 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCauchy-Schwarz Divergence Information Bottleneck for Regression
Apr 27, 2024



The information bottleneck (IB) approach is popular to improve the generalization, robustness and explainability of deep neural networks. Essentially, it aims to find a minimum sufficient representation $\mathbf{t}$ by striking a trade-off between a compression term $I(\mathbf{x};\mathbf{t})$ and a prediction term $I(y;\mathbf{t})$, where $I(\cdot;\cdot)$ refers to the mutual information (MI). MI is for the IB for the most part expressed in terms of the Kullback-Leibler (KL) divergence, which in the regression case corresponds to prediction based on mean squared error (MSE) loss with Gaussian assumption and compression approximated by variational inference. In this paper, we study the IB principle for the regression problem and develop a new way to parameterize the IB with deep neural networks by exploiting favorable properties of the Cauchy-Schwarz (CS) divergence. By doing so, we move away from MSE-based regression and ease estimation by avoiding variational approximations or distributional assumptions. We investigate the improved generalization ability of our proposed CS-IB and demonstrate strong adversarial robustness guarantees. We demonstrate its superior performance on six real-world regression tasks over other popular deep IB approaches. We additionally observe that the solutions discovered by CS-IB always achieve the best trade-off between prediction accuracy and compression ratio in the information plane. The code is available at \url{https://github.com/SJYuCNEL/Cauchy-Schwarz-Information-Bottleneck}.
View it like a radiologist: Shifted windows for deep learning augmentation of CT images
Nov 25, 2023Deep learning has the potential to revolutionize medical practice by automating and performing important tasks like detecting and delineating the size and locations of cancers in medical images. However, most deep learning models rely on augmentation techniques that treat medical images as natural images. For contrast-enhanced Computed Tomography (CT) images in particular, the signals producing the voxel intensities have physical meaning, which is lost during preprocessing and augmentation when treating such images as natural images. To address this, we propose a novel preprocessing and intensity augmentation scheme inspired by how radiologists leverage multiple viewing windows when evaluating CT images. Our proposed method, window shifting, randomly places the viewing windows around the region of interest during training. This approach improves liver lesion segmentation performance and robustness on images with poorly timed contrast agent. Our method outperforms classical intensity augmentations as well as the intensity augmentation pipeline of the popular nn-UNet on multiple datasets.
* 6 pages, 3 figures, accepted to MLSP 2023
On the Effects of Self-supervision and Contrastive Alignment in Deep Multi-view Clustering
Mar 17, 2023



Self-supervised learning is a central component in recent approaches to deep multi-view clustering (MVC). However, we find large variations in the development of self-supervision-based methods for deep MVC, potentially slowing the progress of the field. To address this, we present DeepMVC, a unified framework for deep MVC that includes many recent methods as instances. We leverage our framework to make key observations about the effect of self-supervision, and in particular, drawbacks of aligning representations with contrastive learning. Further, we prove that contrastive alignment can negatively influence cluster separability, and that this effect becomes worse when the number of views increases. Motivated by our findings, we develop several new DeepMVC instances with new forms of self-supervision. We conduct extensive experiments and find that (i) in line with our theoretical findings, contrastive alignments decreases performance on datasets with many views; (ii) all methods benefit from some form of self-supervision; and (iii) our new instances outperform previous methods on several datasets. Based on our results, we suggest several promising directions for future research. To enhance the openness of the field, we provide an open-source implementation of DeepMVC, including recent models and our new instances. Our implementation includes a consistent evaluation protocol, facilitating fair and accurate evaluation of methods and components.
Hubs and Hyperspheres: Reducing Hubness and Improving Transductive Few-shot Learning with Hyperspherical Embeddings
Mar 16, 2023



Distance-based classification is frequently used in transductive few-shot learning (FSL). However, due to the high-dimensionality of image representations, FSL classifiers are prone to suffer from the hubness problem, where a few points (hubs) occur frequently in multiple nearest neighbour lists of other points. Hubness negatively impacts distance-based classification when hubs from one class appear often among the nearest neighbors of points from another class, degrading the classifier's performance. To address the hubness problem in FSL, we first prove that hubness can be eliminated by distributing representations uniformly on the hypersphere. We then propose two new approaches to embed representations on the hypersphere, which we prove optimize a tradeoff between uniformity and local similarity preservation -- reducing hubness while retaining class structure. Our experiments show that the proposed methods reduce hubness, and significantly improves transductive FSL accuracy for a wide range of classifiers.
The Conditional Cauchy-Schwarz Divergence with Applications to Time-Series Data and Sequential Decision Making
Jan 21, 2023The Cauchy-Schwarz (CS) divergence was developed by Pr\'{i}ncipe et al. in 2000. In this paper, we extend the classic CS divergence to quantify the closeness between two conditional distributions and show that the developed conditional CS divergence can be simply estimated by a kernel density estimator from given samples. We illustrate the advantages (e.g., the rigorous faithfulness guarantee, the lower computational complexity, the higher statistical power, and the much more flexibility in a wide range of applications) of our conditional CS divergence over previous proposals, such as the conditional KL divergence and the conditional maximum mean discrepancy. We also demonstrate the compelling performance of conditional CS divergence in two machine learning tasks related to time series data and sequential inference, namely the time series clustering and the uncertainty-guided exploration for sequential decision making.
ProtoVAE: A Trustworthy Self-Explainable Prototypical Variational Model
Oct 15, 2022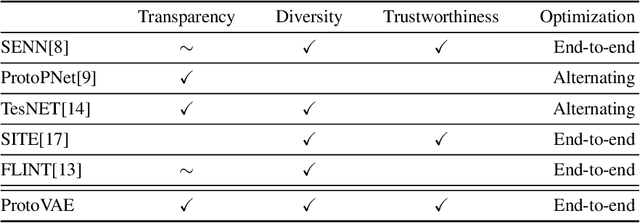
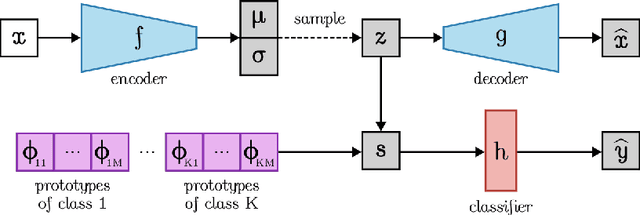
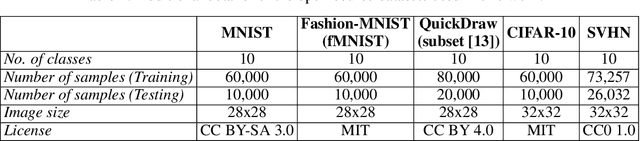
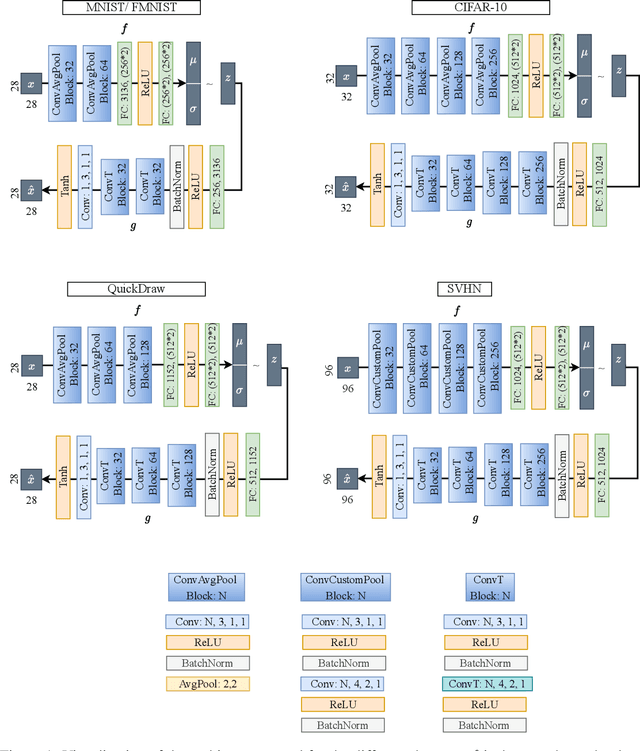
The need for interpretable models has fostered the development of self-explainable classifiers. Prior approaches are either based on multi-stage optimization schemes, impacting the predictive performance of the model, or produce explanations that are not transparent, trustworthy or do not capture the diversity of the data. To address these shortcomings, we propose ProtoVAE, a variational autoencoder-based framework that learns class-specific prototypes in an end-to-end manner and enforces trustworthiness and diversity by regularizing the representation space and introducing an orthonormality constraint. Finally, the model is designed to be transparent by directly incorporating the prototypes into the decision process. Extensive comparisons with previous self-explainable approaches demonstrate the superiority of ProtoVAE, highlighting its ability to generate trustworthy and diverse explanations, while not degrading predictive performance.
A clinically motivated self-supervised approach for content-based image retrieval of CT liver images
Jul 11, 2022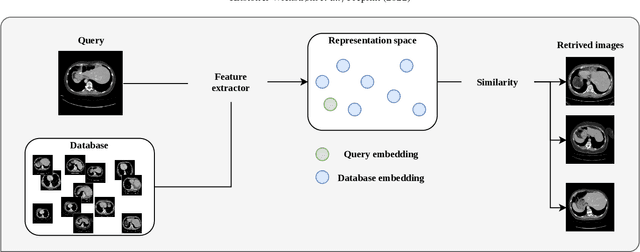
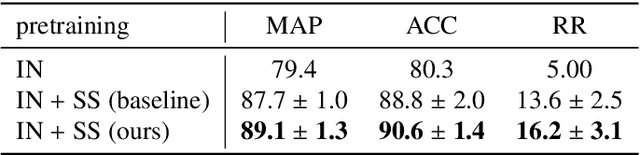
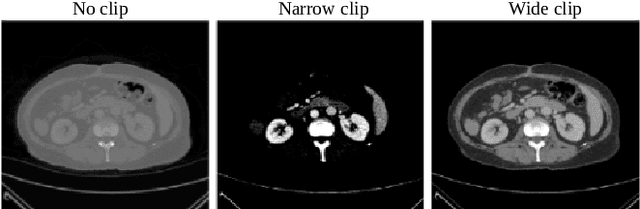
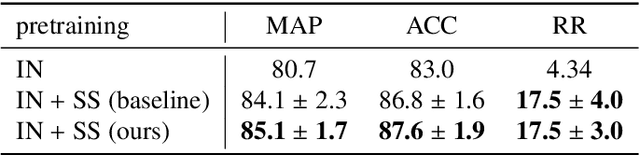
Deep learning-based approaches for content-based image retrieval (CBIR) of CT liver images is an active field of research, but suffers from some critical limitations. First, they are heavily reliant on labeled data, which can be challenging and costly to acquire. Second, they lack transparency and explainability, which limits the trustworthiness of deep CBIR systems. We address these limitations by (1) proposing a self-supervised learning framework that incorporates domain-knowledge into the training procedure and (2) providing the first representation learning explainability analysis in the context of CBIR of CT liver images. Results demonstrate improved performance compared to the standard self-supervised approach across several metrics, as well as improved generalisation across datasets. Further, we conduct the first representation learning explainability analysis in the context of CBIR, which reveals new insights into the feature extraction process. Lastly, we perform a case study with cross-examination CBIR that demonstrates the usability of our proposed framework. We believe that our proposed framework could play a vital role in creating trustworthy deep CBIR systems that can successfully take advantage of unlabeled data.
Principle of Relevant Information for Graph Sparsification
May 31, 2022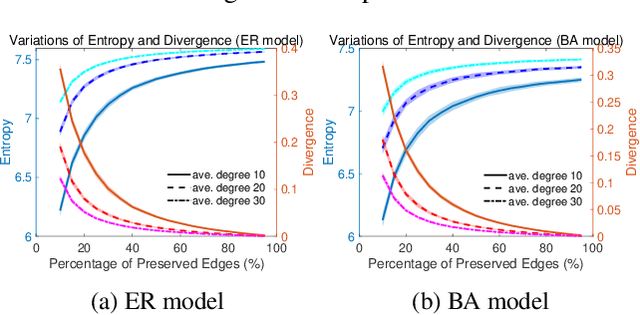
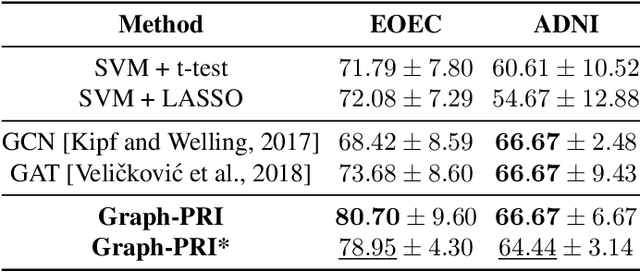
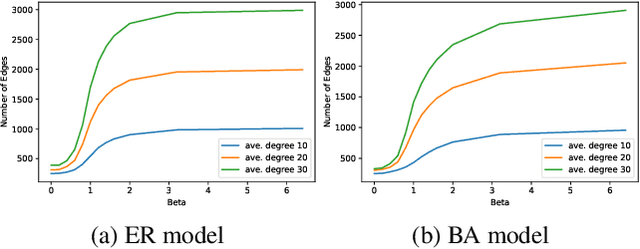

Graph sparsification aims to reduce the number of edges of a graph while maintaining its structural properties. In this paper, we propose the first general and effective information-theoretic formulation of graph sparsification, by taking inspiration from the Principle of Relevant Information (PRI). To this end, we extend the PRI from a standard scalar random variable setting to structured data (i.e., graphs). Our Graph-PRI objective is achieved by operating on the graph Laplacian, made possible by expressing the graph Laplacian of a subgraph in terms of a sparse edge selection vector $\mathbf{w}$. We provide both theoretical and empirical justifications on the validity of our Graph-PRI approach. We also analyze its analytical solutions in a few special cases. We finally present three representative real-world applications, namely graph sparsification, graph regularized multi-task learning, and medical imaging-derived brain network classification, to demonstrate the effectiveness, the versatility and the enhanced interpretability of our approach over prevalent sparsification techniques. Code of Graph-PRI is available at https://github.com/SJYuCNEL/PRI-Graphs
The Kernelized Taylor Diagram
May 18, 2022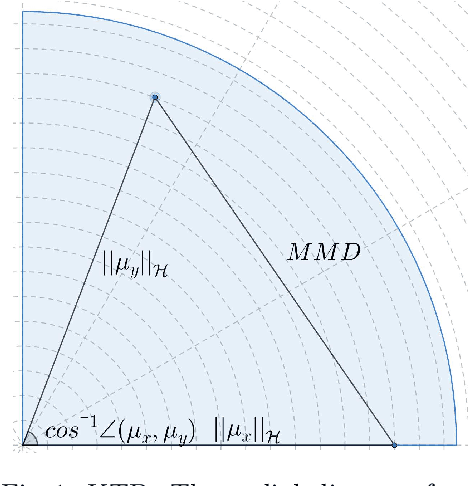
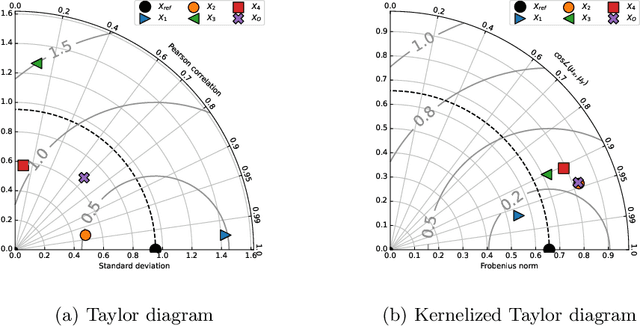
This paper presents the kernelized Taylor diagram, a graphical framework for visualizing similarities between data populations. The kernelized Taylor diagram builds on the widely used Taylor diagram, which is used to visualize similarities between populations. However, the Taylor diagram has several limitations such as not capturing non-linear relationships and sensitivity to outliers. To address such limitations, we propose the kernelized Taylor diagram. Our proposed kernelized Taylor diagram is capable of visualizing similarities between populations with minimal assumptions of the data distributions. The kernelized Taylor diagram relates the maximum mean discrepancy and the kernel mean embedding in a single diagram, a construction that, to the best of our knowledge, have not been devised prior to this work. We believe that the kernelized Taylor diagram can be a valuable tool in data visualization.
BrainIB: Interpretable Brain Network-based Psychiatric Diagnosis with Graph Information Bottleneck
May 07, 2022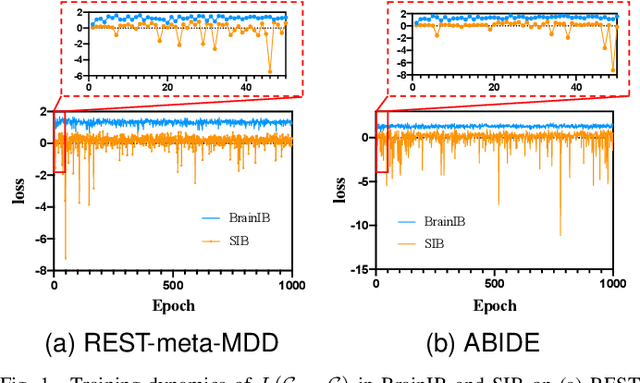
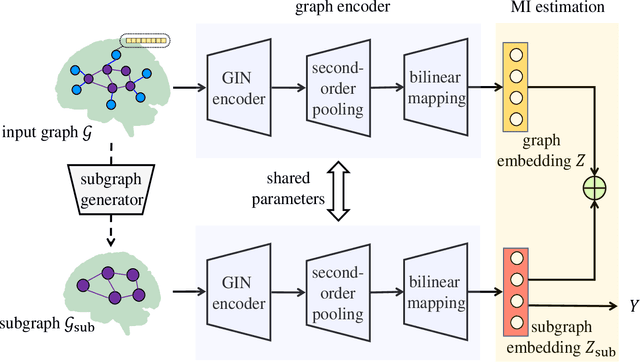

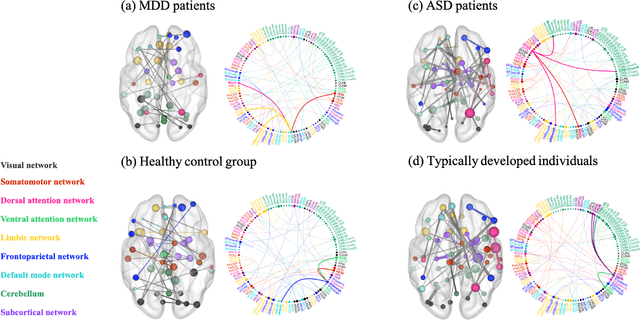
Developing a new diagnostic models based on the underlying biological mechanisms rather than subjective symptoms for psychiatric disorders is an emerging consensus. Recently, machine learning-based classifiers using functional connectivity (FC) for psychiatric disorders and healthy controls are developed to identify brain markers. However, existing machine learningbased diagnostic models are prone to over-fitting (due to insufficient training samples) and perform poorly in new test environment. Furthermore, it is difficult to obtain explainable and reliable brain biomarkers elucidating the underlying diagnostic decisions. These issues hinder their possible clinical applications. In this work, we propose BrainIB, a new graph neural network (GNN) framework to analyze functional magnetic resonance images (fMRI), by leveraging the famed Information Bottleneck (IB) principle. BrainIB is able to identify the most informative regions in the brain (i.e., subgraph) and generalizes well to unseen data. We evaluate the performance of BrainIB against 6 popular brain network classification methods on two multi-site, largescale datasets and observe that our BrainIB always achieves the highest diagnosis accuracy. It also discovers the subgraph biomarkers which are consistent to clinical and neuroimaging findings.