 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCT-GAN: Enhancing Table Synthesis via Fourier Transform
Oct 12, 2022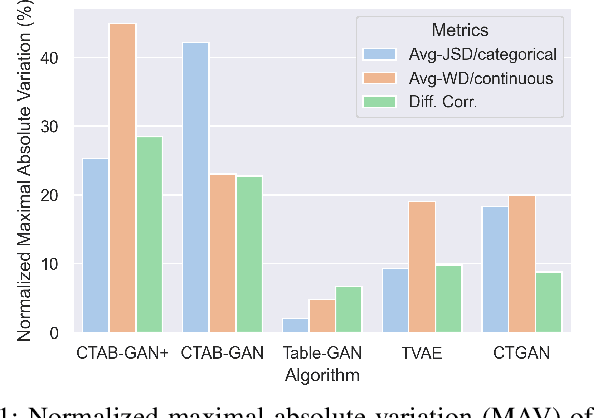
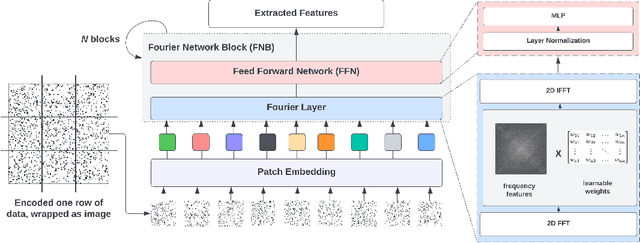
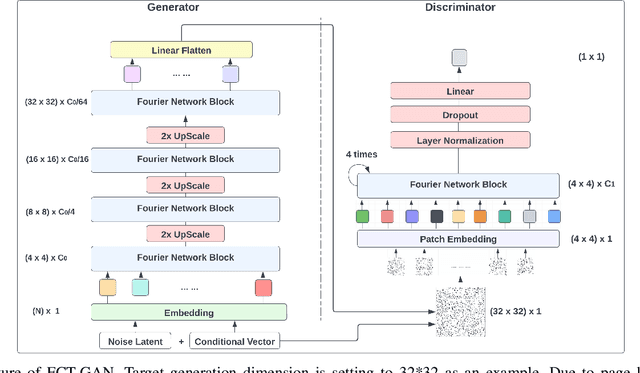
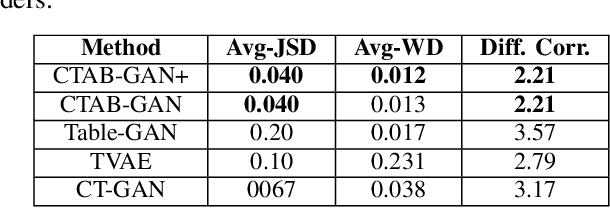
Synthetic tabular data emerges as an alternative for sharing knowledge while adhering to restrictive data access regulations, e.g., European General Data Protection Regulation (GDPR). Mainstream state-of-the-art tabular data synthesizers draw methodologies from Generative Adversarial Networks (GANs), which are composed of a generator and a discriminator. While convolution neural networks are shown to be a better architecture than fully connected networks for tabular data synthesizing, two key properties of tabular data are overlooked: (i) the global correlation across columns, and (ii) invariant synthesizing to column permutations of input data. To address the above problems, we propose a Fourier conditional tabular generative adversarial network (FCT-GAN). We introduce feature tokenization and Fourier networks to construct a transformer-style generator and discriminator, and capture both local and global dependencies across columns. The tokenizer captures local spatial features and transforms original data into tokens. Fourier networks transform tokens to frequency domains and element-wisely multiply a learnable filter. Extensive evaluation on benchmarks and real-world data shows that FCT-GAN can synthesize tabular data with high machine learning utility (up to 27.8% better than state-of-the-art baselines) and high statistical similarity to the original data (up to 26.5% better), while maintaining the global correlation across columns, especially on high dimensional dataset.
CTAB-GAN+: Enhancing Tabular Data Synthesis
Apr 01, 2022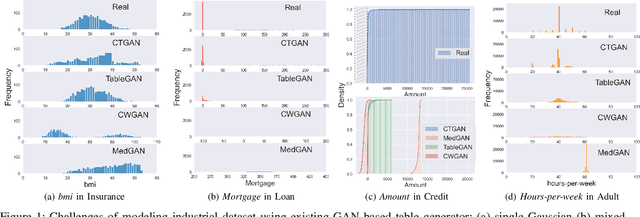
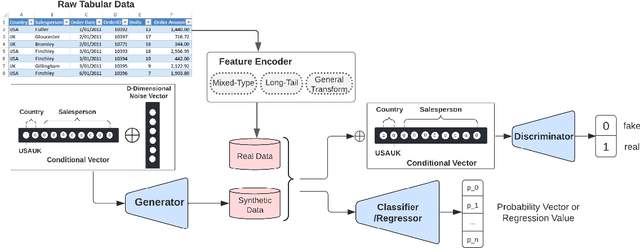
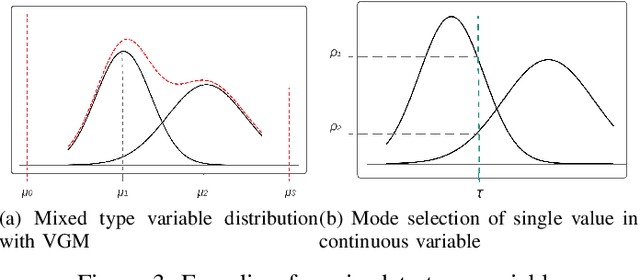
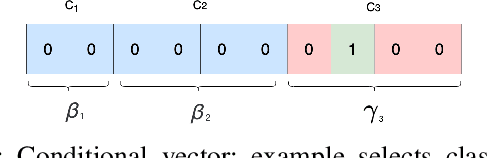
While data sharing is crucial for knowledge development, privacy concerns and strict regulation (e.g., European General Data Protection Regulation (GDPR)) limit its full effectiveness. Synthetic tabular data emerges as alternative to enable data sharing while fulfilling regulatory and privacy constraints. State-of-the-art tabular data synthesizers draw methodologies from Generative Adversarial Networks (GAN). As GANs improve the synthesized data increasingly resemble the real data risking to leak privacy. Differential privacy (DP) provides theoretical guarantees on privacy loss but degrades data utility. Striking the best trade-off remains yet a challenging research question. We propose CTAB-GAN+ a novel conditional tabular GAN. CTAB-GAN+ improves upon state-of-the-art by (i) adding downstream losses to conditional GANs for higher utility synthetic data in both classification and regression domains; (ii) using Wasserstein loss with gradient penalty for better training convergence; (iii) introducing novel encoders targeting mixed continuous-categorical variables and variables with unbalanced or skewed data; and (iv) training with DP stochastic gradient descent to impose strict privacy guarantees. We extensively evaluate CTAB-GAN+ on data similarity and analysis utility against state-of-the-art tabular GANs. The results show that CTAB-GAN+ synthesizes privacy-preserving data with at least 48.16% higher utility across multiple datasets and learning tasks under different privacy budgets.
Fed-TGAN: Federated Learning Framework for Synthesizing Tabular Data
Aug 18, 2021
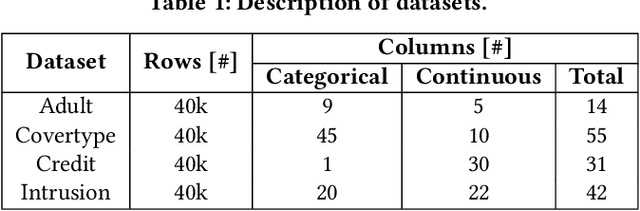
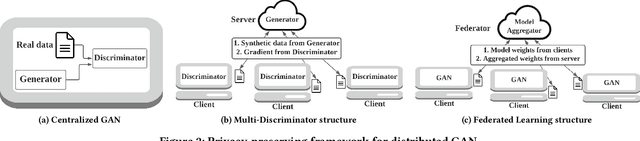
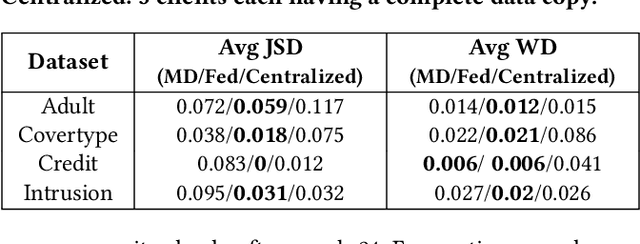
Generative Adversarial Networks (GANs) are typically trained to synthesize data, from images and more recently tabular data, under the assumption of directly accessible training data. Recently, federated learning (FL) is an emerging paradigm that features decentralized learning on client's local data with a privacy-preserving capability. And, while learning GANs to synthesize images on FL systems has just been demonstrated, it is unknown if GANs for tabular data can be learned from decentralized data sources. Moreover, it remains unclear which distributed architecture suits them best. Different from image GANs, state-of-the-art tabular GANs require prior knowledge on the data distribution of each (discrete and continuous) column to agree on a common encoding -- risking privacy guarantees. In this paper, we propose Fed-TGAN, the first Federated learning framework for Tabular GANs. To effectively learn a complex tabular GAN on non-identical participants, Fed-TGAN designs two novel features: (i) a privacy-preserving multi-source feature encoding for model initialization; and (ii) table similarity aware weighting strategies to aggregate local models for countering data skew. We extensively evaluate the proposed Fed-TGAN against variants of decentralized learning architectures on four widely used datasets. Results show that Fed-TGAN accelerates training time per epoch up to 200% compared to the alternative architectures, for both IID and Non-IID data. Overall, Fed-TGAN not only stabilizes the training loss, but also achieves better similarity between generated and original data.
Multi-Label Gold Asymmetric Loss Correction with Single-Label Regulators
Aug 04, 2021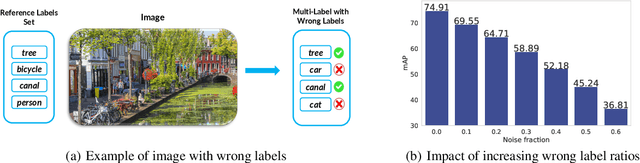
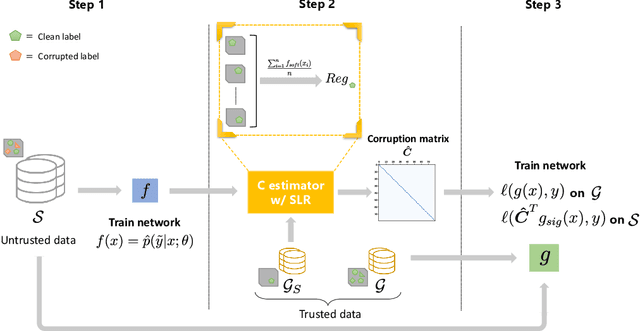
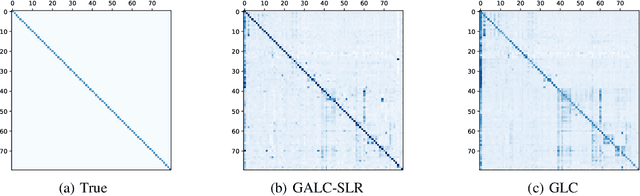
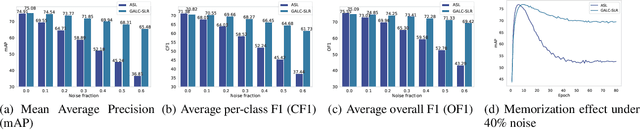
Multi-label learning is an emerging extension of the multi-class classification where an image contains multiple labels. Not only acquiring a clean and fully labeled dataset in multi-label learning is extremely expensive, but also many of the actual labels are corrupted or missing due to the automated or non-expert annotation techniques. Noisy label data decrease the prediction performance drastically. In this paper, we propose a novel Gold Asymmetric Loss Correction with Single-Label Regulators (GALC-SLR) that operates robust against noisy labels. GALC-SLR estimates the noise confusion matrix using single-label samples, then constructs an asymmetric loss correction via estimated confusion matrix to avoid overfitting to the noisy labels. Empirical results show that our method outperforms the state-of-the-art original asymmetric loss multi-label classifier under all corruption levels, showing mean average precision improvement up to 28.67% on a real world dataset of MS-COCO, yielding a better generalization of the unseen data and increased prediction performance.
DTGAN: Differential Private Training for Tabular GANs
Aug 02, 2021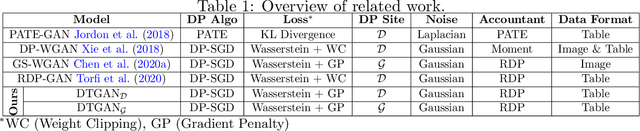
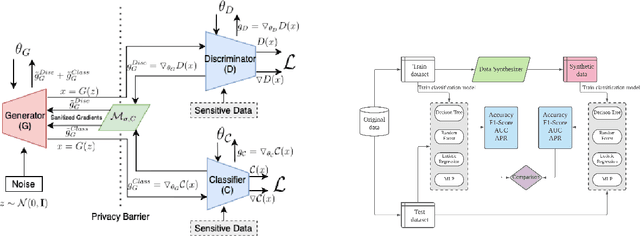

Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.
Enhancing Robustness of On-line Learning Models on Highly Noisy Data
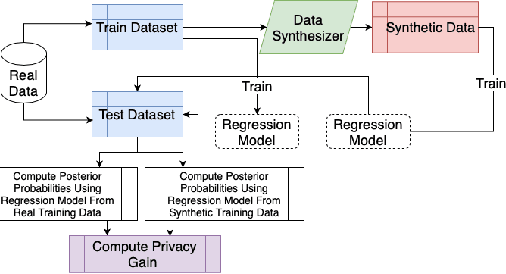
Mar 19, 2021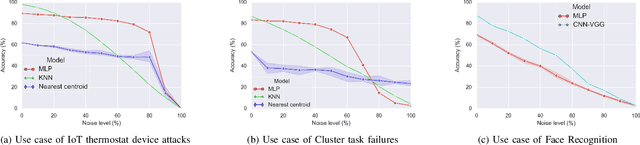
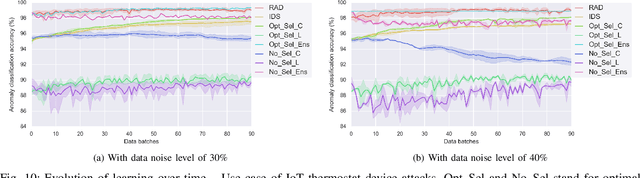
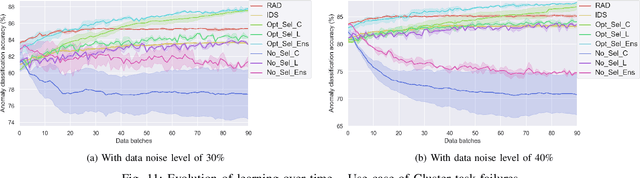
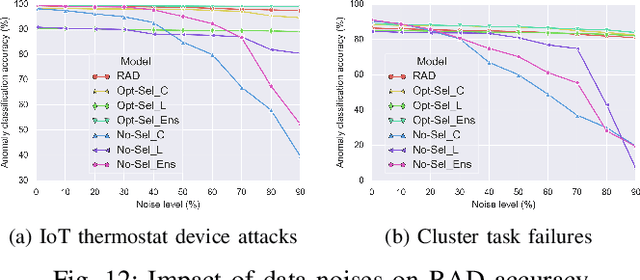
Classification algorithms have been widely adopted to detect anomalies for various systems, e.g., IoT, cloud and face recognition, under the common assumption that the data source is clean, i.e., features and labels are correctly set. However, data collected from the wild can be unreliable due to careless annotations or malicious data transformation for incorrect anomaly detection. In this paper, we extend a two-layer on-line data selection framework: Robust Anomaly Detector (RAD) with a newly designed ensemble prediction where both layers contribute to the final anomaly detection decision. To adapt to the on-line nature of anomaly detection, we consider additional features of conflicting opinions of classifiers, repetitive cleaning, and oracle knowledge. We on-line learn from incoming data streams and continuously cleanse the data, so as to adapt to the increasing learning capacity from the larger accumulated data set. Moreover, we explore the concept of oracle learning that provides additional information of true labels for difficult data points. We specifically focus on three use cases, (i) detecting 10 classes of IoT attacks, (ii) predicting 4 classes of task failures of big data jobs, and (iii) recognising 100 celebrities faces. Our evaluation results show that RAD can robustly improve the accuracy of anomaly detection, to reach up to 98.95% for IoT device attacks (i.e., +7%), up to 85.03% for cloud task failures (i.e., +14%) under 40% label noise, and for its extension, it can reach up to 77.51% for face recognition (i.e., +39%) under 30% label noise. The proposed RAD and its extensions are general and can be applied to different anomaly detection algorithms.
CTAB-GAN: Effective Table Data Synthesizing
Feb 16, 2021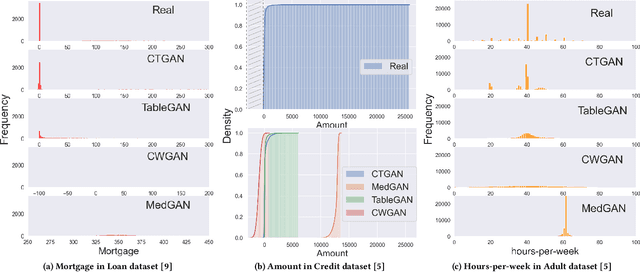
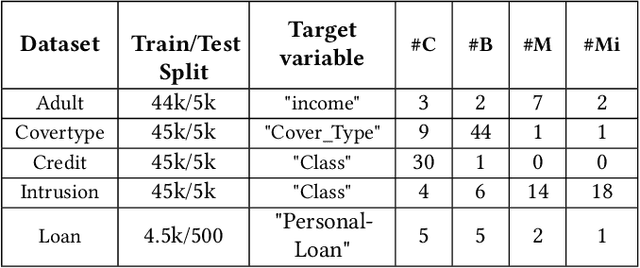
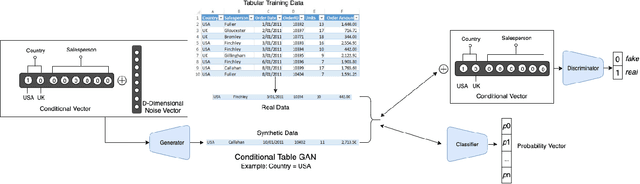
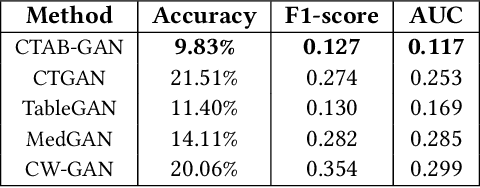
While data sharing is crucial for knowledge development, privacy concerns and strict regulation (e.g., European General Data Protection Regulation (GDPR)) unfortunately limit its full effectiveness. Synthetic tabular data emerges as an alternative to enable data sharing while fulfilling regulatory and privacy constraints. The state-of-the-art tabular data synthesizers draw methodologies from generative Adversarial Networks (GAN) and address two main data types in the industry, i.e., continuous and categorical. In this paper, we develop CTAB-GAN, a novel conditional table GAN architecture that can effectively model diverse data types, including a mix of continuous and categorical variables. Moreover, we address data imbalance and long-tail issues, i.e., certain variables have drastic frequency differences across large values. To achieve those aims, we first introduce the information loss and classification loss to the conditional GAN. Secondly, we design a novel conditional vector, which efficiently encodes the mixed data type and skewed distribution of data variable. We extensively evaluate CTAB-GAN with the state of the art GANs that generate synthetic tables, in terms of data similarity and analysis utility. The results on five datasets show that the synthetic data of CTAB-GAN remarkably resembles the real data for all three types of variables and results into higher accuracy for five machine learning algorithms, by up to 17%.
End-to-End Learning from Noisy Crowd to Supervised Machine Learning Models
Nov 13, 2020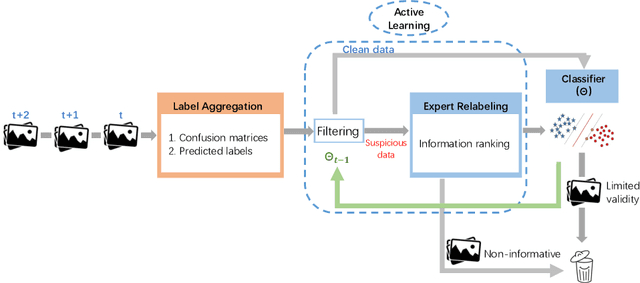
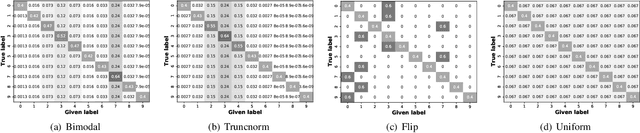
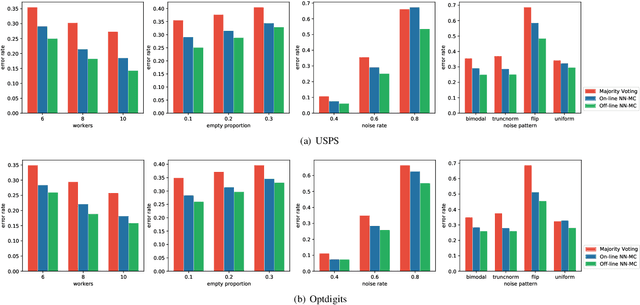
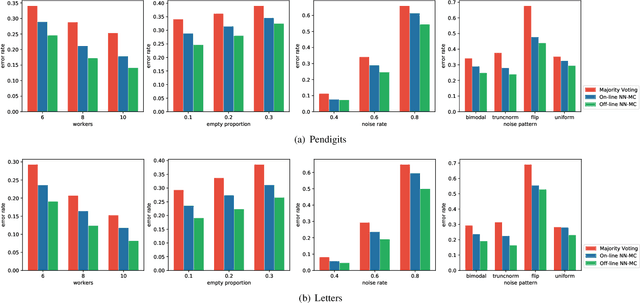
Labeling real-world datasets is time consuming but indispensable for supervised machine learning models. A common solution is to distribute the labeling task across a large number of non-expert workers via crowd-sourcing. Due to the varying background and experience of crowd workers, the obtained labels are highly prone to errors and even detrimental to the learning models. In this paper, we advocate using hybrid intelligence, i.e., combining deep models and human experts, to design an end-to-end learning framework from noisy crowd-sourced data, especially in an on-line scenario. We first summarize the state-of-the-art solutions that address the challenges of noisy labels from non-expert crowd and learn from multiple annotators. We show how label aggregation can benefit from estimating the annotators' confusion matrices to improve the learning process. Moreover, with the help of an expert labeler as well as classifiers, we cleanse aggregated labels of highly informative samples to enhance the final classification accuracy. We demonstrate the effectiveness of our strategies on several image datasets, i.e. UCI and CIFAR-10, using SVM and deep neural networks. Our evaluation shows that our on-line label aggregation with confusion matrix estimation reduces the error rate of labels by over 30%. Furthermore, relabeling only 10% of the data using the expert's results in over 90% classification accuracy with SVM.
TrustNet: Learning from Trusted Data Against (A)symmetric Label Noise
Jul 13, 2020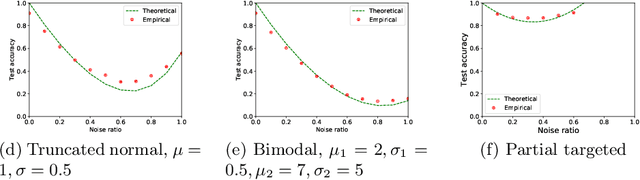
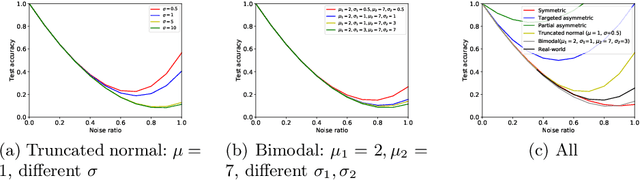

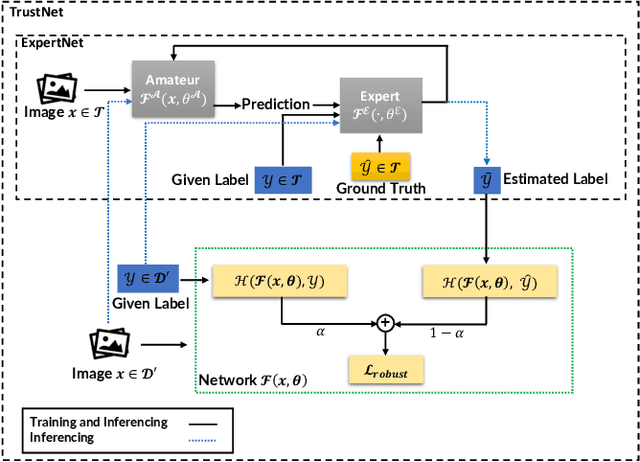
Robustness to label noise is a critical property for weakly-supervised classifiers trained on massive datasets. Robustness to label noise is a critical property for weakly-supervised classifiers trained on massive datasets. In this paper, we first derive analytical bound for any given noise patterns. Based on the insights, we design TrustNet that first adversely learns the pattern of noise corruption, being it both symmetric or asymmetric, from a small set of trusted data. Then, TrustNet is trained via a robust loss function, which weights the given labels against the inferred labels from the learned noise pattern. The weight is adjusted based on model uncertainty across training epochs. We evaluate TrustNet on synthetic label noise for CIFAR-10 and CIFAR-100, and real-world data with label noise, i.e., Clothing1M. We compare against state-of-the-art methods demonstrating the strong robustness of TrustNet under a diverse set of noise patterns.
ExpertNet: Adversarial Learning and Recovery Against Noisy Labels
Jul 13, 2020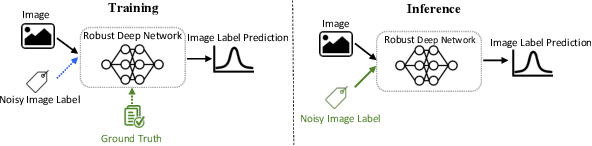
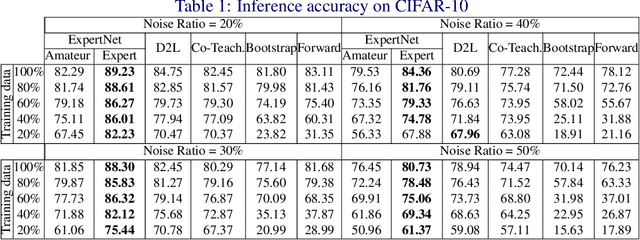
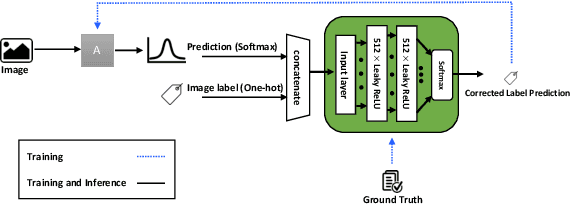
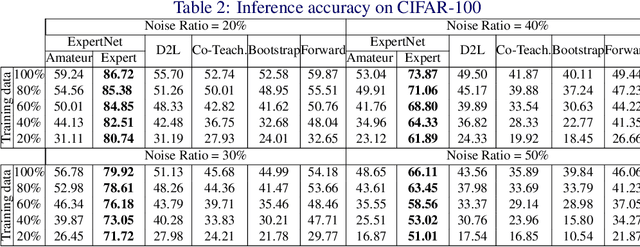
Today's available datasets in the wild, e.g., from social media and open platforms, present tremendous opportunities and challenges for deep learning, as there is a significant portion of tagged images, but often with noisy, i.e. erroneous, labels. Recent studies improve the robustness of deep models against noisy labels without the knowledge of true labels. In this paper, we advocate to derive a stronger classifier which proactively makes use of the noisy labels in addition to the original images - turning noisy labels into learning features. To such an end, we propose a novel framework, ExpertNet, composed of Amateur and Expert, which iteratively learn from each other. Amateur is a regular image classifier trained by the feedback of Expert, which imitates how human experts would correct the predicted labels from Amateur using the noise pattern learnt from the knowledge of both the noisy and ground truth labels. The trained Amateur and Expert proactively leverage the images and their noisy labels to infer image classes. Our empirical evaluations on noisy versions of CIFAR-10, CIFAR-100 and real-world data of Clothing1M show that the proposed model can achieve robust classification against a wide range of noise ratios and with as little as 20-50% training data, compared to state-of-the-art deep models that solely focus on distilling the impact of noisy labels.