 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Compression Speeds Up Credit Assignment in Reinforcement Learning
May 06, 2024



Temporal credit assignment in reinforcement learning is challenging due to delayed and stochastic outcomes. Monte Carlo targets can bridge long delays between action and consequence but lead to high-variance targets due to stochasticity. Temporal difference (TD) learning uses bootstrapping to overcome variance but introduces a bias that can only be corrected through many iterations. TD($\lambda$) provides a mechanism to navigate this bias-variance tradeoff smoothly. Appropriately selecting $\lambda$ can significantly improve performance. Here, we propose Chunked-TD, which uses predicted probabilities of transitions from a model for computing $\lambda$-return targets. Unlike other model-based solutions to credit assignment, Chunked-TD is less vulnerable to model inaccuracies. Our approach is motivated by the principle of history compression and 'chunks' trajectories for conventional TD learning. Chunking with learned world models compresses near-deterministic regions of the environment-policy interaction to speed up credit assignment while still bootstrapping when necessary. We propose algorithms that can be implemented online and show that they solve some problems much faster than conventional TD($\lambda$).
Iterative Option Discovery for Planning, by Planning
Oct 02, 2023



Discovering useful temporal abstractions, in the form of options, is widely thought to be key to applying reinforcement learning and planning to increasingly complex domains. Building on the empirical success of the Expert Iteration approach to policy learning used in AlphaZero, we propose Option Iteration, an analogous approach to option discovery. Rather than learning a single strong policy that is trained to match the search results everywhere, Option Iteration learns a set of option policies trained such that for each state encountered, at least one policy in the set matches the search results for some horizon into the future. Intuitively, this may be significantly easier as it allows the algorithm to hedge its bets compared to learning a single globally strong policy, which may have complex dependencies on the details of the current state. Having learned such a set of locally strong policies, we can use them to guide the search algorithm resulting in a virtuous cycle where better options lead to better search results which allows for training of better options. We demonstrate experimentally that planning using options learned with Option Iteration leads to a significant benefit in challenging planning environments compared to an analogous planning algorithm operating in the space of primitive actions and learning a single rollout policy with Expert Iteration.
The Benefits of Model-Based Generalization in Reinforcement Learning
Nov 04, 2022



Model-Based Reinforcement Learning (RL) is widely believed to have the potential to improve sample efficiency by allowing an agent to synthesize large amounts of imagined experience. Experience Replay (ER) can be considered a simple kind of model, which has proved extremely effective at improving the stability and efficiency of deep RL. In principle, a learned parametric model could improve on ER by generalizing from real experience to augment the dataset with additional plausible experience. However, owing to the many design choices involved in empirically successful algorithms, it can be very hard to establish where the benefits are actually coming from. Here, we provide theoretical and empirical insight into when, and how, we can expect data generated by a learned model to be useful. First, we provide a general theorem motivating how learning a model as an intermediate step can narrow down the set of possible value functions more than learning a value function directly from data using the Bellman equation. Second, we provide an illustrative example showing empirically how a similar effect occurs in a more concrete setting with neural network function approximation. Finally, we provide extensive experiments showing the benefit of model-based learning for online RL in environments with combinatorial complexity, but factored structure that allows a learned model to generalize. In these experiments, we take care to control for other factors in order to isolate, insofar as possible, the benefit of using experience generated by a learned model relative to ER alone.
Doubly-Asynchronous Value Iteration: Making Value Iteration Asynchronous in Actions
Jul 04, 2022
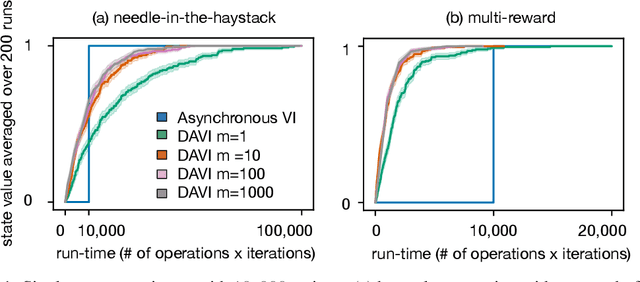
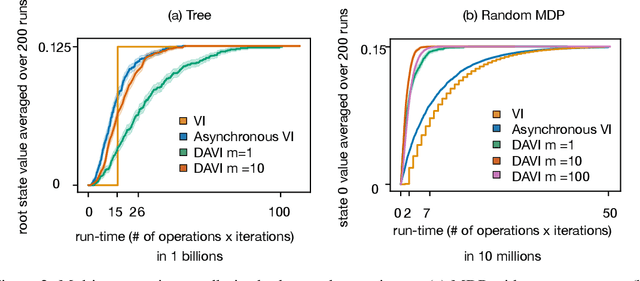
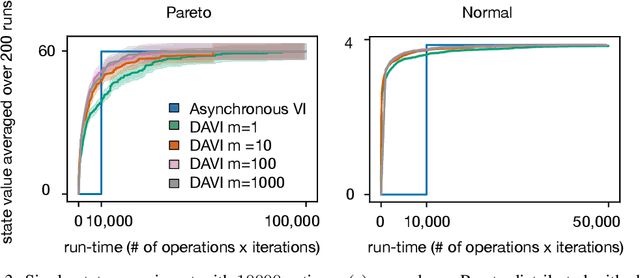
Value iteration (VI) is a foundational dynamic programming method, important for learning and planning in optimal control and reinforcement learning. VI proceeds in batches, where the update to the value of each state must be completed before the next batch of updates can begin. Completing a single batch is prohibitively expensive if the state space is large, rendering VI impractical for many applications. Asynchronous VI helps to address the large state space problem by updating one state at a time, in-place and in an arbitrary order. However, Asynchronous VI still requires a maximization over the entire action space, making it impractical for domains with large action space. To address this issue, we propose doubly-asynchronous value iteration (DAVI), a new algorithm that generalizes the idea of asynchrony from states to states and actions. More concretely, DAVI maximizes over a sampled subset of actions that can be of any user-defined size. This simple approach of using sampling to reduce computation maintains similarly appealing theoretical properties to VI without the need to wait for a full sweep through the entire action space in each update. In this paper, we show DAVI converges to the optimal value function with probability one, converges at a near-geometric rate with probability 1-delta, and returns a near-optimal policy in computation time that nearly matches a previously established bound for VI. We also empirically demonstrate DAVI's effectiveness in several experiments.
Hindsight Network Credit Assignment: Efficient Credit Assignment in Networks of Discrete Stochastic Units
Oct 14, 2021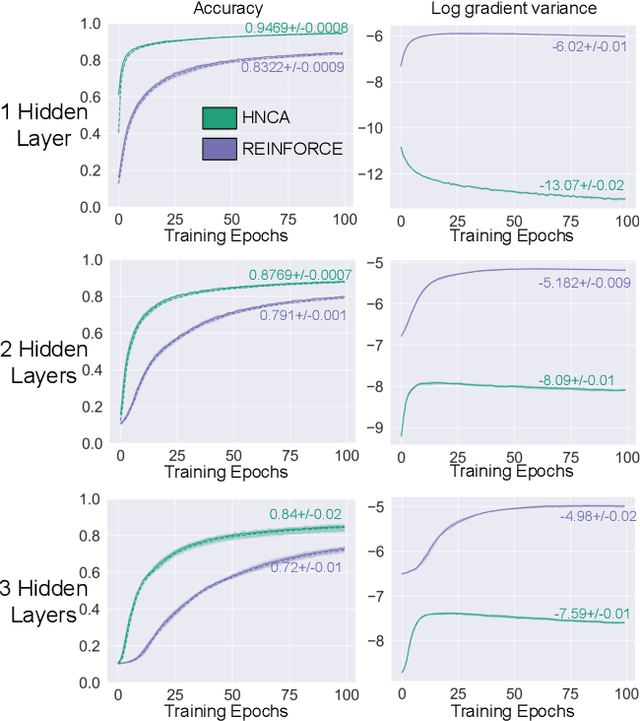
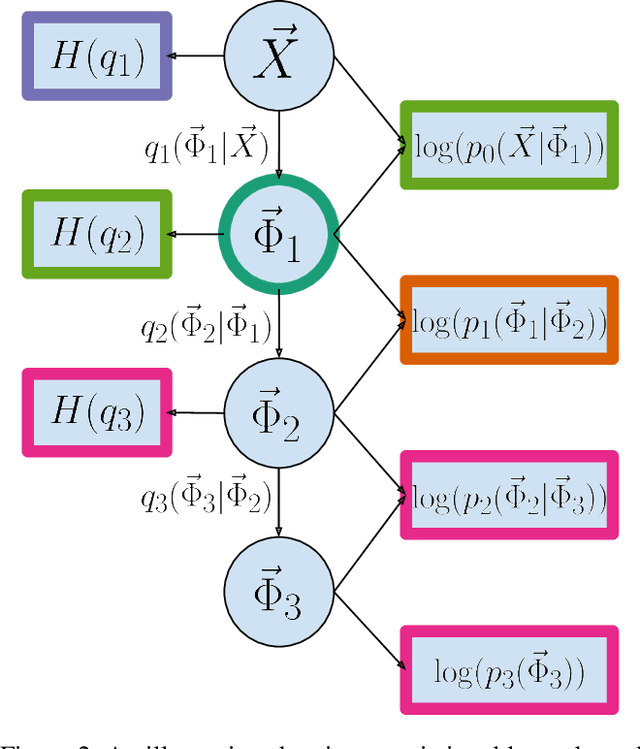
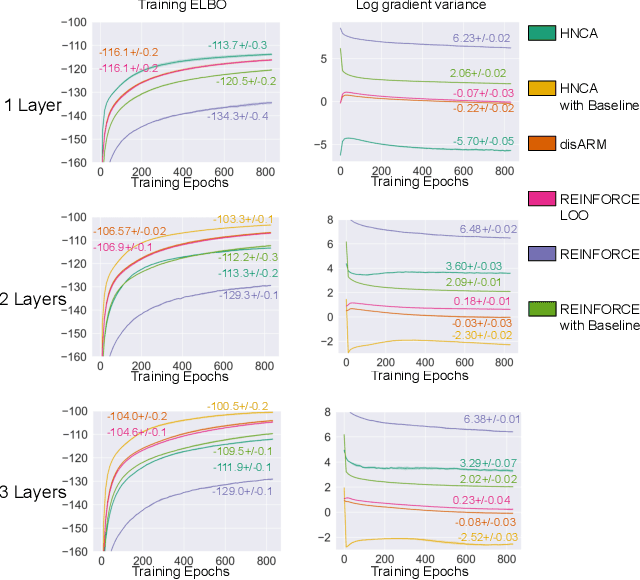
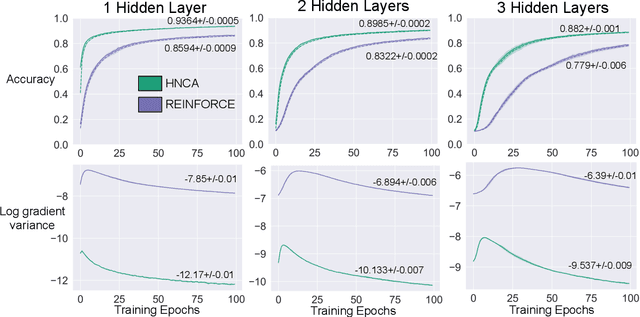
Training neural networks with discrete stochastic variables presents a unique challenge. Backpropagation is not directly applicable, nor are the reparameterization tricks used in networks with continuous stochastic variables. To address this challenge, we present Hindsight Network Credit Assignment (HNCA), a novel learning algorithm for networks of discrete stochastic units. HNCA works by assigning credit to each unit based on the degree to which its output influences its immediate children in the network. We prove that HNCA produces unbiased gradient estimates with reduced variance compared to the REINFORCE estimator, while the computational cost is similar to that of backpropagation. We first apply HNCA in a contextual bandit setting to optimize a reward function that is unknown to the agent. In this setting, we empirically demonstrate that HNCA significantly outperforms REINFORCE, indicating that the variance reduction implied by our theoretical analysis is significant and impactful. We then show how HNCA can be extended to optimize a more general function of the outputs of a network of stochastic units, where the function is known to the agent. We apply this extended version of HNCA to train a discrete variational auto-encoder and empirically show it compares favourably to other strong methods. We believe that the ideas underlying HNCA can help stimulate new ways of thinking about efficient credit assignment in stochastic compute graphs.
Hindsight Network Credit Assignment
Nov 24, 2020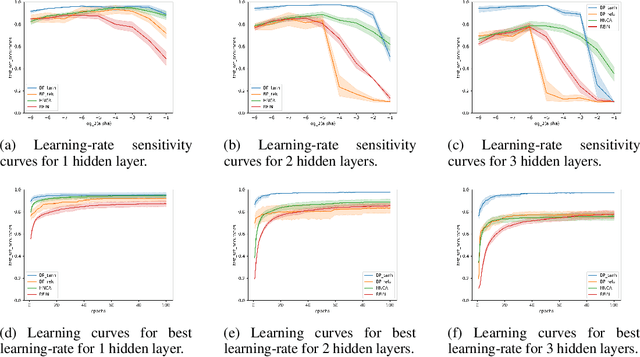
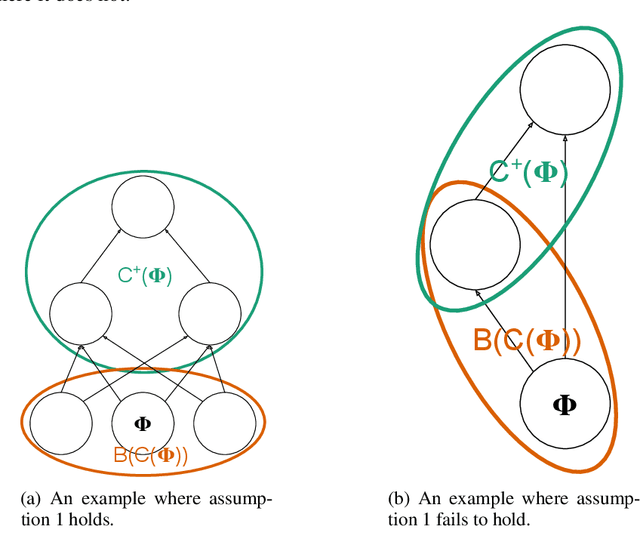
We present Hindsight Network Credit Assignment (HNCA), a novel learning method for stochastic neural networks, which works by assigning credit to each neuron's stochastic output based on how it influences the output of its immediate children in the network. We prove that HNCA provides unbiased gradient estimates while reducing variance compared to the REINFORCE estimator. We also experimentally demonstrate the advantage of HNCA over REINFORCE in a contextual bandit version of MNIST. The computational complexity of HNCA is similar to that of backpropagation. We believe that HNCA can help stimulate new ways of thinking about credit assignment in stochastic compute graphs.
Understanding the Pathologies of Approximate Policy Evaluation when Combined with Greedification in Reinforcement Learning
Oct 28, 2020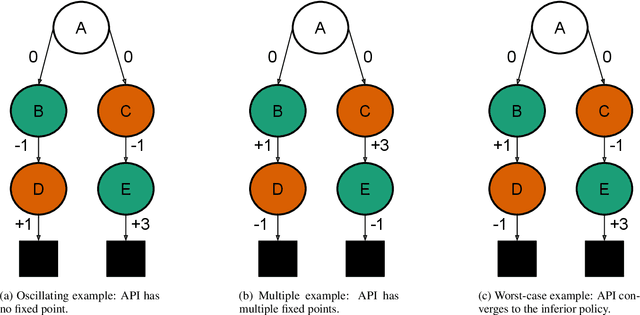
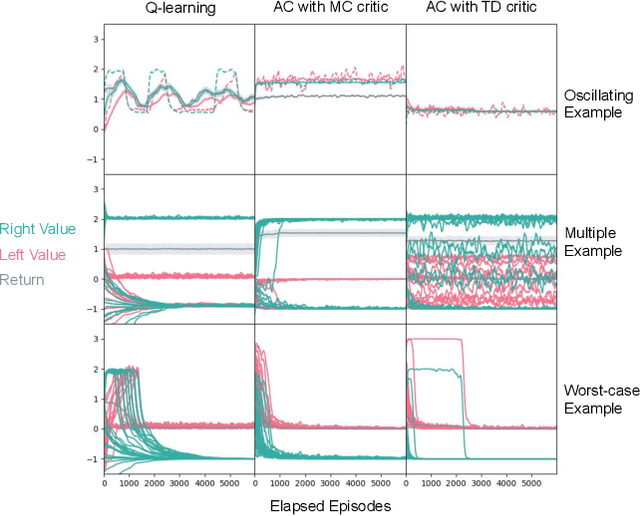
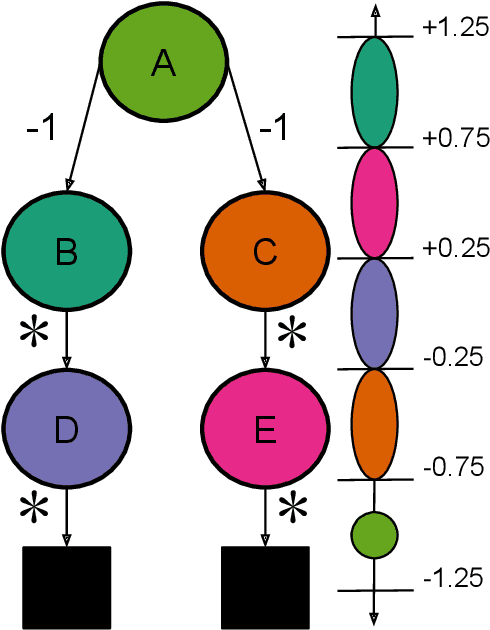
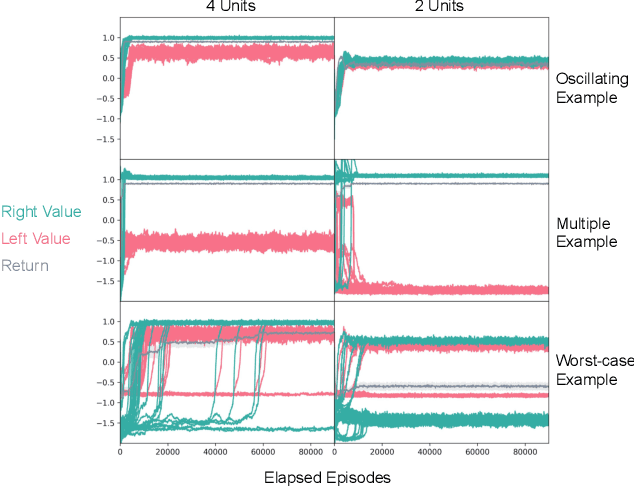
Despite empirical success, the theory of reinforcement learning (RL) with value function approximation remains fundamentally incomplete. Prior work has identified a variety of pathological behaviours that arise in RL algorithms that combine approximate on-policy evaluation and greedification. One prominent example is policy oscillation, wherein an algorithm may cycle indefinitely between policies, rather than converging to a fixed point. What is not well understood however is the quality of the policies in the region of oscillation. In this paper we present simple examples illustrating that in addition to policy oscillation and multiple fixed points -- the same basic issue can lead to convergence to the worst possible policy for a given approximation. Such behaviours can arise when algorithms optimize evaluation accuracy weighted by the distribution of states that occur under the current policy, but greedify based on the value of states which are rare or nonexistent under this distribution. This means the values used for greedification are unreliable and can steer the policy in undesirable directions. Our observation that this can lead to the worst possible policy shows that in a general sense such algorithms are unreliable. The existence of such examples helps to narrow the kind of theoretical guarantees that are possible and the kind of algorithmic ideas that are likely to be helpful. We demonstrate analytically and experimentally that such pathological behaviours can impact a wide range of RL and dynamic programming algorithms; such behaviours can arise both with and without bootstrapping, and with linear function approximation as well as with more complex parameterized functions like neural networks.
Variance Reduced Advantage Estimation with $δ$ Hindsight Credit Assignment
Jan 09, 2020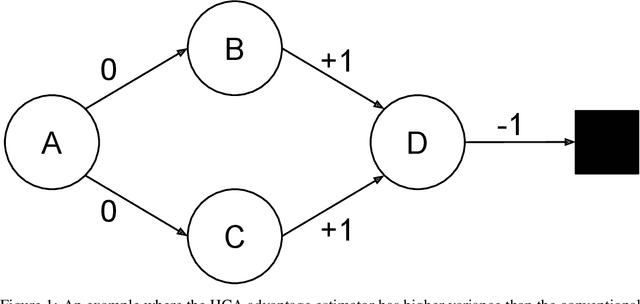
Hindsight Credit Assignment (HCA) refers to a recently proposed family of methods for producing more efficient credit assignment in reinforcement learning. These methods work by explicitly estimating the probability that certain actions were taken in the past given present information. Prior work has studied the properties of such methods and demonstrated their behaviour empirically. We extend this work by introducing a particular HCA algorithm which has provably lower variance than the conventional Monte-Carlo estimator when the necessary functions can be estimated exactly. This result provides a strong theoretical basis for how HCA could be broadly useful.
MinAtar: An Atari-inspired Testbed for More Efficient Reinforcement Learning Experiments
Mar 07, 2019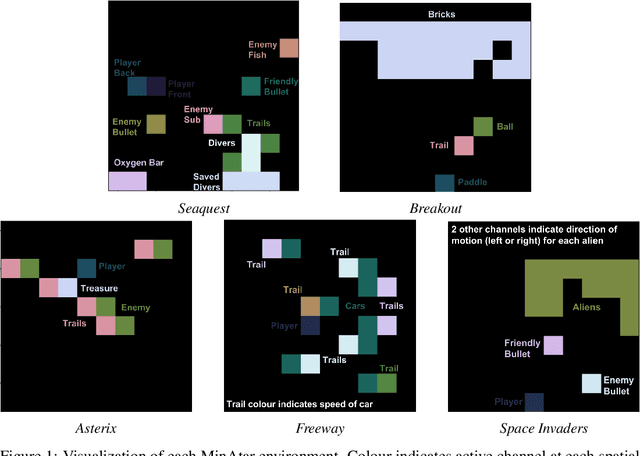
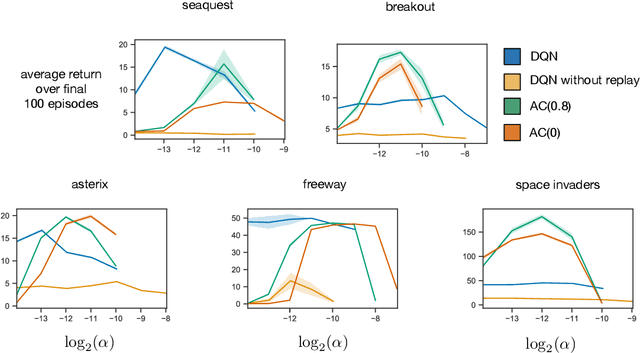
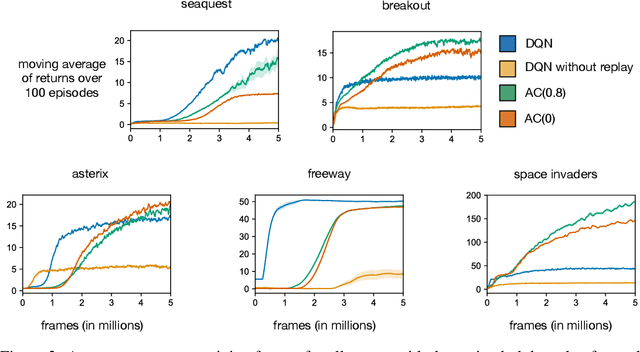
The Arcade Learning Environment (ALE) is a popular platform for evaluating reinforcement learning agents. Much of the appeal comes from the fact that Atari games are varied, showcase aspects of competency we expect from an intelligent agent, and are not biased towards any particular solution approach. The challenge of the ALE includes 1) the representation learning problem of extracting pertinent information from the raw pixels, and 2) the behavioural learning problem of leveraging complex, delayed associations between actions and rewards. Often, in reinforcement learning research, we care more about the latter, but the representation learning problem adds significant computational expense. In response, we introduce MinAtar, short for miniature Atari, a new evaluation platform that captures the general mechanics of specific Atari games, while simplifying certain aspects. In particular, we reduce the representational complexity to focus more on behavioural challenges. MinAtar consists of analogues to five Atari games which play out on a 10x10 grid. MinAtar provides a 10x10xn state representation. The n channels correspond to game-specific objects, such as ball, paddle and brick in the game Breakout. While significantly simplified, these domains are still rich enough to allow for interesting behaviours. To demonstrate the challenges posed by these domains, we evaluated a smaller version of the DQN architecture. We also tried variants of DQN without experience replay, and without a target network, to assess the impact of those two prominent components in the MinAtar environments. In addition, we evaluated a simpler agent that used actor-critic with eligibility traces, online updating, and no experience replay. We hope that by introducing a set of simplified, Atari-like games we can allow researchers to more efficiently investigate the unique behavioural challenges provided by the ALE.
Metatrace: Online Step-size Tuning by Meta-gradient Descent for Reinforcement Learning Control
May 10, 2018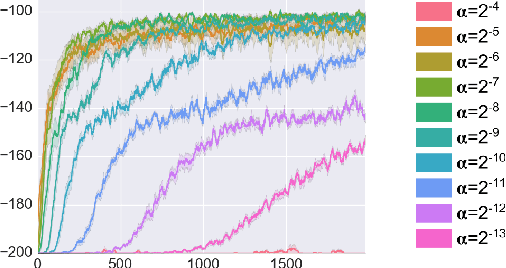
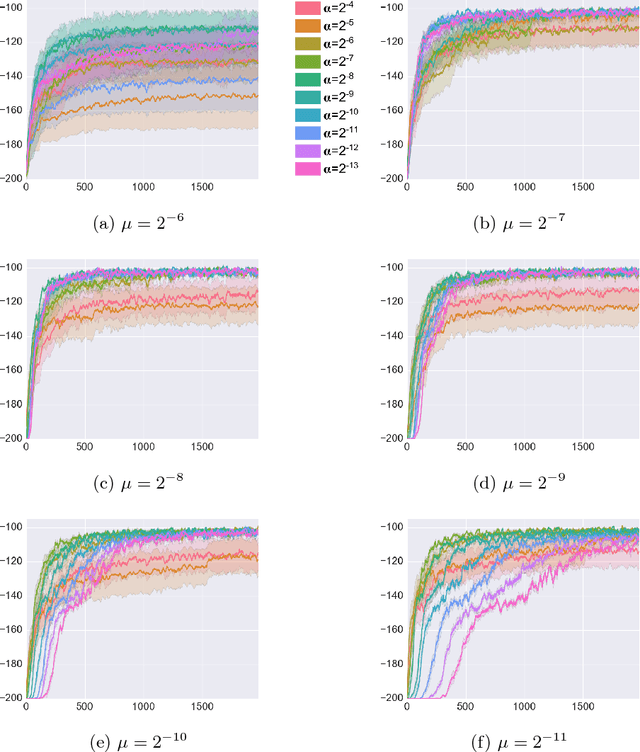
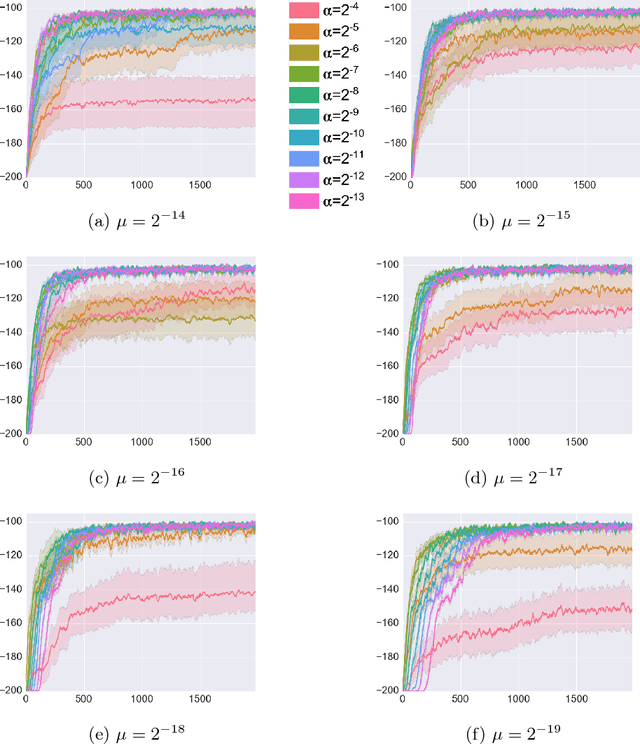
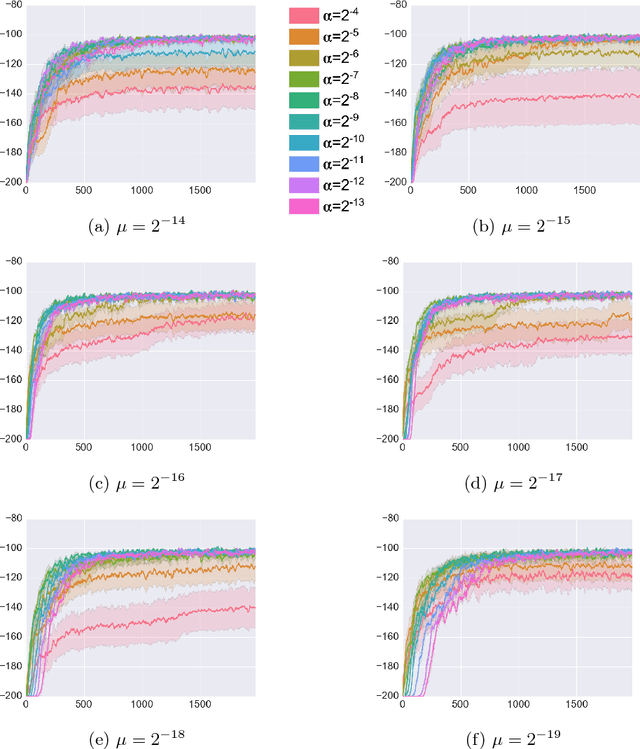
Reinforcement learning (RL) has had many successes in both "deep" and "shallow" settings. In both cases, significant hyperparameter tuning is often required to achieve good performance. Furthermore, when nonlinear function approximation is used, non-stationarity in the state representation can lead to learning instability. A variety of techniques exist to combat this --- most notably large experience replay buffers or the use of multiple parallel actors. These techniques come at the cost of moving away from the online RL problem as it is traditionally formulated (i.e., a single agent learning online without maintaining a large database of training examples). Meta-learning can potentially help with both these issues by tuning hyperparameters online and allowing the algorithm to more robustly adjust to non-stationarity in a problem. This paper applies meta-gradient descent to derive a set of step-size tuning algorithms specifically for online RL control with eligibility traces. Our novel technique, Metatrace, makes use of an eligibility trace analogous to methods like $TD(\lambda)$. We explore tuning both a single scalar step-size and a separate step-size for each learned parameter. We evaluate Metatrace first for control with linear function approximation in the classic mountain car problem and then in a noisy, non-stationary version. Finally, we apply Metatrace for control with nonlinear function approximation in 5 games in the Arcade Learning Environment where we explore how it impacts learning speed and robustness to initial step-size choice. Results show that the meta-step-size parameter of Metatrace is easy to set, Metatrace can speed learning, and Metatrace can allow an RL algorithm to deal with non-stationarity in the learning task.