 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly-Asynchronous Value Iteration: Making Value Iteration Asynchronous in Actions
Jul 04, 2022
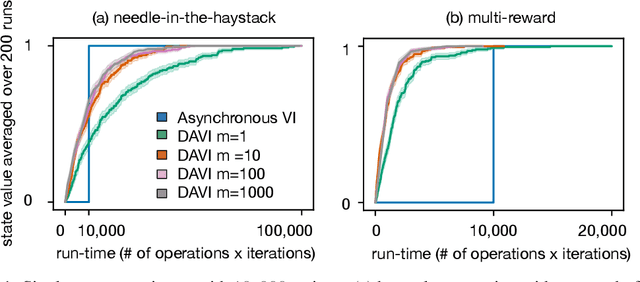
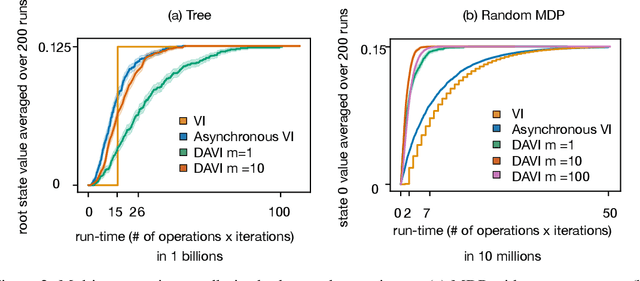
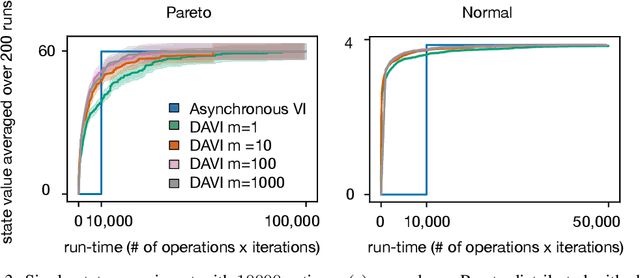
Value iteration (VI) is a foundational dynamic programming method, important for learning and planning in optimal control and reinforcement learning. VI proceeds in batches, where the update to the value of each state must be completed before the next batch of updates can begin. Completing a single batch is prohibitively expensive if the state space is large, rendering VI impractical for many applications. Asynchronous VI helps to address the large state space problem by updating one state at a time, in-place and in an arbitrary order. However, Asynchronous VI still requires a maximization over the entire action space, making it impractical for domains with large action space. To address this issue, we propose doubly-asynchronous value iteration (DAVI), a new algorithm that generalizes the idea of asynchrony from states to states and actions. More concretely, DAVI maximizes over a sampled subset of actions that can be of any user-defined size. This simple approach of using sampling to reduce computation maintains similarly appealing theoretical properties to VI without the need to wait for a full sweep through the entire action space in each update. In this paper, we show DAVI converges to the optimal value function with probability one, converges at a near-geometric rate with probability 1-delta, and returns a near-optimal policy in computation time that nearly matches a previously established bound for VI. We also empirically demonstrate DAVI's effectiveness in several experiments.
Toward Discovering Options that Achieve Faster Planning
May 25, 2022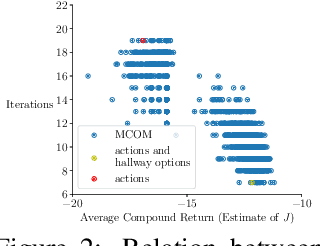
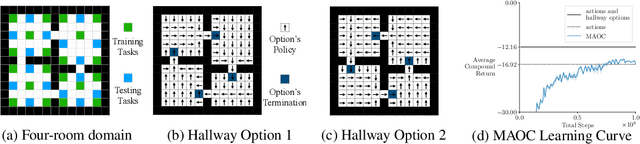
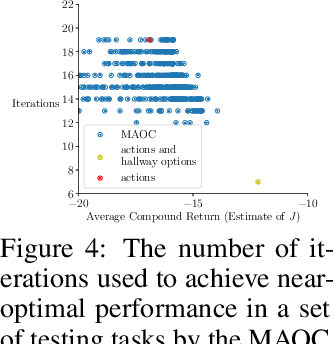
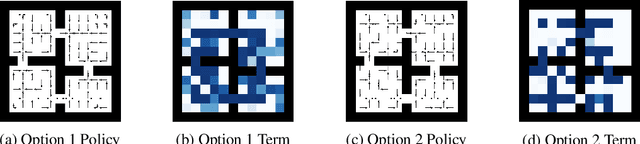
We propose a new objective for option discovery that emphasizes the computational advantage of using options in planning. For a given set of episodic tasks and a given number of options, the objective prefers options that can be used to achieve a high return by composing few options. By composing few options, fast planning can be achieved. When faced with new tasks similar to the given ones, the discovered options are also expected to accelerate planning. Our objective extends the objective proposed by Harb et al. (2018) for the single-task setting to the multi-task setting. A closer look at Harb et al.'s objective shows that the best options discovered given one task are not likely to be useful for future unseen tasks and that the multi-task setting is indeed necessary for this purpose. In the same paper, Harb et al. also proposed an algorithm to optimize their objective, and the algorithm can be naturally extended to the multi-task setting. We empirically show that in the four-room domain the extension does not achieve a high objective value and propose a new algorithm that better optimizes the proposed objective. In the same four-room domain, we show that 1) a higher objective value is typically associated with options with which fewer planning iterations are needed to achieve near-optimal performance, 2) our new algorithm achieves a high objective value, which is close to the value achieved by a set of human-designed options, 3) the best number of planning iterations given the discovered options is much smaller and matches it obtained given human-designed options, and 4) the options produced by our algorithm also make intuitive sense because they move to and terminate at cells near hallways connecting two neighbor rooms.
The Quest for a Common Model of the Intelligent Decision Maker
Apr 08, 2022The premise of the Multi-disciplinary Conference on Reinforcement Learning and Decision Making is that multiple disciplines share an interest in goal-directed decision making over time. The idea of this paper is to sharpen and deepen this premise by proposing a perspective on the decision maker that is substantive and widely held across psychology, artificial intelligence, economics, control theory, and neuroscience, which I call the "common model of the intelligent agent". The common model does not include anything specific to any organism, world, or application domain. The common model does include aspects of the decision maker's interaction with its world (there must be input and output, and a goal) and internal components of the decision maker (for perception, decision-making, internal evaluation, and a world model). I identify these aspects and components, note that they are given different names in different disciplines but refer essentially to the same ideas, and discuss the challenges and benefits of devising a neutral terminology that can be used across disciplines. It is time to recognize and build on the convergence of multiple diverse disciplines on a substantive common model of the intelligent agent.
A History of Meta-gradient: Gradient Methods for Meta-learning
Feb 20, 2022The history of meta-learning methods based on gradient descent is reviewed, focusing primarily on methods that adapt step-size (learning rate) meta-parameters.
Reward-Respecting Subtasks for Model-Based Reinforcement Learning
Feb 09, 2022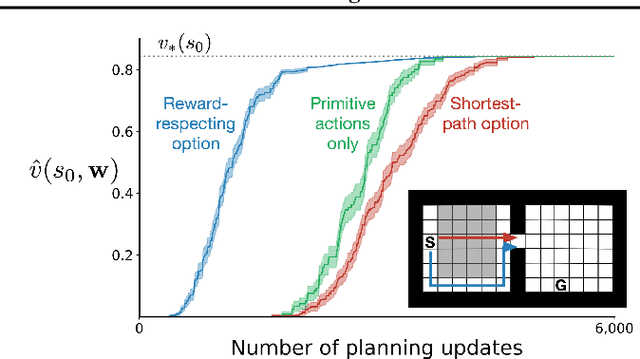
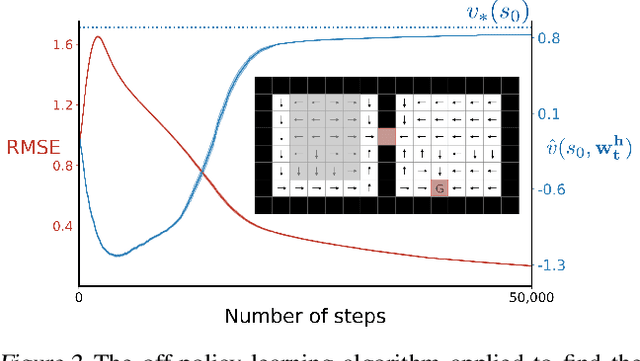
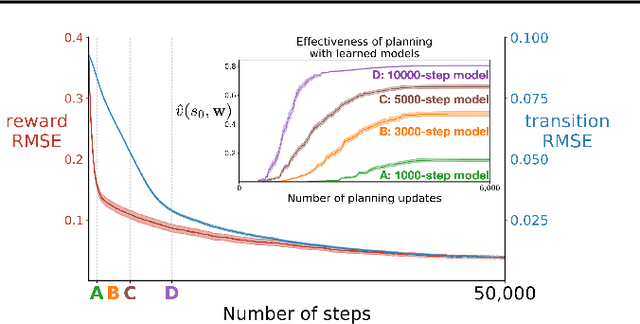
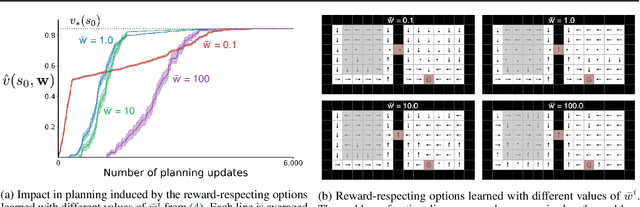
To achieve the ambitious goals of artificial intelligence, reinforcement learning must include planning with a model of the world that is abstract in state and time. Deep learning has made progress in state abstraction, but, although the theory of time abstraction has been extensively developed based on the options framework, in practice options have rarely been used in planning. One reason for this is that the space of possible options is immense and the methods previously proposed for option discovery do not take into account how the option models will be used in planning. Options are typically discovered by posing subsidiary tasks such as reaching a bottleneck state, or maximizing a sensory signal other than the reward. Each subtask is solved to produce an option, and then a model of the option is learned and made available to the planning process. The subtasks proposed in most previous work ignore the reward on the original problem, whereas we propose subtasks that use the original reward plus a bonus based on a feature of the state at the time the option stops. We show that options and option models obtained from such reward-respecting subtasks are much more likely to be useful in planning and can be learned online and off-policy using existing learning algorithms. Reward respecting subtasks strongly constrain the space of options and thereby also provide a partial solution to the problem of option discovery. Finally, we show how the algorithms for learning values, policies, options, and models can be unified using general value functions.
Learning Agent State Online with Recurrent Generate-and-Test
Dec 30, 2021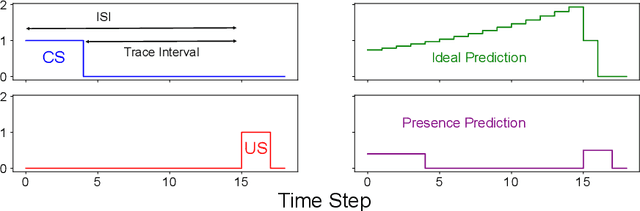
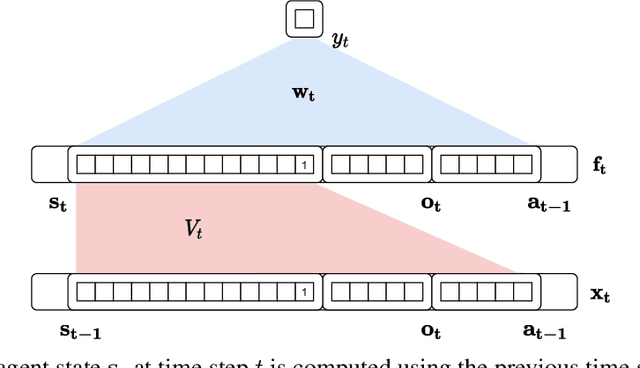
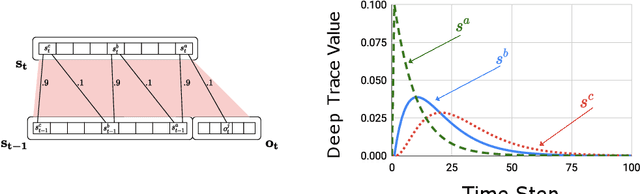
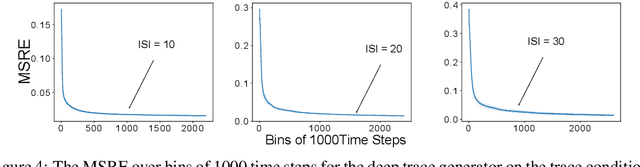
Learning continually and online from a continuous stream of data is challenging, especially for a reinforcement learning agent with sequential data. When the environment only provides observations giving partial information about the state of the environment, the agent must learn the agent state based on the data stream of experience. We refer to the state learned directly from the data stream of experience as the agent state. Recurrent neural networks can learn the agent state, but the training methods are computationally expensive and sensitive to the hyper-parameters, making them unideal for online learning. This work introduces methods based on the generate-and-test approach to learn the agent state. A generate-and-test algorithm searches for state features by generating features and testing their usefulness. In this process, features useful for the agent's performance on the task are preserved, and the least useful features get replaced with newly generated features. We study the effectiveness of our methods on two online multi-step prediction problems. The first problem, trace conditioning, focuses on the agent's ability to remember a cue for a prediction multiple steps into the future. In the second problem, trace patterning, the agent needs to learn patterns in the observation signals and remember them for future predictions. We show that our proposed methods can effectively learn the agent state online and produce accurate predictions.
Average-Reward Learning and Planning with Options
Oct 26, 2021
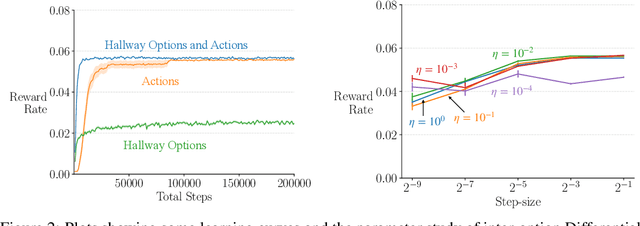
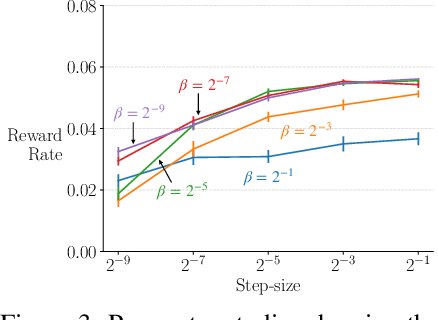
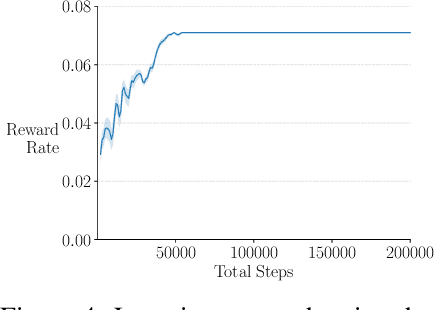
We extend the options framework for temporal abstraction in reinforcement learning from discounted Markov decision processes (MDPs) to average-reward MDPs. Our contributions include general convergent off-policy inter-option learning algorithms, intra-option algorithms for learning values and models, as well as sample-based planning variants of our learning algorithms. Our algorithms and convergence proofs extend those recently developed by Wan, Naik, and Sutton. We also extend the notion of option-interrupting behavior from the discounted to the average-reward formulation. We show the efficacy of the proposed algorithms with experiments on a continuing version of the Four-Room domain.
An Empirical Comparison of Off-policy Prediction Learning Algorithms in the Four Rooms Environment
Sep 10, 2021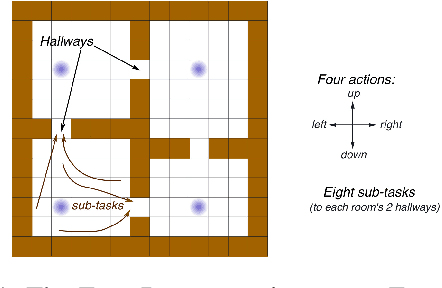
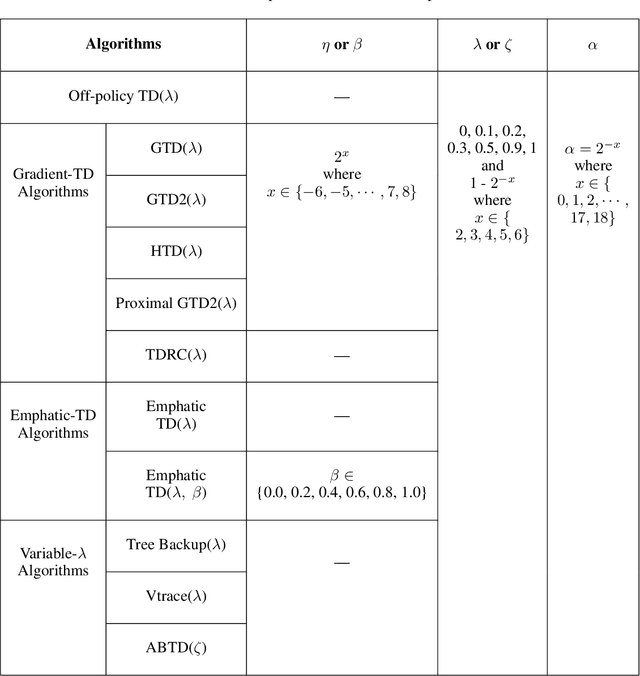
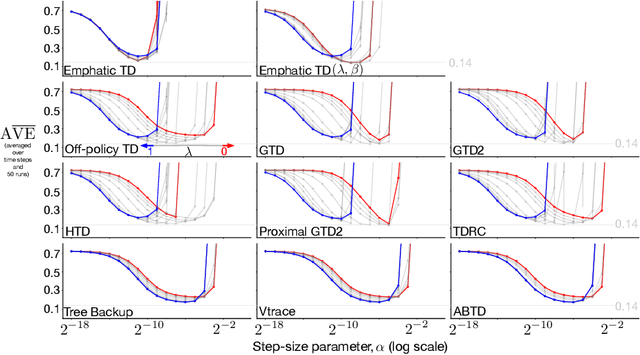
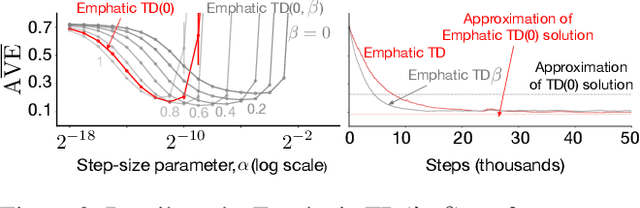
Many off-policy prediction learning algorithms have been proposed in the past decade, but it remains unclear which algorithms learn faster than others. We empirically compare 11 off-policy prediction learning algorithms with linear function approximation on two small tasks: the Rooms task, and the High Variance Rooms task. The tasks are designed such that learning fast in them is challenging. In the Rooms task, the product of importance sampling ratios can be as large as $2^{14}$ and can sometimes be two. To control the high variance caused by the product of the importance sampling ratios, step size should be set small, which in turn slows down learning. The High Variance Rooms task is more extreme in that the product of the ratios can become as large as $2^{14}\times 25$. This paper builds upon the empirical study of off-policy prediction learning algorithms by Ghiassian and Sutton (2021). We consider the same set of algorithms as theirs and employ the same experimental methodology. The algorithms considered are: Off-policy TD($\lambda$), five Gradient-TD algorithms, two Emphatic-TD algorithms, Tree Backup($\lambda$), Vtrace($\lambda$), and ABTD($\zeta$). We found that the algorithms' performance is highly affected by the variance induced by the importance sampling ratios. The data shows that Tree Backup($\lambda$), Vtrace($\lambda$), and ABTD($\zeta$) are not affected by the high variance as much as other algorithms but they restrict the effective bootstrapping parameter in a way that is too limiting for tasks where high variance is not present. We observed that Emphatic TD($\lambda$) tends to have lower asymptotic error than other algorithms, but might learn more slowly in some cases. We suggest algorithms for practitioners based on their problem of interest, and suggest approaches that can be applied to specific algorithms that might result in substantially improved algorithms.
Continual Backprop: Stochastic Gradient Descent with Persistent Randomness
Aug 13, 2021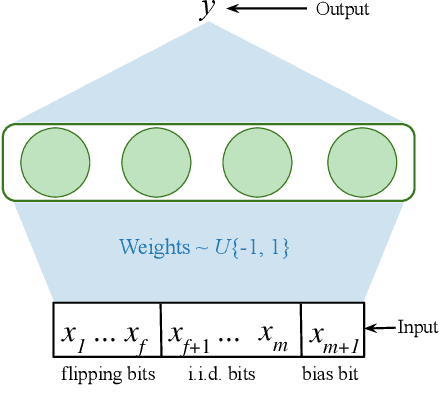
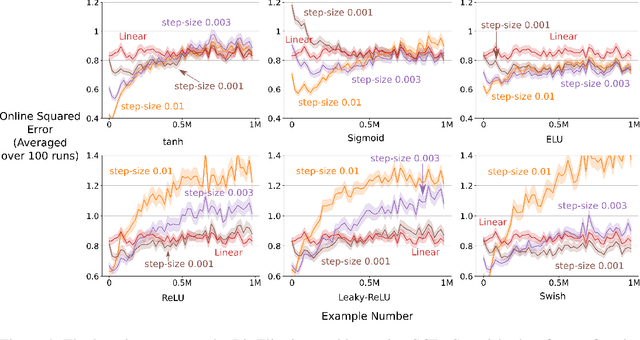
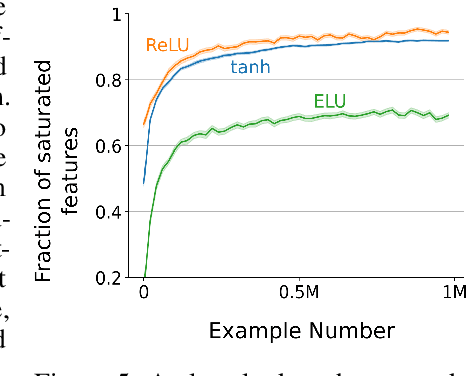
The Backprop algorithm for learning in neural networks utilizes two mechanisms: first, stochastic gradient descent and second, initialization with small random weights, where the latter is essential to the effectiveness of the former. We show that in continual learning setups, Backprop performs well initially, but over time its performance degrades. Stochastic gradient descent alone is insufficient to learn continually; the initial randomness enables only initial learning but not continual learning. To the best of our knowledge, ours is the first result showing this degradation in Backprop's ability to learn. To address this issue, we propose an algorithm that continually injects random features alongside gradient descent using a new generate-and-test process. We call this the Continual Backprop algorithm. We show that, unlike Backprop, Continual Backprop is able to continually adapt in both supervised and reinforcement learning problems. We expect that as continual learning becomes more common in future applications, a method like Continual Backprop will be essential where the advantages of random initialization are present throughout learning.
An Empirical Comparison of Off-policy Prediction Learning Algorithms on the Collision Task
Jun 11, 2021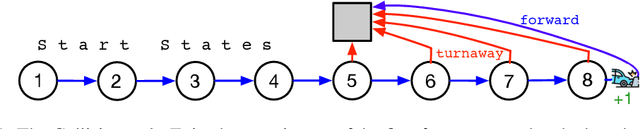

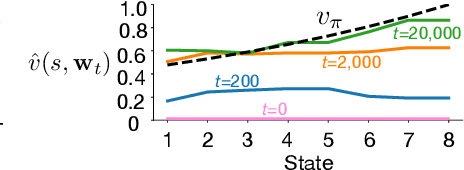
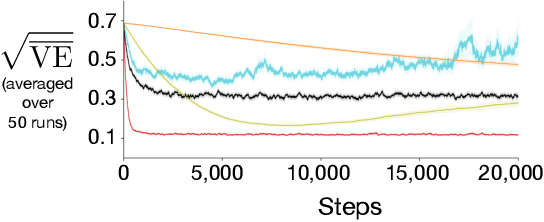
Off-policy prediction -- learning the value function for one policy from data generated while following another policy -- is one of the most challenging subproblems in reinforcement learning. This paper presents empirical results with eleven prominent off-policy learning algorithms that use linear function approximation: five Gradient-TD methods, two Emphatic-TD methods, Off-policy TD($\lambda$), Vtrace, and versions of Tree Backup and ABQ modified to apply to a prediction setting. Our experiments used the Collision task, a small idealized off-policy problem analogous to that of an autonomous car trying to predict whether it will collide with an obstacle. We assessed the performance of the algorithms according to their learning rate, asymptotic error level, and sensitivity to step-size and bootstrapping parameters. By these measures, the eleven algorithms can be partially ordered on the Collision task. In the top tier, the two Emphatic-TD algorithms learned the fastest, reached the lowest errors, and were robust to parameter settings. In the middle tier, the five Gradient-TD algorithms and Off-policy TD($\lambda$) were more sensitive to the bootstrapping parameter. The bottom tier comprised Vtrace, Tree Backup, and ABQ; these algorithms were no faster and had higher asymptotic error than the others. Our results are definitive for this task, though of course experiments with more tasks are needed before an overall assessment of the algorithms' merits can be made.