for probabilistic modeling, as they permit a wide range of exact and efficient inference routines. Recent ``deep-learning-style'' implementations of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation-Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Furthermore, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.
Resource-Efficient Neural Networks for Embedded Systems
Jan 07, 2020
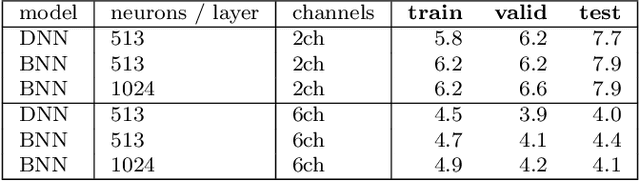
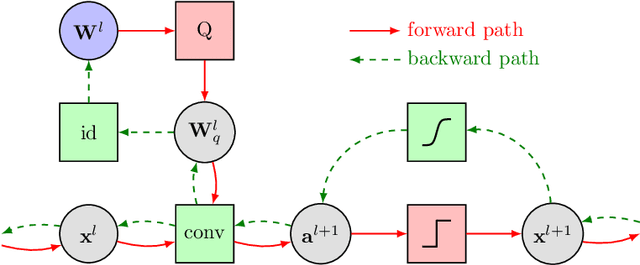
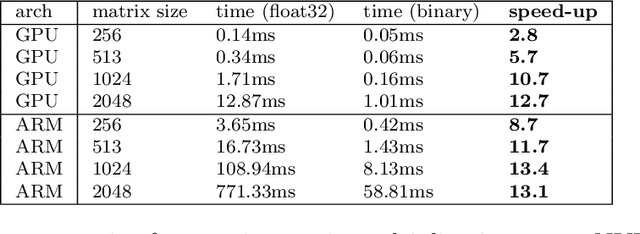
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We substantiate our discussion with experiments on well-known benchmark data sets to showcase the difficulty of finding good trade-offs between resource-efficiency and predictive performance.
Sum-Product Network Decompilation
Dec 20, 2019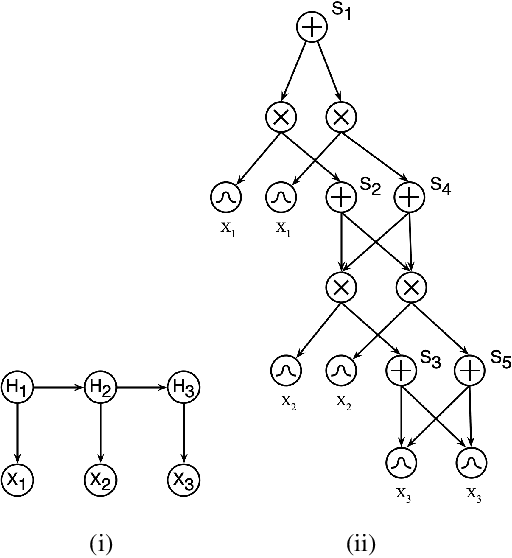
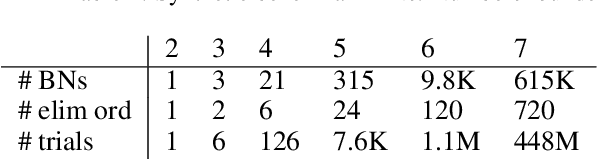
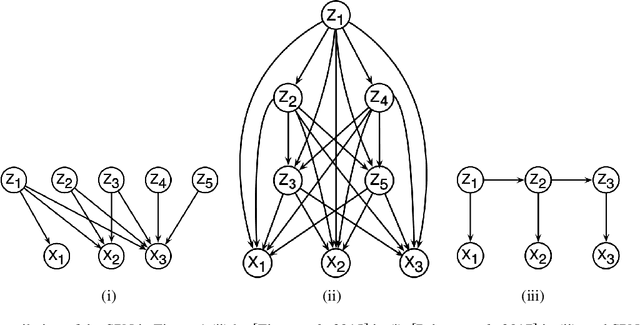
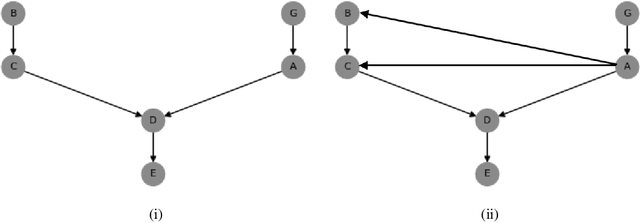
There exists a dichotomy between classical probabilistic graphical models, such as Bayesian networks (BNs), and modern tractable models, such as sum-product networks (SPNs). The former have generally intractable inference, but allow a high level of interpretability, while the latter admits a wide range of tractable inference routines, but are typically harder to interpret. Due to this dichotomy, tools to convert between BNs and SPNs are desirable. While one direction -- compiling BNs into SPNs -- is well discussed in Darwiche's seminal work on arithmetic circuit compilation, the converse direction -- decompiling SPNs into BNs -- has received surprisingly little attention. In this paper, we fill this gap by proposing SPN2BN, an algorithm that decompiles an SPN into a BN. SPN2BN has several salient features when compared to the only other two works decompiling SPNs. Most significantly, the BNs returned by SPN2BN are minimal independence-maps. Secondly, SPN2BN is more parsimonious with respect to the introduction of latent variables. Thirdly, the output BN produced by SPN2BN can be precisely characterized with respect to the compiled BN. More specifically, a certain set of directed edges will be added to the input BN, giving what we will call the moral-closure. It immediately follows that there is a set of BNs related to the input BN that will also return the same moral closure. Lastly, it is established that our compilation-decompilation process is idempotent. We confirm our results with systematic experiments on a number of synthetic BNs.
Deep Structured Mixtures of Gaussian Processes
Oct 10, 2019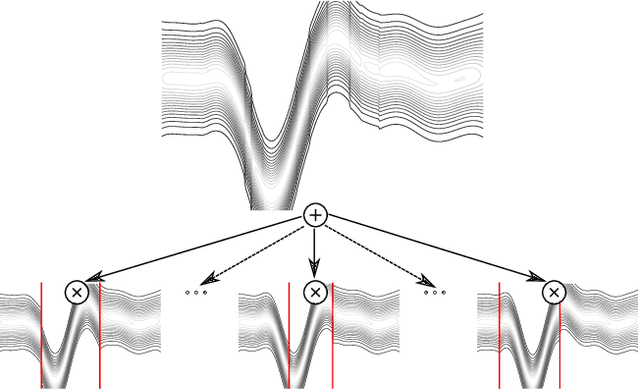
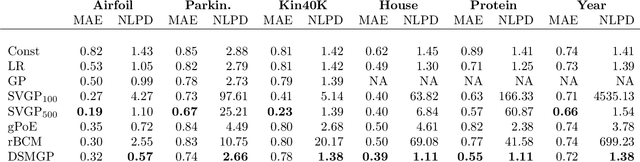
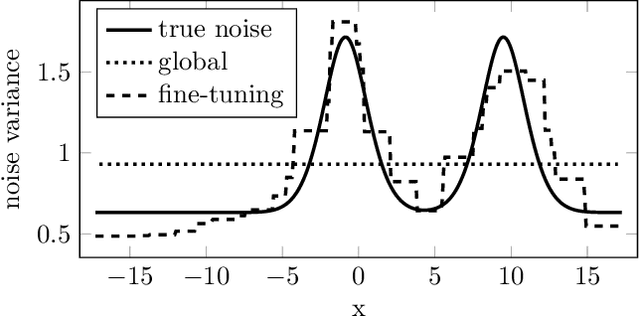
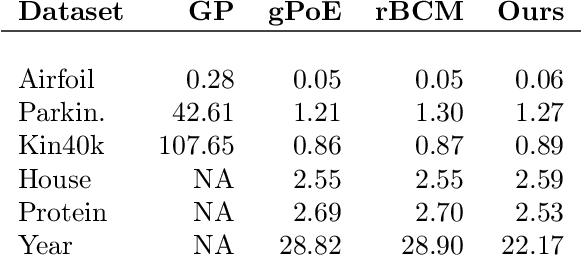
Gaussian Processes (GPs) are powerful non-parametric Bayesian regression models that allow exact posterior inference, but exhibit high computational and memory costs. In order to improve scalability of GPs, approximate posterior inference is frequently employed, where a prominent class of approximation techniques is based on local GP experts. However, the local-expert techniques proposed so far are either not well-principled, come with limited approximation guarantees, or lead to intractable models. In this paper, we introduce deep structured mixtures of GP experts, a stochastic process model which i) allows exact posterior inference, ii) has attractive computational and memory costs, and iii), when used as GP approximation, captures predictive uncertainties consistently better than previous approximations. In a variety of experiments, we show that deep structured mixtures have a low approximation error and outperform existing expert-based approaches.
Optimisation of Overparametrized Sum-Product Networks
May 29, 2019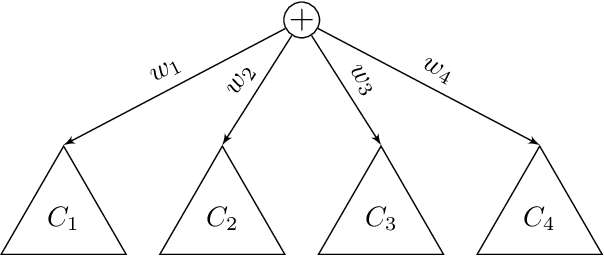
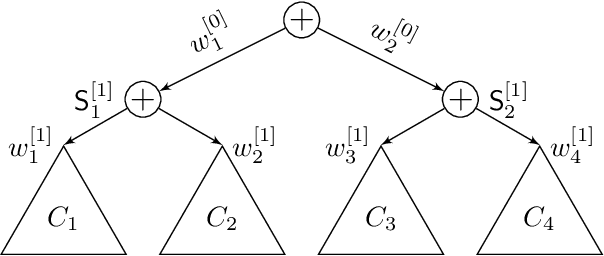
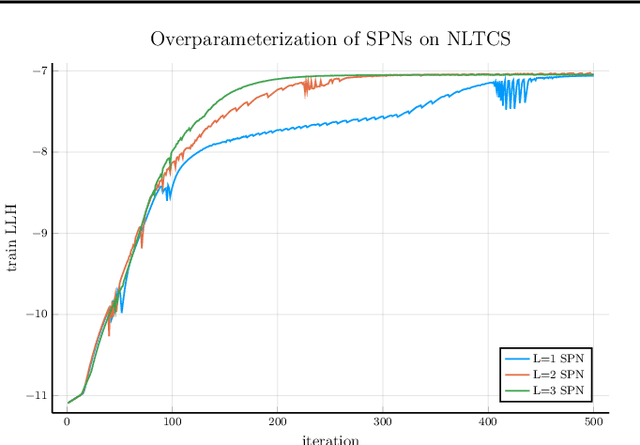
It seems to be a pearl of conventional wisdom that parameter learning in deep sum-product networks is surprisingly fast compared to shallow mixture models. This paper examines the effects of overparameterization in sum-product networks on the speed of parameter optimisation. Using theoretical analysis and empirical experiments, we show that deep sum-product networks exhibit an implicit acceleration compared to their shallow counterpart. In fact, gradient-based optimisation in deep tree-structured sum-product networks is equal to gradient ascend with adaptive and time-varying learning rates and additional momentum terms.
Bayesian Learning of Sum-Product Networks
May 26, 2019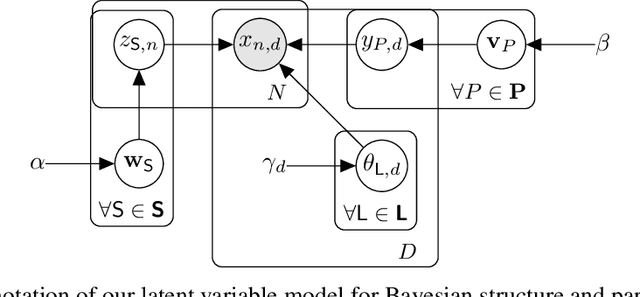
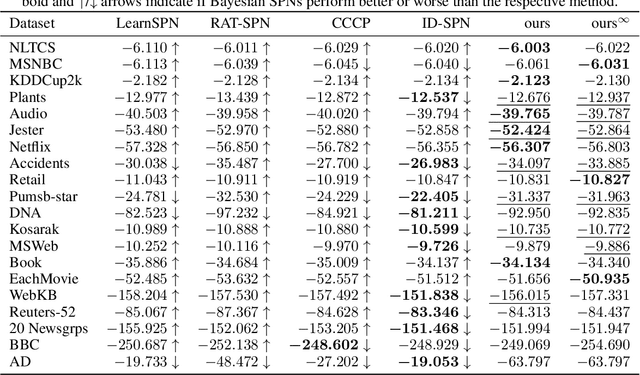
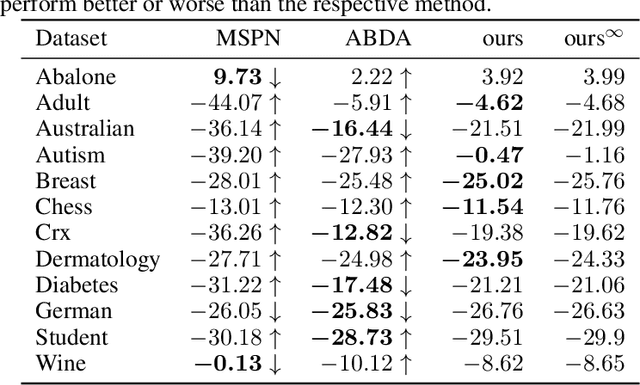
Sum-product networks (SPNs) are flexible density estimators and have received significant attention, due to their attractive inference properties. While parameter learning in SPNs is well developed, structure learning leaves something to be desired: Even though there is a plethora of SPN structure learners, most of them are somewhat ad-hoc, and based on intuition rather than a clear learning principle. In this paper, we introduce a well-principled Bayesian framework for SPN structure learning. First, we decompose the problem into i) laying out a basic computational graph, and ii) learning the so-called scope function over the graph. The first is rather unproblematic and akin to neural network architecture validation. The second characterises the effective structure of the SPN and needs to respect the usual structural constraints in SPN, i.e. completeness and decomposability. While representing and learning the scope function is rather involved in general, in this paper, we propose a natural parametrisation for an important and widely used special case of SPNs. These structural parameters are incorporated into a Bayesian model, such that simultaneous structure and parameter learning is cast into monolithic Bayesian posterior inference. In various experiments, our Bayesian SPNs often improve test likelihoods over greedy SPN learners. Further, since the Bayesian framework protects against overfitting, we are able to evaluate hyper-parameters directly on the Bayesian model score, waiving the need for a separate validation set, which is especially beneficial in low data regimes. Bayesian SPNs can be applied to heterogeneous domains and can easily be extended to nonparametric formulations. Moreover, our Bayesian approach is the first which consistently and robustly learns SPN structures under missing data.
Conditional Sum-Product Networks: Imposing Structure on Deep Probabilistic Architectures
May 21, 2019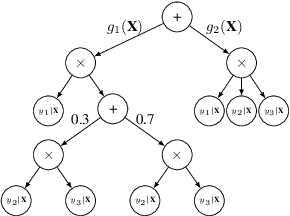
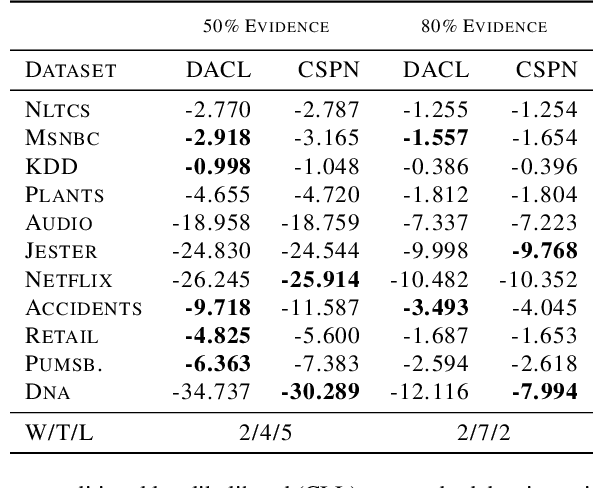
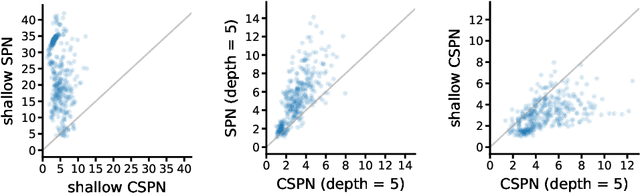

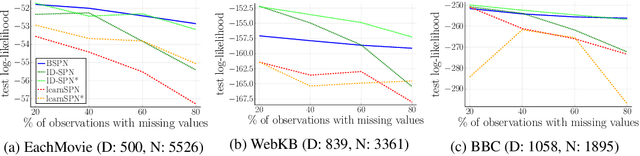
Bayesian networks are a central tool in machine learning and artificial intelligence, and make use of conditional independencies to impose structure on joint distributions. However, they are generally not as expressive as deep learning models and inference is hard and slow. In contrast, deep probabilistic models such as sum-product networks (SPNs) capture joint distributions in a tractable fashion, but use little interpretable structure. Here, we extend the notion of SPNs towards conditional distributions, which combine simple conditional models into high-dimensional ones. As shown in our experiments, the resulting conditional SPNs can be naturally used to impose structure on deep probabilistic models, allow for mixed data types, while maintaining fast and efficient inference.
SPFlow: An Easy and Extensible Library for Deep Probabilistic Learning using Sum-Product Networks
Jan 11, 2019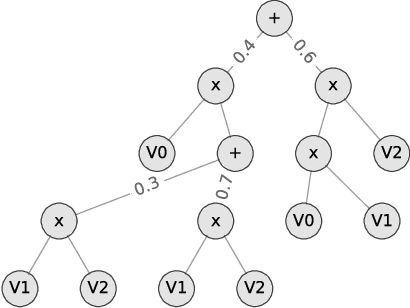
We introduce SPFlow, an open-source Python library providing a simple interface to inference, learning and manipulation routines for deep and tractable probabilistic models called Sum-Product Networks (SPNs). The library allows one to quickly create SPNs both from data and through a domain specific language (DSL). It efficiently implements several probabilistic inference routines like computing marginals, conditionals and (approximate) most probable explanations (MPEs) along with sampling as well as utilities for serializing, plotting and structure statistics on an SPN. Moreover, many of the algorithms proposed in the literature to learn the structure and parameters of SPNs are readily available in SPFlow. Furthermore, SPFlow is extremely extensible and customizable, allowing users to promptly distill new inference and learning routines by injecting custom code into a lightweight functional-oriented API framework. This is achieved in SPFlow by keeping an internal Python representation of the graph structure that also enables practical compilation of an SPN into a TensorFlow graph, C, CUDA or FPGA custom code, significantly speeding-up computations.
Efficient and Robust Machine Learning for Real-World Systems
Dec 05, 2018
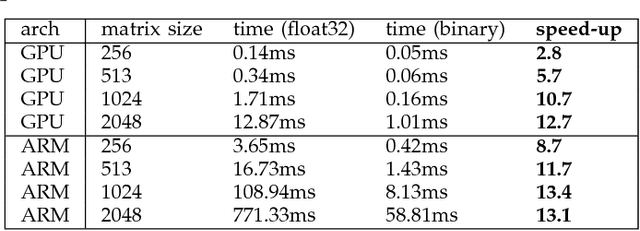
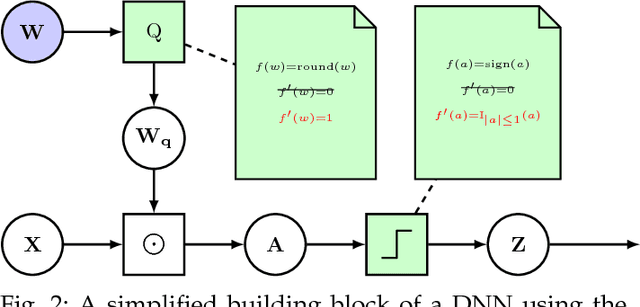
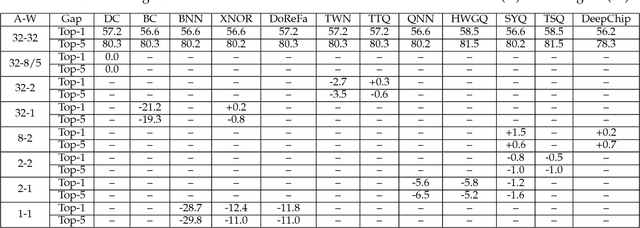
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation and the vision of the Internet-of-Things fuel the interest in resource efficient approaches. These approaches require a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. On top of this, it is crucial to treat uncertainty in a consistent manner in all but the simplest applications of machine learning systems. In particular, a desideratum for any real-world system is to be robust in the presence of outliers and corrupted data, as well as being `aware' of its limits, i.e.\ the system should maintain and provide an uncertainty estimate over its own predictions. These complex demands are among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. First we provide a comprehensive review of resource-efficiency in deep neural networks with focus on techniques for model size reduction, compression and reduced precision. These techniques can be applied during training or as post-processing and are widely used to reduce both computational complexity and memory footprint. As most (practical) neural networks are limited in their ways to treat uncertainty, we contrast them with probabilistic graphical models, which readily serve these desiderata by means of probabilistic inference. In that way, we provide an extensive overview of the current state-of-the-art of robust and efficient machine learning for real-world systems.